1. Contact
Contact
To learn more about Intella Connect™, please contact us using the contact information below, or contact an Intella Channel Partner.
Vound
Office Phone
+1 888-291-7201
Email
sales@vound-software.com
Postal Address
10643 N Frank Lloyd Wright Blvd, Suite 101 Scottsdale, AZ 85259 U.S.A.
Sales Contacts
https://www.vound-software.com/about-us#partners
We will be pleased to provide additional information concerning Intella Connect and schedule a demonstration at your convenience.
To become an Intella Connect reseller, please contact us!
For user and technical support please visit our website: http://www.vound-software.com.
Vound Colorado (“Vound”).
© 2020 Vound. All rights reserved.
The information in this User Manual is subject to change without notice. Every effort has been made to ensure that the information in this manual is accurate. Vound is not responsible for printing or clerical errors.
VOUND PROVIDES THIS DOCUMENT “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED AND SHALL NOT BE LIABLE FOR TECHNICAL OR EDITORIAL ERRORS OR OMISSIONS CONTAINED HEREIN; NOR FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES RESULTING FROM THE FURNISHING, PERFORMANCE, OR USE OF THIS MATERIAL.
Other company and product names mentioned herein are trademarks of their respective companies. It is the responsibility of the user to comply with all applicable copyright laws. Mention of third-party products is for informational purposes only and constitutes neither an endorsement nor a recommendation. Vound assumes no responsibility with regard to the performance or use of these products. Under the copyright laws, this manual may not be copied, in whole or in part, without the written consent of Vound. Your rights to the software are governed by the accompanying software license agreement. The Vound logo is a trademark of Vound. Use of the Vound logo for commercial purposes without the prior written consent of Vound may constitute trademark infringement and unfair competition in violation of federal and state laws.
All rights reserved by Vound. Intella and Intella Connect are trademarks of Vound.
2. An introduction to Intella Connect
Intella Connect is a web-based investigation and eDiscovery tool. It is ideally suited for use by enterprise, law enforcement and regulatory agencies in civil, criminal or policy-related investigations. It allows you to share any case that has been made with Intella 100, Intella 250, Intella Professional (Pro) or Intella TEAM Manager. The case can then be reviewed using any of the supported web browsers.
Cases can also be created directly in Intella Connect and its sources can be indexed using Intella Node. If a case already exists, it is however not required to have Intella Node in order to share such case.
Intella Connect’s unique visual presentation will let you quickly and easily search and review email and electronically stored information to find critical evidence and visualize relevant relationships. The birds-eye view helps you gain insight in information that is available on combinations of keywords. In each step of your search it shows the number of emails or files that match your search (and of course a link to the e-mails and files themselves) so that you can effectively zoom in to find what you are looking for.
With Intella Connect, you can…
-
Gain deeper insight through visualizations.
-
Search email, attachments, archives, headers, and metadata.
-
Drill deeply into the data using Intella Connect’s unique facets.
-
Group and trace email conversations.
-
Preview, cull, and deduplicate email and data.
-
Export results.
2.1. Supported web browsers
-
Google Chrome (most recent version)
-
Mozilla Firefox (most recent version)
-
Microsoft Edge
-
Internet Explorer 11
|
As Microsoft has officially announced ending support for versions 8-10 of Internet Explorer on January 12th 2016, we decided to stop supporting them too. Starting with Intella Connect 2.4.0 versions prior to IE 11 will no longer be supported, redirecting users to a static page where an appropriate error message is shown. Version 11 will no longer be actively tested, however we intend to support it as long as all 3rd party software libraries that we are using will do that too. We may end support for it if we determine that potential problems cannot be easily fixed and are directly related to using this outdated browser. |
|
Warning
Google Chrome and MS Edge will not delete session cookies after they are closed. That means that logged in user will not be logged out. With this in mind it’s always best to log out manually when you finish using Intella Connect. |
2.2. Intella Connect Case sharing limitations
Case sharing is the ability to share across the network a set of evidence files that have been processed using Intella or Intella Connect into a case file. That case file is then shared and utilized by a number of assigned reviewers, paralegals, litigation support specialists or investigators using the Intella Connect case sharing feature.
The supported number of concurrently active cases that Intella Connect can share should be no more than four at any given time. The definition of an active case is one that is shared with a reviewer logged in or reviewing that case. A case that is shared but does not have any active reviewers logged in does not count towards the four cases. Connect administrators needing to have more than four active cases at any one time have two options:
-
They can purchase a second Intella Connect license and set up another dedicated server for it.
-
They can upgrade their current Intella Connect to Intella Connect Plus. Intella Connect Plus allows for ten active cases.
In addition, if a second Connect license and server is implemented, administrators can take advantage of the "Intella Connect Grid" feature to supply their reviewers with unified access to all cases shared by the servers forming the grid.
The supported number of concurrent reviewers per case is no more than eight.
Case Limits overview
| Product | # of Active Cases (Hardware Permitting) | # of Active Users (Hardware Permitting) | Viewers |
|---|---|---|---|
Intella Connect |
*up to 4 |
up to 8 per case |
n/a |
Intella Connect PLUS |
up to 10 |
up to 8 per case |
n/a |
Note about the performance
Numbers presented above were provided for Intella Connect server under a regular load. However, there may be situations where cases run more resource-demanding operations, such as:
-
Running Optical Character Recognition
-
Running Predictive Coding
-
Running Content Analysis
-
Exporting
-
Generating and pre-generating PDFs
All these operations require extensive CPU, memory and/or disk usage. Since all cases are shared by the same server it may happen that the excessive load they generate may limit the performance of simple review tasks on other cases. Therefore you should make sure to:
-
run any heavy tasks outside of normal review hours (usually overnight)
-
allocate enough hardware resources to meet the extra load
-
adjust your business flows so that multiple cases are not running complex operations on one server at the same time
2.3. System Requirements
Hardware
| Intella Node | Intella Connect | Intella Connect Plus | |
|---|---|---|---|
CPU |
8 cores |
8 cores |
16 cores |
RAM |
32GB |
32GB |
64GB |
Hard drives in the system |
1 for OS 1 for case 1 for evidence 1 for optimization |
1 for OS 1 for case 1 for evidence |
1 for OS 1 for case 1 for evidence |
The use of SSD disks can further enhance performance.
Software
| Intella Node | Intella Connect | Intella Connect Plus | |
|---|---|---|---|
Supported Operating Systems |
Windows 8.1, Windows 10, Windows Server 2012-2019 |
||
Exporting to PST |
(not applicable) |
Microsoft Outlook 2007 or later |
|
Processing Lotus Notes |
Lotus Notes 8.x, 9.x or 10.x |
(not applicable) |
|
|
Although our products can be installed on a number of Windows Server products such as Server 2012, 2016 and 2019, our products do not require a server operating system, and they run perfectly well on the listed desktop operating systems. For server installations, we only support our applications. We do not provide support for the server itself. Server security settings may need to be configured, and ports may need to be opened, for our products to operate on a server platform. These settings need to be addressed by your IT team to ensure that security of the system is maintained. |
We do not support our products when installed on an operating system deemed end of life by its manufacturer. For example, these would include platforms such as Windows Vista and Windows Server 2008.
2.4. Supported file formats
Content and metadata of the following file formats can be extracted:
-
Mail formats:
-
Microsoft Outlook PST/OST. Versions: 97, 98, 2000, 2002, 2003, 2007, 2010, 2013, 2016, 2019, 365.
-
Microsoft Outlook Express DBX, MBX. Versions: 4, 5 and 6.
-
Microsoft Outlook for Mac OLM and OLK15* files.
-
Microsoft Exchange EDB files. Versions: 2003, 2007, 2010, 2013, 2016.
-
IBM Notes NSF (formerly known as Lotus Notes or IBM Lotus Notes). Notes 8.5.x or higher needs to be installed on the computer performin the indexing to process the NSF files. All NSF files are supported that can be processed by the installed IBM Notes version.
-
Mbox (e.g. Thunderbird, Foxmail, Apple Mail)
-
Windows 10 Mail (POP accounts).
-
Saved emails (.eml, .msg)
-
Apple Mail (.emlx). Versions: 2 (Yosemite), 3 (El Capitan), 4 (Sierra), 5 (High Sierra) and 6 (Mojave). Testing concentrated mostly on versions 2, 5 and 6.
-
TNEF-encoded files (“winmail.dat” files).
-
Bloomberg XML dumps
-
-
Cellphone extraction formats:
-
Cellebrite UFED XML export or UFDR file.
-
Micro Systemation XRY XML and Extended XML exports
(Extended XML is strongly recommended) -
Oxygen Forensic Suite XML export.
-
iTunes backups. iOS versions 8, 9 and 10 backed up with iTunes 12. Other versions may work but have not been tested.
-
-
Disk image formats:
-
EnCase images (E01, Ex01, L01, Lx01 and S01 files)
-
FTK images (AD1 files), version 3 and 4
-
DMG. Supported compression formats: ADC, LZFSE, ZLIB, BZIP2. Supported compressed image formats: UDCO, UDZO, UDBZ, UDCo. Supported uncompressed image formats: RdWr, Rdxx, UDRO.
-
DD images
-
MacQuisition images (RAW, .00001 files)
-
ISO images (ISO 9660 and UDF formats)
-
VMware images (VMDK files). Supported types are RAW (flat), COWD version 1 (sparse) and VMDK version 1, 2 and 3 (sparse). Not supported are images that use a physical storage device.
-
VHD disk images. Supported type is VHD version 1.
-
BitLocker-encrypted volumes.
-
Volume shadow copies.
-
-
Document formats:
-
MS Office: Word, Excel, PowerPoint, Visio, Publisher, OneNote,
both old (e.g., .doc) and new (.docx) formats, up to MS Office 2019 and MS Office 365.
MS OneNote 2007 is not supported. -
OpenOffice: both OpenDocument and legacy OpenOffice/StarOffice formats
-
Hangul word processor (.hwp files)
-
Corel Office: WordPerfect, Quattro, Presentations
-
MS Works
-
Plain text
-
HTML
-
RTF
-
PDF (incl. entered form data)
-
XPS
-
-
Archives:
-
Zip. Supported compression methods: deflate, deflate64, bzip2, lzma and ppmd.
-
7-Zip. Supported compression methods: lzma, lzma2, bzip2 and ppmd.
-
Gzip
-
Bzip2
-
ZipX
-
Tar
-
Rar
-
RPM Package Manager (RPM)
-
Cpio
-
ARJ
-
Cabinet (CAB)
-
DEB
-
XZ
-
-
Web-browser artifacts:
-
Google Chrome: history, keyword search, typed URLs, cookies, form history, bookmarks, logins, downloads
-
Mozilla Firefox: history, keyword search, typed URLs, cookies, form history, bookmarks, downloads
-
Microsoft Internet Explorer (6-11): history, keyword search, typed URLs, cookies (partial support)
-
Microsoft Edge: history, keyword search, typed URLs
-
Apple Safari: history, bookmarks
-
-
Search Warrant Results:
-
Hotmail (uses a HTML-based collection of files)
-
Gmail and Yahoo (uses an Mbox variant)
-
-
Instant Messaging
-
Skype SQLite databases, versions 7.x (stable), 8.x, 11.x, 12.x and 14.x.
-
Slack exports. Both channel exports and user exports are supported.
-
IBM Notes Sametime chats
-
Pidgin account stores
-
Note that cellphone extraction reports typically also contain instant messaging fragments that may be picked up during indexing.
-
-
Databases
-
SQLite databases, version 3.
Note that Skype SQLite databases get processed differently. -
Mac OS property lists (.plist and .bplist files), in ASCII, XML or binary form.
-
-
Cryptocurrency (detection only):
-
Bitcoin wallets and blockchains
-
Dogecoin wallets and blockchains
-
Litecoin wallets and blockchains
-
Multibit Classic wallets and blockchains
-
Multibit HD wallets and blockchains
-
-
Miscellaneous formats:
-
iCal
-
vCard
-
XML
-
URL files (Internet shortcuts)
-
IBM Notes deletion stubs
-
The following registry and system artifacts are extracted:
-
System:
-
Installed operating systems. Windows 7, 8 and 10 have been tested.
-
User accounts.
-
User sessions: logon and logoff dates.
-
Windows event log entries. Supported Windows versions: 7, 8.1 and 10.
-
-
Programs:
-
Installed programs.
-
Startup programs.
-
Launched programs extracted from User Assist, BAM (Background Activity Moderator), RecentApps registry keys, and Prefetch files.
-
-
Devices:
-
USB devices.
-
USB device activity extracted from Windows Event Log (connect and disconnect events).
-
Network interfaces.
-
Network profiles including Wi-Fi network names.
-
-
Files and folders:
-
Recently accessed folders (Shell Bags).
-
Recently accessed files (LNK, Jump Lists and RecentApps registry key).
-
Files and folders deleted to the Recycle Bin.
-
The following types of encrypted files and items can be decrypted, if the required access keys (passwords, certificates, ID files) are provided in the Key Store:
-
PST/OST
-
NSF (*)
-
PDF
-
DOC
-
XLS
-
PPT
-
OpenXML (.docx, .xlsx, .pptx)
-
PDF
-
ZIP
-
RAR
-
7-Zip
-
S-MIME-encrypted emails
-
PGP-encrypted emails
-
BitLocker volumes (**)
-
APFS file systems
(*) Encrypted fields of NSF items are only decrypted if the NSF as a whole is encrypted too.
(**) Only BitLocker images using a password, recovery key or recovery file are supported. Other methods, such as smart cards or TPM, are not supported.
Supported image formats:
| Format | Type Identification | Metadata Extraction | Preview & Export to PDF | OCR |
|---|---|---|---|---|
Adobe Photoshop (PSD) |
● |
● |
● |
|
Apple Icon (ICNS) |
● |
● |
||
Apple PICT |
● |
● |
||
BMP |
● |
● |
● |
● |
DjVu |
● |
● |
||
Gif |
● |
● |
● |
● |
HEIF/HEIC |
● |
● |
||
Icon (ICO) |
● |
● |
● |
|
Interleaved Bitmap (IFF) |
● |
● |
||
JBIG2 |
● |
● |
● |
|
JPEG |
● |
● |
● |
● |
JPEG-2000 (JP2) |
● |
● |
● |
|
PCX/DCX (DCX not tested) |
● |
● |
● |
● |
PNG |
● |
● |
● |
● |
Radiance HDR |
● |
● |
||
SVG |
● |
● |
||
TIFF |
● |
● |
● |
● |
WebP |
● |
● |
||
WMF / EMF (partial) |
● |
● |
When indexing plain text file formats, essentially all character encodings supported by the Java 8 platform. This relates to regular text files and to email bodies encoded in plain text format. See https://docs.oracle.com/en/java/javase/11/intl/supported-encodings.html for a complete listing.
When the encoding is not specified, the application will try to heuristically determine the encoding. The following encodings are then supported:
-
UTF-7
-
UTF-8
-
UTF-16BE
-
UTF-16LE
-
UTF-32BE
-
UTF-32LE
-
Shift_JIS Japanese
-
ISO-2022-JP Japanese
-
ISO-2022-CN Simplified Chinese
-
ISO-2022-KR Korean
-
GB18030 Chinese
-
Big5 Traditional Chinese
-
EUC-JP Japanese
-
EUC-KR Korean
-
ISO-8859-1 Danish, Dutch, English, French, German, Italian, Norwegian, Portuguese, Swedish
-
ISO-8859-2 Czech, Hungarian, Polish, Romanian
-
ISO-8859-5 Russian
-
ISO-8859-6 Arabic
-
ISO-8859-7 Greek
-
ISO-8859-8 Hebrew
-
ISO-8859-9 Turkish
-
windows-1250 Czech, Hungarian, Polish, Romanian
-
windows-1251 Russian
-
windows-1252 Danish, Dutch, English, French, German, Italian, Norwegian, Portuguese, Swedish
-
windows-1253 Greek
-
windows-1254 Turkish
-
windows-1255 Hebrew
-
windows-1256 Arabic
-
KOI8-R Russian
-
IBM420 Arabic
-
IBM424 Hebrew
Several file formats are processed by applying heuristic string extraction algorithms, rather than proper parsing and interpretation of the binary contents of the file. This is due to a lack of proper libraries for interpreting these file formats. Experiments with these heuristic algorithms have shown that their output is still useful for indexing and full-text search. It typically will produce a lot of extra gibberish data, visible in the Previewer, and there is no guarantee that the extracted text is complete and correct. The affected formats are:
-
Corel Office: WordPerfect, Quattro, Presentations
-
Harvard Graphics Presentation
-
Microsoft Project
-
Microsoft Publisher
-
Microsoft Works
-
StarOffice
2.5. Supported sources
File or Folder
Files on local and network file systems can be indexed. Please check the list of supported file formats. The use of external and network drives is not supported, both for stability and performance reasons.
Load files
Load files stored in Concordance, Relativity, and CSV format can be indexed.
Hotmail Search Warrant Result
The mail packages delivered by Microsoft when responding to a search warrant can be indexed.
Disk images
Several disk image file formats can be indexed, including the EnCase, FTK (AD1) and DD formats. Their contents will be indexed as if they were mounted and indexed as a regular Folder source. Optionally, files and folders can be recovered from the Master File Table (MFT). Carving of unallocated space and slack space is not supported.
MS Exchange EDB Archive
Use this option to index an MS Exchange EDB files and restrict indexing to a specific set of mailboxes. Indexing an EDB file in its entirety can be done by using the File or Folder source type.
Vound W4 Case
Entire cases created by Vound W4 can be imported.
IMAP account
Email accounts on an IMAP email server can be indexed, including all emails and attachments.
Dropbox
Both personal Dropbox and Dropbox for Business accounts can be accessed. Folders and files stored in that account will be retreived and indexed.
Gmail
Gmail accounts can be accessed and indexed, including all emails and attachments in that account.
SharePoint
Both local and cloud SharePoint instance can be accessed, indexing one or more of the sites in that instance.
Office 365
The complete contents of an Office 365 account can be accessed and indexed, incl. the Outlook, OneDrive, and SharePoint services of that account.
iCloud
Apple iCloud accounts can be accessed and indexed, including all information synced to that account from an associated device or entered on icloud.com.
2.6. Supported languages
As Vound applications are entirely based on Unicode, they can index and provide keyword search for texts from any language. There is no specific support for the handling of diacritics. E.g., characters like é and ç will be indexed and displayed, but these characters will not match with 'e' and 'c' in full-text queries.
The Language facet supports detection of the following languages:
af |
Afrikaans |
he |
Hebrew |
nl |
Dutch |
th |
Thai |
|||
ar |
Arabic |
hi |
Hindi |
no |
Norwegian |
tl |
Tagalog |
|||
bg |
Bulgarian |
hr |
Croatian |
pa |
Punjabi |
tr |
Turkish |
|||
bn |
Bengali |
hu |
Hungarian |
pl |
Polish |
uk |
Ukrainian |
|||
cs |
Czech |
id |
Indonesian |
pt |
Portuguese |
ur |
Urdu |
|||
da |
Danish |
it |
Italian |
ro |
Romanian |
vi |
Vietnamese |
|||
de |
German |
ja |
Japanese |
ru |
Russian |
zh-cn |
Simplified Chinese |
|||
el |
Greek |
kn |
Kannada |
sk |
Slovak |
zh-tw |
Traditional Chinese |
|||
en |
English |
ko |
Korean |
sl |
Slovene |
|||||
es |
Spanish |
lt |
Lithuanian |
so |
Somali |
|||||
et |
Estonian |
lv |
Latvian |
sq |
Albanian |
|||||
fa |
Persian |
mk |
Macedonian |
sv |
Swedish |
|||||
fi |
Finnish |
ml |
Malayalam |
sw |
Swahili |
|||||
fr |
French |
mr |
Marathi |
ta |
Tamil |
|||||
gu |
Gujarati |
ne |
Nepali |
te |
Telugu |
3. Getting started
|
Same requirements, suggestions and security considerations that apply for Intella Connect, apply also for Intella Node product. |
3.1. Who should be involved in the successful setup of Intella Connect?
While setting up Intella Connect is very straightforward, it does require a sound experience with network and computer configuration. Further to this, the person setting up Intella Connect will often need to enlist the experience, permissions (user credentials) and sign-off of a number of other specialists to complete a successful installation.
Intella Connect is a web server and as such requires that a successful setup takes the following into account:
-
The security of data and any policies your organization may have for transmitting data across a network.
-
The configuration of the base operating system used for Intella Connect.
-
The configuration of firewalls on the host operating system.
-
The configuration of security software such as anti-virus programs.
-
Any firewall(s) between the Reviewer and the Intella Connect server.
-
If Intella Node is used, any firewall(s) between the Intella Node server and the Intella Connect server.
-
Configuration and access to any secure networking protocols such as VPN’s or other network-based encryption methods.
-
The storage locations for evidence and case folders.
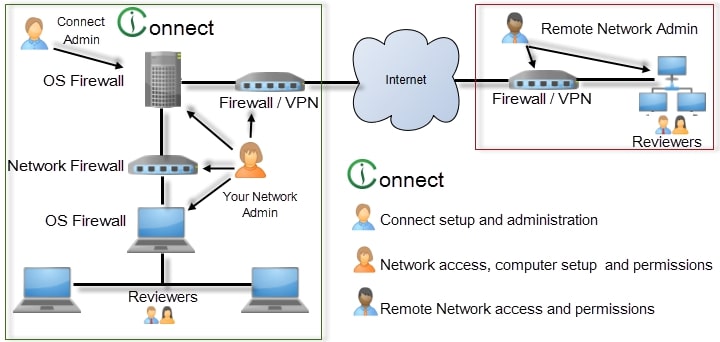
The image above shows a simplistic Intella Connect environment.
With this in mind, Vound suggests that the following user types are involved in the planning and installation of Intella Connect:
The Connect Admin - The person who will manage Intella Connect. They should have a detailed understanding of case management, e.g. be able to manage the administration of adding new cases and assigning reviewers to Intella Connect.
Your Network Admin – Your network administrator will be crucial in the setup of Intella Connect. He or she will have experience in setting up a web service on a server and will be able to guide the Intella Connect Administrator on the best and most secure configuration methods to do so.
They will need to have the user credentials and knowledge to:
-
configure and manage the Standard Operating Environment (SOE) of both the Intella Connect server and Reviewers computers.
-
advise on the port that Intella Connect uses to ensure that there are no conflicts with other applications.
-
advise on the best ports to share cases on and to ensure that there are no conflicts with other network traffic.
-
set the configuration of the server, firewalls and VPN to allow Intella Connect to share cases using the chosen port and networks.
An experienced network administrator should be able to install Intella Connect in 1-2 hours. However, this will take much longer if a detailed plan of what tasks need to be done prior to sharing a case is not undertaken.
|
Failing to involve a competent network administrator is a mistake. It can lead to an insecure setup or cause network issues that can affect all other network users. It may even see you breach company policies on the transfer of data between networks. |
What if you don’t have a network administrator? It is expected that you will have a good knowledge of Windows, networks and firewalls prior to installing Intella Connect. Please understand that Vound cannot offer support for these topics as they are the prerequisites for running a web service.
The Remote Network Admin – If you are planning to share a case over the Internet, you will need to have your network administrator work with the remote network administrator to enable secure case sharing. The remote network administrator will most likely have the same responsibilities as your network administrator and be best placed to ensure success.
In summary
Installing Intella Connect will involve more knowledge and experience than installing other Vound products. If you have not installed a web service or configured a fire wall before, you should seek help from a qualified network administrator prior to doing so. At all times, security and stability should be your goal.
3.1.1. Assumptions
This section makes the following assumptions:
-
The computer or server used is solely for Intella Connect.
-
The network used is a LAN and not subject to any firewalls other that the on the client or server.
-
The settings given below are validated as secure and allowed by the organization.
-
The user will consult their network administrator for configuration options should they wish to share a case via the internet.
-
Any other security software will be disabled during setup.
3.1.2. Operating Systems
Intella Connect can be installed on the following operating systems:
-
Windows 8
-
Windows 10
-
Windows Server 2008
-
Windows Server 2008R2
-
Windows Server 2012
-
Windows Server 2012R2
-
Windows Server 2016
-
Windows Server 2019
Although our products can be installed on a number of Windows Server products such as Server 2012, 2016 and 2019, our products do not require a server operating system, and they run perfectly well on the listed desktop operating systems. For server installations, we only support our applications. We do not provide support for the server itself. Server security settings may need to be configured, and ports may need to be opened, for our products to operate on a server platform. These settings need to be addressed by your IT team to ensure that security of the system is maintained.
|
We do not recommend installing Intella Connect on Home editions of Microsoft Windows. |
3.1.3. Potential Conflicts
-
Certain anti-virus software, specifically AVG, have prevented or interfered with the installation of Intella Connect. Therefore it is recommended that you disable any anti-virus software before installing Intella Connect.
-
We do not support the installation of Intella Connect on a Server OS that already has IIS configured for web hosting.
3.2. Installing and starting Intella Connect/Node
|
There is one installer that can be used to install Intella Connect and/or Intella Node. |
-
Download Intella Connect through the Downloads page on the Vound support website: https://www.vound-software.com/software-downloads
-
Double-click on the downloaded
.exefile to launch the installer. Accept the license. -
Choose the product you wish to install.
-
Enter the location to store the application files and shortcuts or accept the default installation path.
|
Intella Connect/Node will not install in an installation folder of an
earlier version. Install a new version of Intella Connect/Node in a
folder with a new name, for example:
|
|
Please make sure that clocks of servers running Intella Connect/Node are globally synchronized. Not doing so can lead to hard to debug issues. |
-
If Intella Connect/Node should be installed as Windows Service, follow one of the following sections based on the product you are installing:
-
Installing and starting Intella Connect as a Windows Service -
-
Installing and starting Intella Node as a Windows Service -
otherwise uncheck the checkbox labeled "Install as a Windows Service".
-
-
All files will be extracted to the location of your choosing and an Intella Connect/Node shortcut is (optionally) placed on your desktop and in your Start menu.
-
User folder
%USERPROFILE%\AppData\Roaming\Intella Connectwill be created. It contains Intella Connect/Node related settings, files and data.
3.2.1. Installation of Intella Connect and Intella Node on the same machine
It’s important to understand that remote indexing feature available in Intella Connect was designed in a way which promotes installing instances of Intella Connect/Node on separate servers. The reasons are outlined below:
-
improved scalability - adding more processing power can be as simple as adding new machines to the network and installing Intella Node on them
-
improved fault tolerance - if unexpected events will cause one instance of Intella Node to go down, then one has higher chances that processing and reviewing of other cases will be unaffected
-
faster troubleshooting - maintaining independent systems is much easier and speeds up potential error analysis and recovery
We suggest to take this into consideration when designing new systems and adjusting existing ones if feasible.
|
We do not recommend, or support installing Intella Connect and Intella Node on the same server. |
|
Instances of Intella Connect and Intella Node are reusing the same configuration files. This should be accounted for during installation, backups or migration. |
That being said, it might make sense to do this when setting up testing environment or when using cutting-edge servers. In such cases a highly qualified IT personnel should make a risk-to-reward assessment.
3.2.2. Changing a default port
Before starting Intella Connect/Node for the first time you may want to change the default port (9999) Intella Connect/Node is running on.
To change default port of Intella Connect or Intella Node please look
for user.prefs file located in:
%USERPROFILE%\AppData\Roaming\Intella Connect\prefs then open it with
a text editor and find ServerPort or NodePort property respectively.
|
If |
For Intella Connect You should change it to desired port like:
ServerPort=8080 to run on port 8080.
For Intella Node You should change it to desired port like:
NodePort=8080 to run on port 8080.
|
If Intella Connect/Node is already running when port is changed, it will have to be re-started for changes to take effect. |
If Intella Connect and Intella Node will be running on the same computer, then they cannot have the same port (read more).
How to choose the best port for Intella Connect/Node:
If you do not wish to use port 9999 for Intella Connect/Node you may select a port of your choosing. One option is to use port 80, a common port that is usually open in the firewall for at least outbound connections already. Using port 80 removes the need to add a port to the Case URL when typing it into a web browser as well. Like all ports, port 80 must not be presently occupied. If you wish to choose another port, you can select one from 1…65535 although it is best to choose a port greater than 1023 as those 1…1023 are registered ports and may be in use already. No matter what port you select, you should confirm whether or not it is in use on the host already.
3.2.3. Local Firewall Configurations
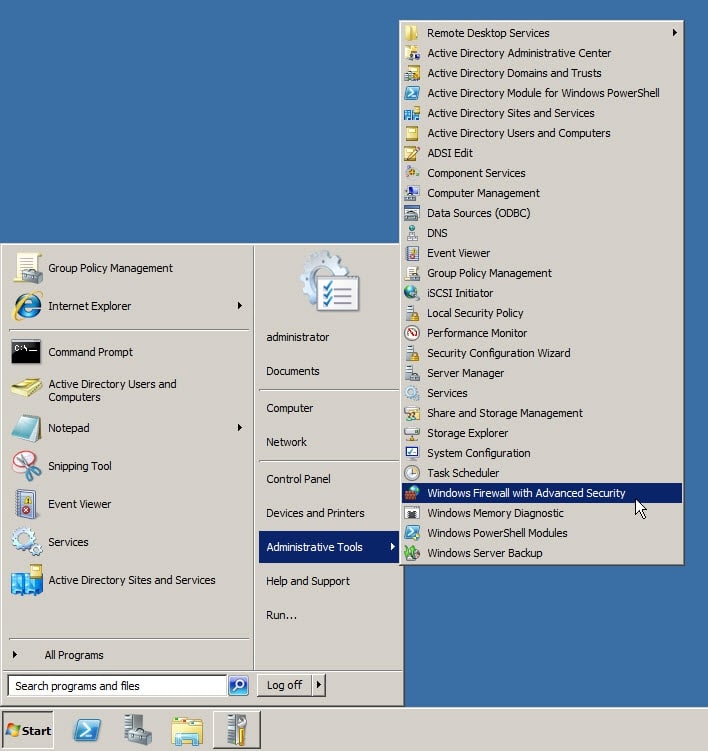
Intella Connect uses port 9999 (you can also assign a different port of your choosing as described in Changing a default port). This port must be open on the local firewall in order for Intella Connect/Node to work correctly. To configure the local firewall for Server 2008 R2, go to Start – Administrator Tools – Windows Firewall with Advanced Security.
To enable or disable the Windows Local Firewall, click on Windows Firewall Properties.
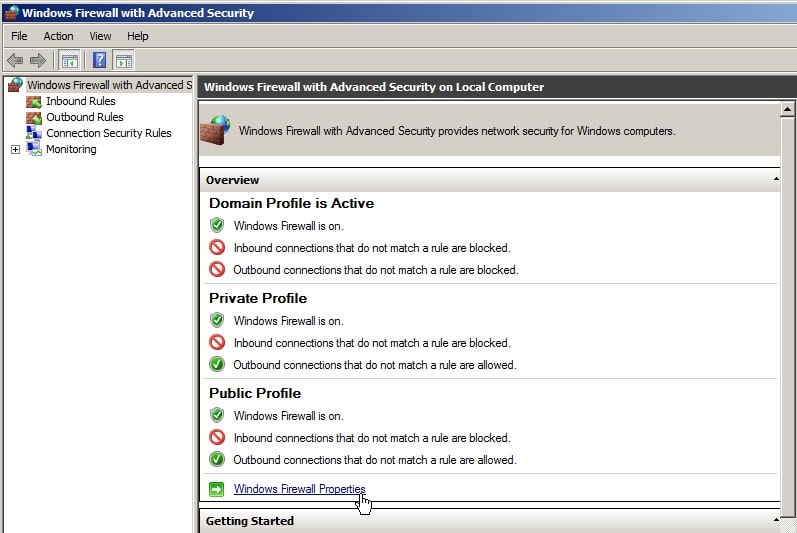
There are three separate profiles contained within the Windows Firewall. They are:
-
Domain - Applied to a network adapter when it is connected to a network on which it can detect a domain controller of the domain to which the computer is joined.
-
Private - Applied to a network adapter when it is connected to a network that is identified by the user or administrator as a private network such a home network.
-
Applied to a network adapter when it is connected to a public network such as those available in airports and coffee shops. When the profile is not set to Domain or Private, the default profile is Public.
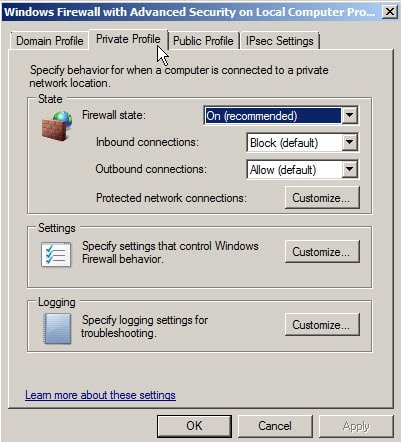
Select the Profile you want to configure and select On or Off. If the firewall is turned on you may select either Block (default), Block all connections or Allow for Inbound Connections. You may select Allow (default) or Block for Outgoing connections.
-
Intella Connect
-
For the Intella Connect server, the host in which you share the case, you must configure the firewall for inbound connections.
-
For the client, the host in which you will review the case, you must configure the firewall for inbound connections.
-
-
Intella Node
-
For the Intella Node server, the host where indexing will be performed, you must configure the firewall for inbound connections.
-
For the Intella Connect, the host which will communicate with the Intella Node, you must configure the firewall for inbound connections.
-
Although you can configure the firewall at large, in most situations you probably just want to configure the firewall for the Intella Connect/Node designated port only. To do so, right click either Inbound or Outbound Rules and select "New Rule".
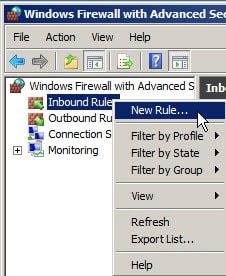
In the New Rule Wizard, select Port.
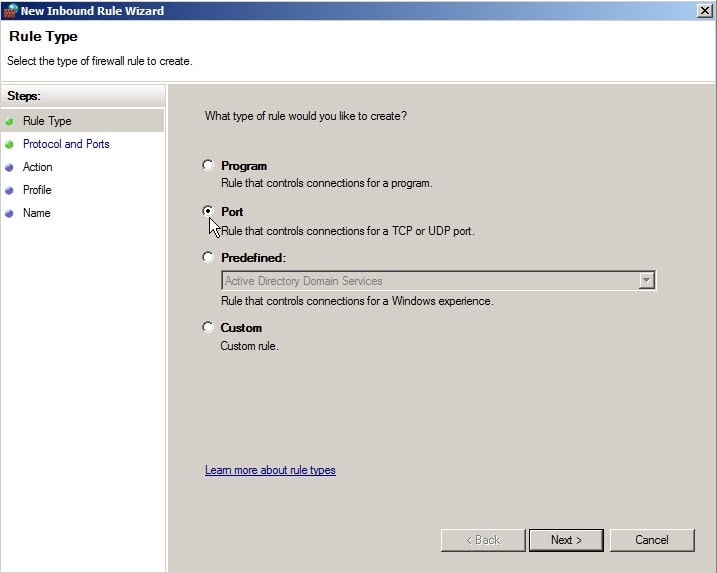
Select TCP as the Protocol and 9999 as the Port or the port you have chosen as described in Changing a default port.
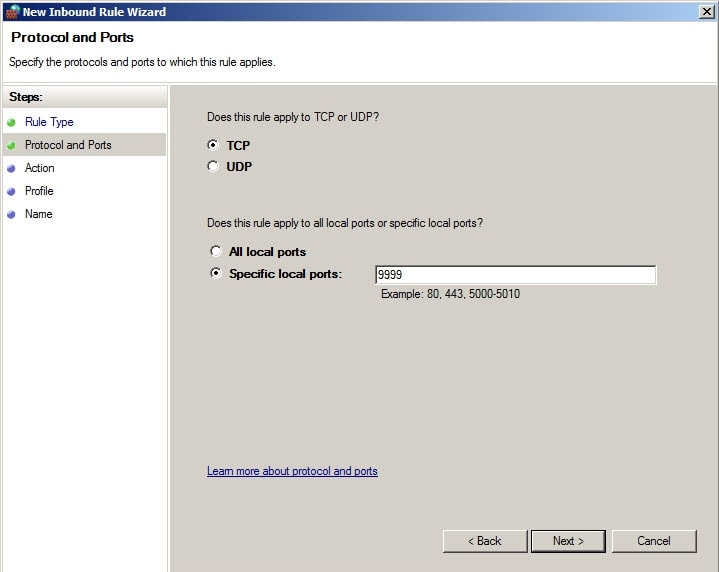
Select "Allow the connection".
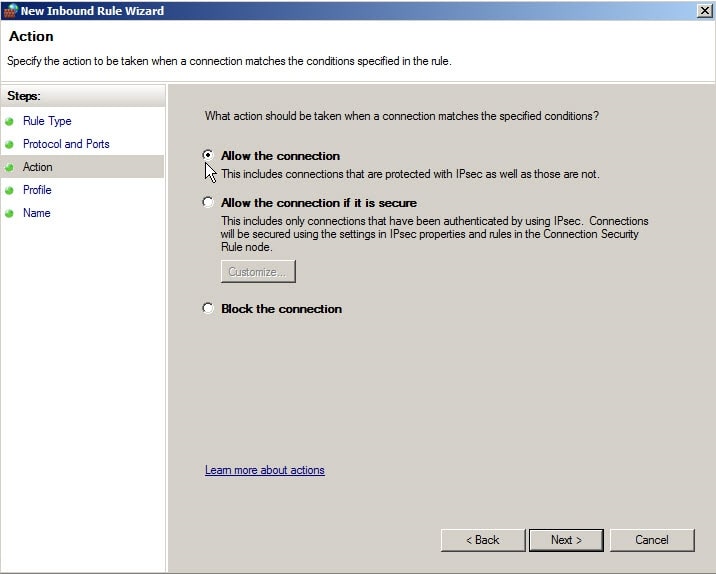
If you wish to designate only designated users to this port, you may select those users in "Authorized Users".
You can also select designated computers as well.
Then select the profile you wish to use.
Finally, name the Rule appropriately.
The Rule will now appear in the list of rules.

To access the Windows Firewall in Server 2012, click on the Server Manager icon in the task bar.

Then select Local Server in the left hand menu.
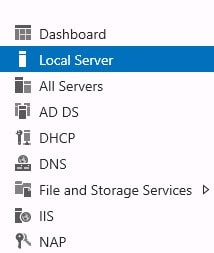
Then select Windows Firewall and Advanced Security from the Tools menu in the right hand corner.

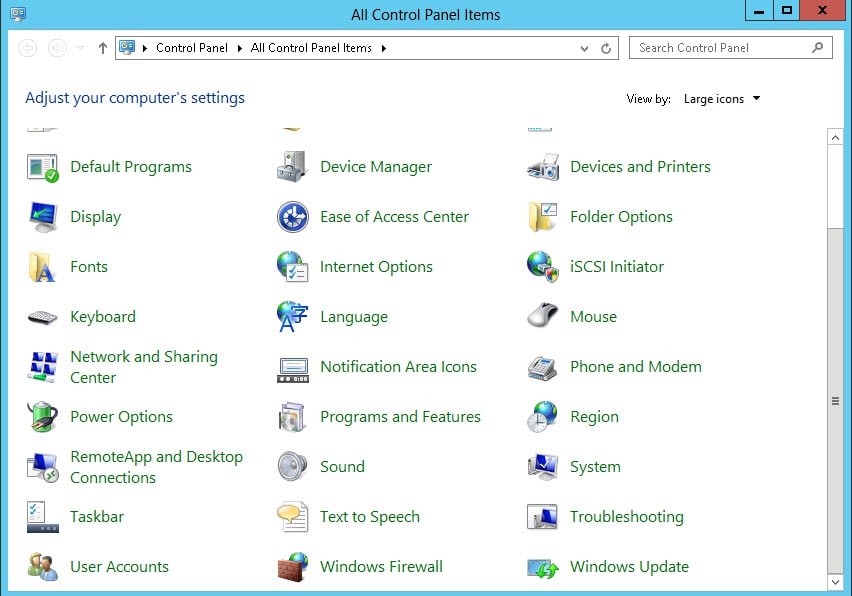
The procedure to configure the Windows Firewall is identical to that of Server 2008 R2. You can also access the Windows Firewall through Control Panel just like any of the Windows Workstation operating systems.
3.2.4. Starting Intella Connect/Node
The application folder contains an executable called
IntellaConnect.exe or IntellaNode.exe in case of Intella Connect or
Intella Node respectively that can be used to launch the application.
The desktop and menu shortcuts also start this executable.
To start Intella Connect/Intella Node, double-click on the Intella Connect/Intella Node icon on the Desktop or select Intella Connect/Intella Node from the Start menu.
|
If you click on this icon more than one time, you will receive the following error: |
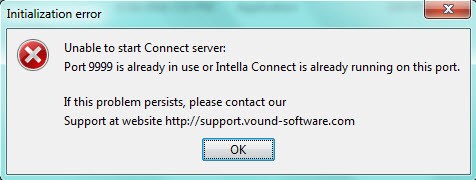
This is because only one instance of Intella can run at a time.
If you are receiving this error after starting Intella Connect/Node for the first time, please look at section Troubleshooting port conflicts.
|
No splash screen or window will be shown when you start Intella Connect/Node. Instead, an Intella Connect/Node icon will show in the Windows system tray. |
Based on the application proceed with those steps:
-
Intella Node - Locate the green Intella Connect logo in the system tray and double-click on it. This will open Intella Node local status page. If message saying "The Intella Node is prepared now" is present the installation of Intella Node was successful. You can proceed with Case Templates section in order to make use of newly installed Intella Node by Intella Connect.
-
Intella Connect - Please proceed with reading the rest of this section.
![]()
Locate the green Intella Connect logo in the system tray and either:
-
double-click on the icon, or
-
right-click on the icon and select the Admin Dashboard menu entry.
This will open the Intella Connect Dashboard in your web browser. When
requested for a user account, enter admin as username and admin as
password. These are the default values. How to change the admin password
is explained in the
User management
section.
If using Internet Explorer, you may see this popup message below.

This popup indicates that your computer doesn’t recognize that you are on the Intranet. To correct this simply go to Internet Options. Click the Security Tab and then select Local intranet Sites.
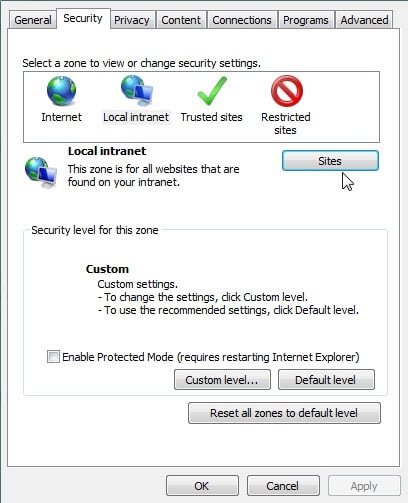
You can then select “Automatically detect intranet network” and all Intranet sites will be recognized.
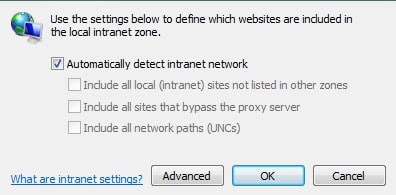
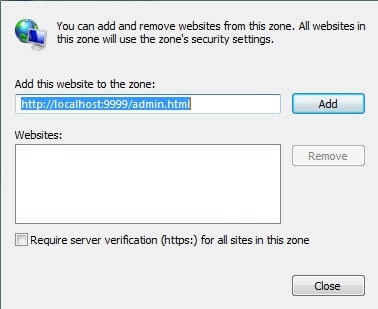
You can also click “Advanced” and insert the address of the Intella Connect site URL as is shown below.
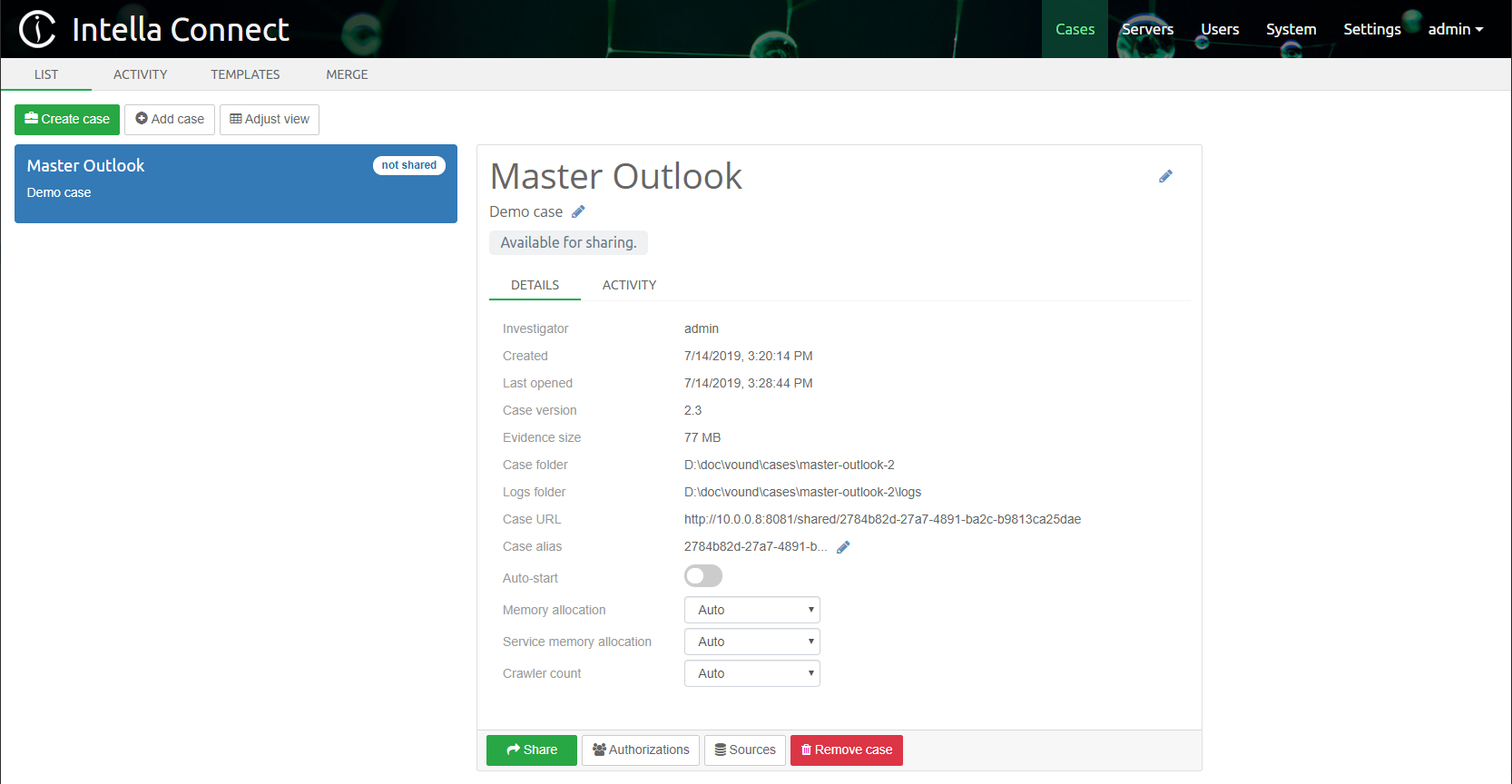
- The Dashboard will show cases
-
-
created using Intella Connect and indexed by Intella Node
-
created with the desktop-based Intella version (Intella 10, Intella 100, Intella 250, Intella Professional or Intella TEAM Manager) on the same computer where Intella Connect is running.
-
If you have not created any cases yet, you can do so in the Intella Case Manager. For more information, please refer to the section called "Creating a new case" in the Intella User Manual.
-
If you already have cases created, but they are located on different computers than the one on which Intella Connect is running, you can choose to do one of the following:
-
Copy the case folder to the computer on which Intella Connect is running and add an existing case, as described in the section called "Opening an existing case not in the list" in the Intella User Manual.
-
Export the case as described in the section called "Opening an existing case not in the list" in the Intella User Manual and import the case on the computer on which Intella Connect is running, as described in the section called "Importing a case".
-
-
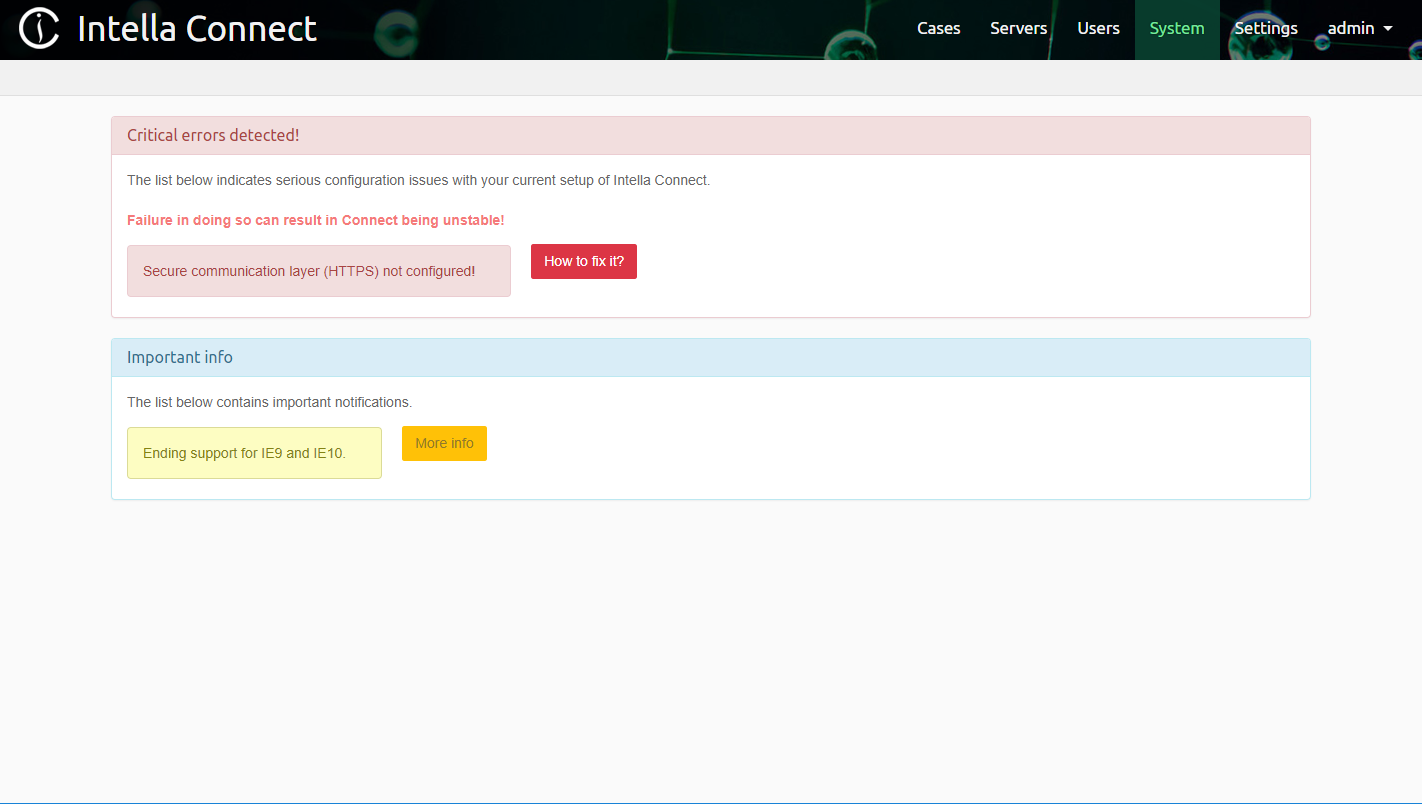
It is recommended to go to the Admin Dashboard and select Systems Notifications which will inform you of any critical alerts or potential issues.
3.3. Licenses and dongles
Notes on the trial license that is bundled with the software that you have downloaded:
-
2-Day evaluation period.
The trial version runs under a HASP Software License, which gives you the ability to use Intella Connect for 2 days. The 2 days evaluation period cannot be extended. The only way to continue using Intella Connect is to purchase a dongle.

-
Continue working with a USB dongle.
If you would like to continue using Intella Connect after this 2 day period, you will need to buy a license. After buying the license you will receive a USB dongle that will allow you to continue using the version you already installed. A dongle provides a perpetual license.
-
System clock.
Changing the clock on your system will cause the trial to automatically expire. When this occurs, the only way to continue using Intella Connect will be to purchase a license.
-
Virtual Machines, VMware.
The evaluation version will not work in VMware without a dongle.
-
RDP (Remote Desktop Protocol) connection.
When using RDP, the dongle or trial license must be in/on the computer running the Intella Connect, not in the computer running the RDP viewer.
-
Other dongle-protected software must be closed
All other HASP protected software, like EnCase (Guidance), Smart Mount (ASR Data), HBGary and i2 products, must be closed when installing Intella Connect.
3.4. Sharing a Case
Select the case you wish to share by clicking on the case name in the Dashboard. This will show the case details on the right side of the page and allow you to access the settings and share function for that case.
It’s possible to change case URL by changing Case alias field present in case details section.
|
Only alphanumeric characters and hyphen can be used when specifying Case alias. |
How to define the users that will be able to access shared cases is explained in the User management section.
Once complete, click Share.
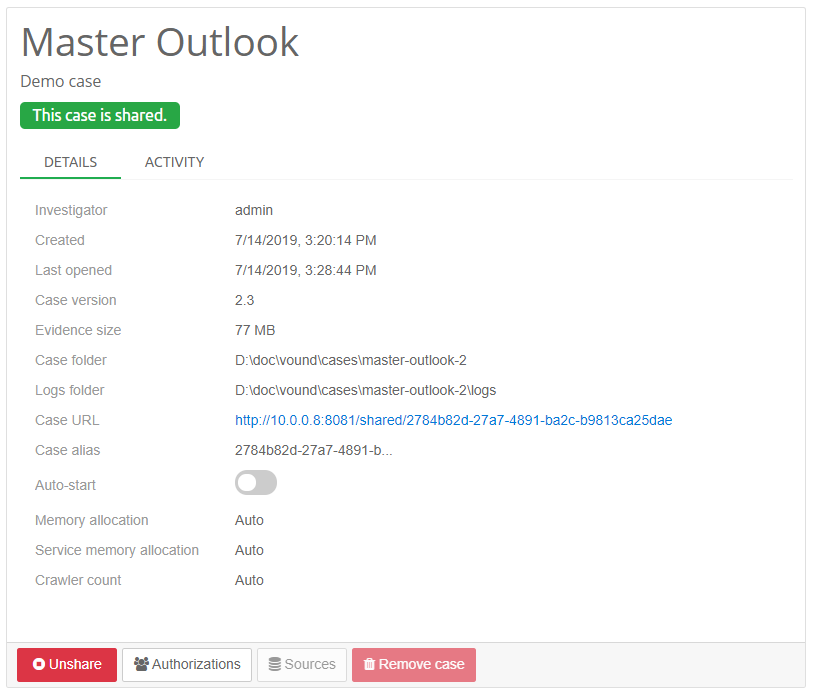
The image above shows the case having been shared. Note the location of the case address and port, shown as a blue hyperlink.
|
When you are sharing a case with Intella TEAM Manager or have it opened locally, you will not be able to share it with Intella Connect at the same time. Only one application can use a case at a time. |
|
If for some reason case will not open, try refreshing your browser by pressing the F5 button. If that does not help, please try to re-enter the case URL into the browser’s address bar. |
3.4.1. Granting case access to users
Before or after a case has been shared, you can define which users can
access it. By default no user can connect to a shared case. To allow
users to participate in a review you can click on the Authorizations
button. This will open a modal window where you can assign users to
various roles.
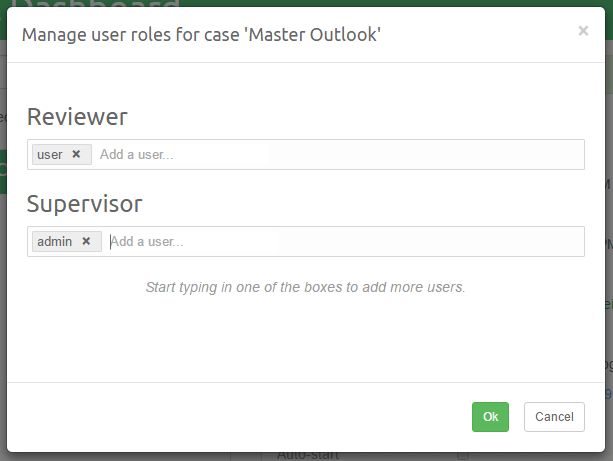
The purpose of this view is to list the roles defined in the RBAC (Role-Based Access Control) model and indicate which users are assigned what roles in this ase. Roles are emphasised by labels with a bright green color. Underneath each role there is a long input box that lists all the users who are assigned that role in this case. Each user can be associated with zero or more roles.
To learn more about users and roles please refer to the User management section.
|
A user can access a given case only if he is assigned a role with the "Case access" permission! |
Assigning roles to users is quite straightforward. Click on the
input box for a particular role (e.g. "Reviewer") and start typing the
desired user name (e.g. "admin" with a lowercase "a"). An autocompletion
box will appear with hints about names available among your user
accounts.
Removing a role for a given user is done via clicking on the little x
button next to the user name.
|
Each change to the roles assignment should be persisted by clicking the
green |
3.4.2. Case alias
Case alias can optionally be changed in order to change the URL on which the case is being shared.
3.4.3. Auto-Start option
Case can optionally be shared with the Auto-start option enabled. The
purpose of this function is to specify which cases should be
automatically shared after the Intella Connect server starts. It is a
good way of making sure that a certain set of cases is always available
for a review, even when Intella Connect is restarted often.
If the case will fail to start, there should be a trace of this fact left in the Case Logs.
3.4.4. Memory settings and Crawlers
The Intella Connect main process and its child processes (one for each case that you share) are limited by the amount of RAM that the process can maximally use, despite how much memory is installed in the machine. In some cases this limitation can cause issues when reviewing or exporting the data. These issues can be recognized by errors in the log files containing the text "OutOfMemoryError" or "java heap space".
Setting memory allocation manually might help in this case. To increase these thresholds, select the case in the Case Dashboard and change the “Memory allocation” setting from Auto to Manual and increase the value. The value is in mega bytes.
Note that you can never specify more than half of the available system RAM. This is to make sure that when more then one case is shared, those processes and the OS still have sufficient memory available to them.
The memory setting for the Crawler processes is calculated automatically based on the amount of RAM minus the memory used for the main process, and the number of crawlers that will be used. By default Intella Node calculates the number of crawlers based on the number of CPU cores in the system. However, this number is capped at 4 as assigning more crawlers without other considerations can adversely affect performance.
When the amount of memory per crawler is set automatically by Intella Node, it will be capped at a maximum of 2GB per crawler. Again, this is a setting that usually does not need any changes, but it can be changed manually if required. The job for the Crawler is only to extract and collect information; they don’t index the data right away. The indexing takes place later in the post-processing steps which are done in the Main process.
|
The settings for the crawlers also controls these other processes:
|
The user can manually adjust these memory and crawler settings to better suit their hardware specifications and the data which they are processing.
To change the amount of memory allocated to crawler process, select the case in the Case Dashboard and change the “Service memory allocation” setting from Auto to Manual and set the value in mega bytes. Make sure that you do not use larger values than what your machine and OS supports. For processing of EDB files, a minimum of 3 GB will be necessary.
To change the amount of crawler processes, select the case in the Case Dashboard and change the “Crawler count” setting from Auto to Manual and set the value. The number of crawlers should never exceed the number of CPU cores on your PC. Setting a too high number might result in nonoptimal performance.
3.4.5. Case sharing limitations
It should be noted that "Software Maintenance And Support Agreement" for Intella Connect defines a hard limit on the amount of active cases that can be concurrently shared by every Connect server. The definition of an active case is that it is shared with a reviewer logged in or reviewing that case. Currently that number should be no more than four at any given time. This hard limit was introduced in Intella Connect version 2.1.
Intella Connect does not have any built-in limitations on the amount of cases defined in the system. However, if you share more than 30 cases at a time, then a warning will be shown to administrators, informing them that this is not recommended. That is because each shared case will occupy some hardware resources, which would be best to use elsewhere. In future releases this scenario will be replaced by a different, on-demand sharing mechanism.
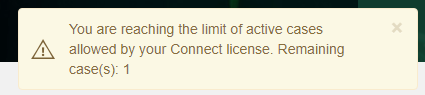
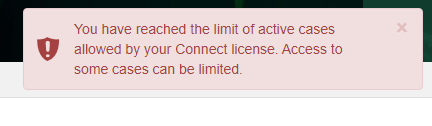
Excessive case sharing can lead to a situation where on some occasions more users log in to different cases, thus promoting them to being active. When this happens and the limit of four active cases has been reached, Intella Connect will start to show warnings to Administrator informing him of this fact. That should be a clear signal to Administrator that some actions need to be taken - either ask reviewers to delay review until other reviewers complete theirs; unshare cases which are not critical; or consider installing another server to offload some cases there. If Intella Connect decides that it needs to take an action to reduce the number of active cases, it may temporarily disable the review of some case, informing users about this fact. All types of warnings are presented below.
Admin notification when approaching the limit of maximum shared active cases:
Admin notification when the limit has been reached:
Reviewer notification when review has been temporarily disabled due to the limit being reached:
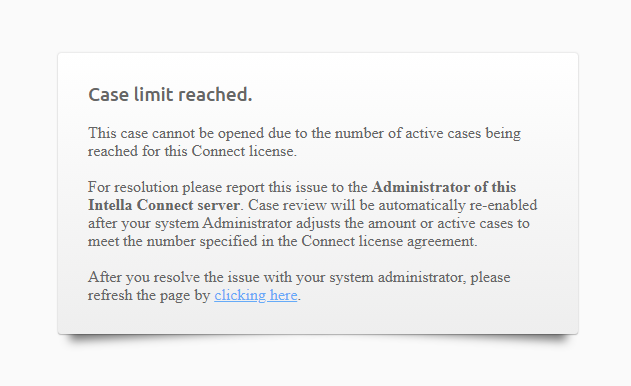
Let’s explain this in more details on a typical, real-life example: Let’s say that one company has created around twenty five cases in Intella Connect. Fifteen have already been completed, so they do not require instant access - administrator decided not to share them. The remaining ten must be available for on-demand access so they have been shared. This means that we have 10 shared cases, but none of them are active yet. When the first reviewer signs in to a shared case, then the case becomes active (1 of 4). Next three other cases can also be activated. Once you have four active cases, activating any other case will cause Intella Connect to start issuing warnings visible to administrator. At this point administrator contacts the reviewer and determines that review will end shortly. After some time has passed after user logged out, the case was deactivated and the limit went down to acceptable level (four active cases). However, if during that time more cases would get activated, then Intella Connect could block the review for one of active cases (see screenshot above).
3.5. Reviewing with Intella Connect
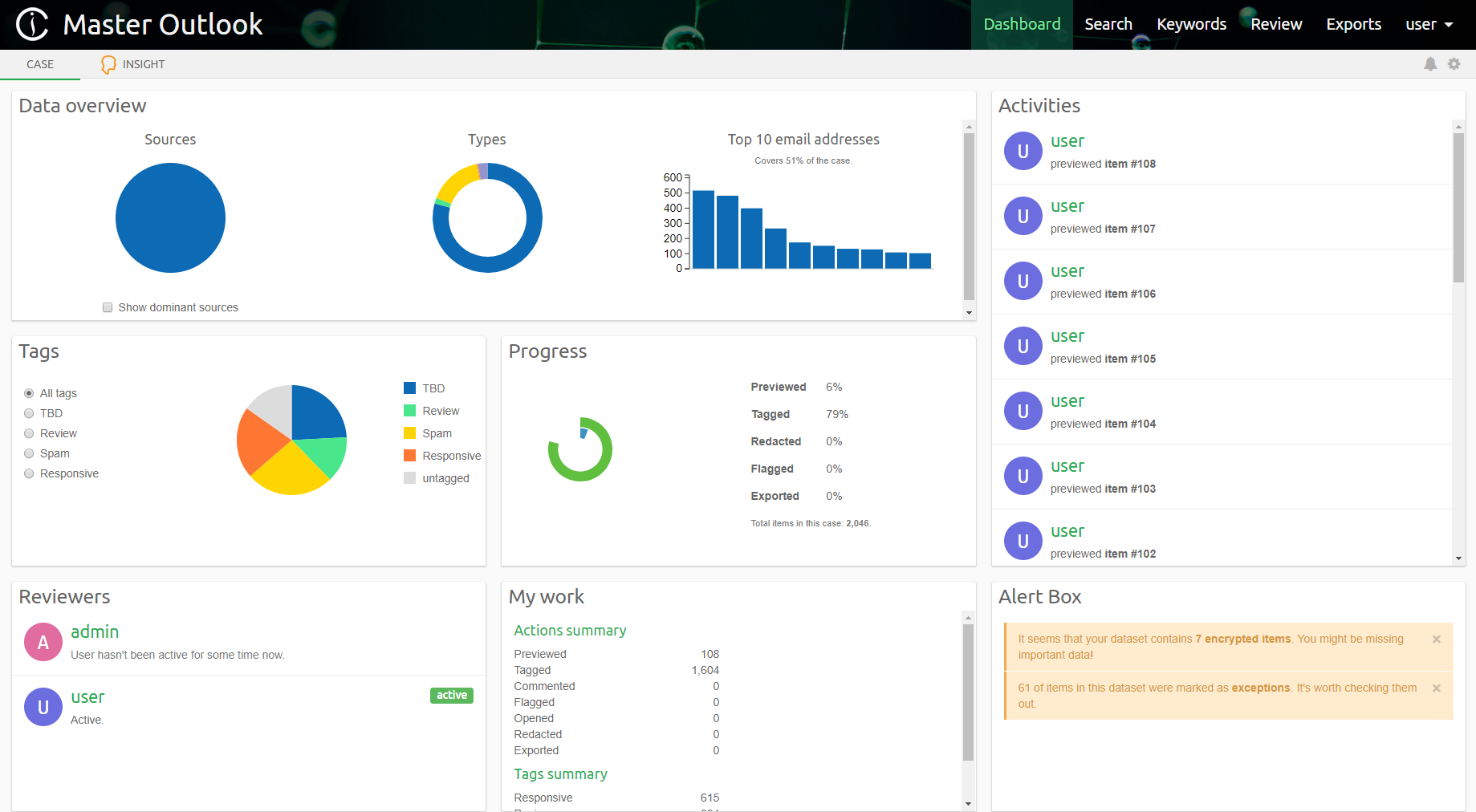
The case is now ready for access from any device having access over the network to the PC running Intella Connect.
A user with the appropriate permission can connect to a case by entering a case URL in his favorite web browser.
In the example above the case URL is:
http://192.168.1.115:9999/shared/master-outlook
You should point users to the same URL you are using to access the Intella Connect Dashboard which is (in the example above):
http://192.168.1.115:9999
Based on their role they will be redirected to the User dashboard where the cases they have access to will be listed and where they can change their avatar image.
|
The remote computer has to have TCP/IP access to the computer specified as the Intella Connect server. |

After logging, the reviewer is presented with User Dashboard where cases he have access to are listed.

After selecting a case, the reviewer can start reviewing it.
3.6. Reviewing case with Intella TEAM or Intella Viewer shared by Intella Connect
It is possible to use Intella TEAM or Intella Viewer products to connect to a case shared with Intella Connect. This can be especially useful if certain features available in the former tools need to be used in a case which is actively reviewed. In such scenarios unsharing a case might not be an option. Thankfully, Intella Connect uses a remote API which is compatible with Intella TEAM and Intella Viewer, so such connection is possible.
In Intella Case Manager, choose "Add…" → "Open a shared case" to get "Create new case" window.
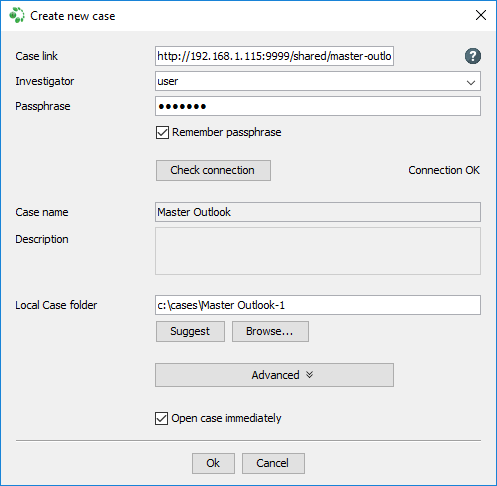
Case link field needs to be filled with case URL, example:
http://192.168.1.115:9999/shared/master-outlook
Investigator and Passphrase fields need user and his password, which was granted access to that case.
Use "Check connection" button to verify if Case link, Investigator and Passphrase field are correct and the shared case can be reached. If those fields will be correct and shared case can be reached, then message "Connection OK" will be shown next to "Check connection" button. Otherwise check if Case link, Investigator and Passphrase field are correct or if firewall is not blocking communication. If the case still cannot be reached, check if it can be reviewed in browser as described in Reviewing with Intella Connect section.
After filling in Local Case folder and clicking Ok, the shared case will open and the reviewer can start reviewing it.
3.7. Troubleshooting port conflicts
If you are getting the following error message:
It could mean that there is an application already running on the host computer that is utilizing port 9999 (this section assumes that you have not changed the default port, however, if you did change it as described in Changing a default port, then please use that port for troubleshooting purposes). To confirm this, make sure that Intella Connect is not running. Then open a command prompt window and type:
NETSTAT –a
Then look for port 9999 and see what the state is in the row:

If there is a port conflict, you can change the default port of Intella Connect as described in Changing a default port.
3.8. Frequently asked questions
How can I print and export PDF reports with characters of my language?
By default,
Intella Connect
supports printing and PDF generation for the basic Latin character set only. To enable printing and PDF export for a language that uses another character set, you need to install an additional Unicode font that supports that language.
-
Download the font file and install it in your system
-
Copy the font file to the font subfolder of your Intella Connect installation: C:\Program Files\Vound\Intella Connect 2.4\font
-
Restart Intella Connect
The font must be a Unicode TrueType or OpenType font with “.ttf” or “.otf” file extension. The font folder must contain a single font file only. Using more than one font at the same time is not supported at the moment.
Recommendations for font selection:
-
For Chinese, Japanese, or Korean languages it is recommended to install a language-specific font. A large list of fonts for different languages and writing systems is available at http://www.wazu.jp/. If you already have the native font installed on your Windows system, you can copy it from “C:\Windows\fonts” to the Intella Connect “font” folder.
-
For languages other than Chinese, Japanese or Korean, it is possible to install a single universal font supporting a broad range of character sets. You can try the GNU FreeFont font collection at http://www.gnu.org/software/freefont/.
4. Installing and starting Intella Connect as a Windows Service
|
In order to install Intella Connect as a Windows Service, one must fulfill few preconditions. Please do not proceed with the installation until you read the remainder of this document! |
- To install Intella Connect as a Windows Service, you will have to
-
-
pick a Windows account under which Intella Connect will run
-
make sure that this account is properly set up
-
validate and adjust your firewall settings
-
|
When Intella Connect is installed and running as a Windows Service, it cannot be started from executable as standalone application. Intella Connect Windows Service must be stopped in order to start Intella Connect as standalone application. |
4.1. Providing valid credentials (during installation)
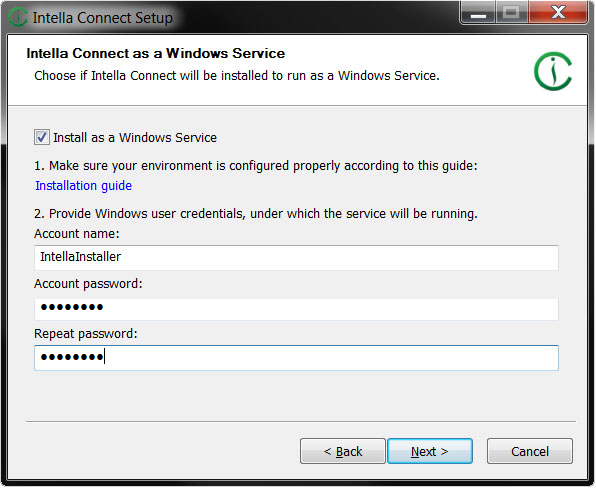
During installation, on an installer page dedicated to Windows Service installation you will be asked to provide credentials for Windows user account. This is necessary as Intella Connect needs to run in the context of a particular Windows user and keeps its configuration inside the home directory of that account. Make sure not to have the service installed to log in as LocalService, NetworkService or LocalSystem. If you are installing Intella Connect as a Windows Service on a user within a Domain, the "Account name" field in the installer needs to be in form "DOMAINUSER". For instance, for an account "JohnDoe" within domain "DoeDomain" the correct value would be "DoeDomain\JohnDoe".
You must first assign the user that is installing Intella Connect the right to “Log on as a Service.” If you are installing Intella Connect on a workstation or member server, you can do this either by configuring the “Local Security Policy” or by creating and configuring a Group Policy Object for that host.
If you are installing Intella Connect on a Domain Controller you can either configure “Domain Controller Security Policy” or create and configure a Group Policy Object. To configure the Local Security Policy which is available under Administrator Tools and expand Local Policies – and click on “User Rights Assignment.” Then select “Log on as a service” and select the user or group for the account that will be doing the installation.
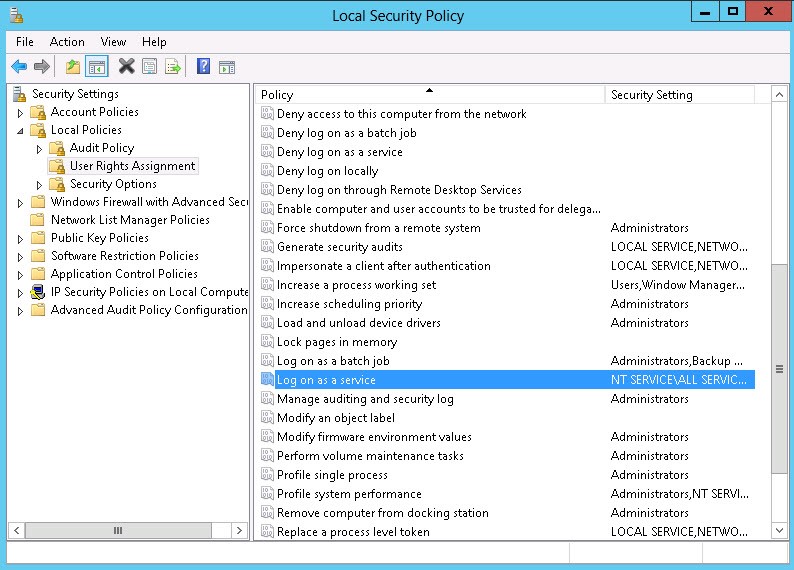
To configure a Group Policy Object, go to Computer Configuration – Windows Settings – Security Settings – User Rights Assignment and once again select “Log on as a service.”
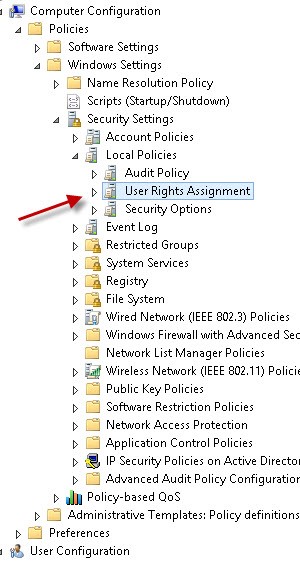
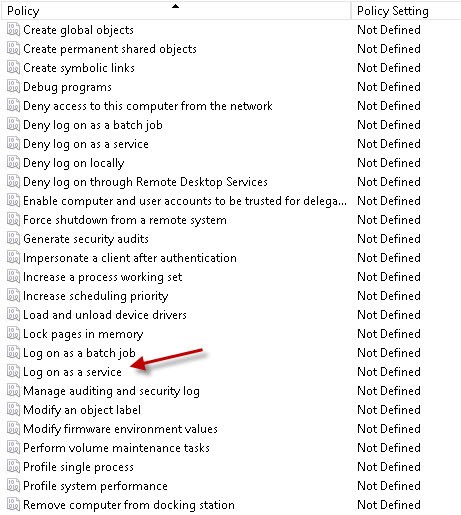
Then select the appropriate user or group.
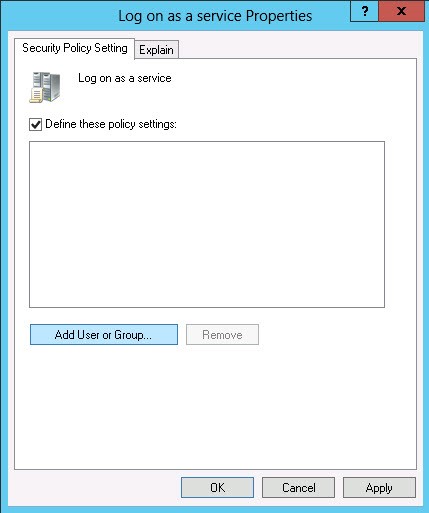
Once the “Log on as a service” right has been configured, the assigned user can then install Intella Connect as a Windows Service. In install wizard, during the step outlined below, the login credentials of the user configured with the “Log on as a service” right must be input.
4.2. Firewall settings for using Intella Connect as a Windows Service on Windows Server operating systems
|
Intella Connect will automatically add few required firewall rules during installation. However, depending on the specificity of your deployment, you might still need to adjust your firewall settings. |
The firewall on Windows Server operating systems is more restrictive than in desktop Windows operating systems. This will manifest by traffic on loopback network interface (127.0.0.1 or localhost) to be allowed, but any packets incoming to local network interface (from outside of the machine) to be dropped. Thus, using browser on the server to navigate to Intella Connect dashboard, will show the page without any issues, but when using browser on different machine on the network, it will fail to display the dashboard.
To allow incoming traffic on the server:
-
Open Windows Firewall with Advanced Security.
-
In the left pane, click Inbound Rules, and then, in the right pane, click New Rule.
-
In the New Inbound Rule wizard, choose Port Rule Type.
-
Specify the port on which Intella Connect will be running and follow the instructions of the wizard on the remaining options. If this is the first time that Intella Connect is installed or the port was not changed, then the default port 9999 will be used.
If the port on which Intella Connect is running will be changed at any point later in time, then this firewall rule will need to be updated as well to reflect the port change.
4.3. Adjusting settings in *.ini files
|
When Intella Connect/Node is installed as a service, the settings in IntellaConnect.l4j.ini (or IntellaNode.l4j.ini) file are ignored. |
Few specific settings controlling Intella products family have to be adjusted through the INI files located in the program’s installation folder. Those are being used when Intella Connect/Node is started using the executable file (*.exe). However, when it is started as a Windows Service these settings will not have any effect.
To fix this, any environmental settings need to be edited through the connect-service.bat. You can open this file with a text editor and add any settings to the JVM_OPTIONS variable. This is presented below:
Before the change:
set JVM_OPTIONS=-Dintella.logSlowRequests=true;-Dintella.runningAsService=true;
After the change:
set JVM_OPTIONS=-Dintella.logSlowRequests=true;-Dintella.runningAsService=true;-Dintella.crawlersCount=12;
After editing and saving this file, Intella Connect Windows service needs to be uninstalled and installed with new settings in order for this change to be propagated into Windows services system. The script file has the following parameters:
-
the action that this script performs. It can be one of these values: install, uninstall, start, stop
-
Windows user account name
-
Windows user account password
An example of executing this file:
connect-service.bat uninstall connect-service.bat install ./Administrator password
|
It is not required to uninstall the service if it wasn’t previously installed. |
4.4. Intella Connect as a Windows Service running under user account without password
By default, a security setting restricts local accounts that are not password protected to be able to log on only at the physical computer console. The Intella Connect Windows Service will be aborted silently during automatic startup and if attempted to start it manually, it will show following error: Error 1069: The service did not start due to a logon failure.
|
Computers that are not in physically secure locations should always enforce strong password policies for all local user accounts. Otherwise, anyone with physical access to the computer can log on by using a user account that does not have a password. |
To allow Intella Connect Windows Service to run with user account that is not password protected:
-
Open Local Security Policy.
-
In the left pane, click Local Policies - Security Options.
-
Double-click on "Accounts: Limit local account use of blank passwords to console logon only" and choose disabled.
4.5. Manual (un)installation Intella Connect Windows Service
In some situations it’s desirable to install, uninstall or reinstall Windows Service associated with Intella Connect, without the need of going through the full (un)installation of the software. It can easily be achieved with a help of connect-service.bat batch script.
One can follow these steps:
-
Open Windows' Command Prompt as an Administrator. The rest of command are to be executed inside this prompt.
-
Go to the directory holding the latest installation of Intella Connect (2.0.1) For example:
cd C:\Program Files\Vound\Intella Connect 2.0.1
-
Uninstall the previous version by running:
connect-service.bat uninstall
-
Then install version from the current directory by running:
connect-service.bat install CONNECT_USER CONNECT_USER_PASSWORD
- Available commands are listed below
-
-
uninstall - uninstalls any previous "Intella Connect" Windows Service
-
install - installs "Intella Connect" Windows Service for the version located in the current directory
-
start - starts "Intella Connect" Windows Service
-
stop - stops "Intella Connect" Windows Service
-
debug - starts "Intella Connect" Windows Service with additional debugging information
-
- Caveats
-
-
if the connect-service.bat operation outputs "SUCCESS", it doesn’t necessarily mean that operation achieved it’s goal (this output just reports that the operation did not encounter errors while executing)
-
when providing the account name as an argument (ex. CONNECT_USER) make sure to always provide its associated Windows' Domain too. For instance, for a local account "JohnDoe" the correct value would be ".\JohnDoe" because this account is a part of the local domain.
-
To check if everything went fine it’s best to open "Services" tool built into Windows and verify if "Intella Connect Service" entry is listed as a running Service. There should also be "Log On As" property matching the account specified in step 4. If it doesn’t show up there, then you should modify it there directly by right clicking and opening "Properties" ("Log On" tab).
If the connect-service.bat operation outputs "The system cannot find the path specified.", then it suggests that some path within the script is not correct. Make sure that all paths listen in following variables are correct: LOG_DIR, START_PATH, PROCRUN_FILE, CUSTOM_CLASSPATH.
5. Installing and starting Intella Node as a Windows Service
Process of installing Intella Node as a Windows Service is exactly the same as installation process of Intella Connect as a Windows Service hence we suggest reading Installing and starting Intella Connect as a Windows service
6. Dongles
Intella licenses are typically delivered in the form of a dongle.
Dongles have several benefits over software-based license keys. For example, users can easily move software licenses from one machine to another by simply plugging the dongle into the other machine, there is no loss of license when the operating system is reinstalled or reverted from an image, changes to the hardware (new motherboard etc.) do not lock the license, hard drive failures do not result in the loss of licenses, etc.
To protect our intellectual property, dongles may not be activated when shipped by Vound or one of its resellers. In that case, it is necessary to activate your Intella dongle to use Intella.
By default, users are supplied with a single user dongle for every ordered copy of Intella. Optionally, a network dongle can be delivered instead. This type of dongle allows for consolidating the licenses of multiple users on a single dongle, which then is typically installed on a physically secured, always-on machine. See the section on network dongles below for how to configure your systems to use a network dongle.
6.1. Activation with the Dongle Manager
Intella ships with a Dongle Manager application. The Dongle Manager will list all connected Vound dongles and the products they currently contain. When the PC running the Dongle Manager is connected to the Internet, it can also contact the Vound license server to check for any updates for a dongle. These updates are then downloaded and applied automatically.
The Dongle Manager is in the Intella program folder
C:\Program Files\Vound\Intella 2.2:
A shortcut to the Dongle Manager can also be found in the Start menu. After starting the Dongle Manager, the following screen will appear:
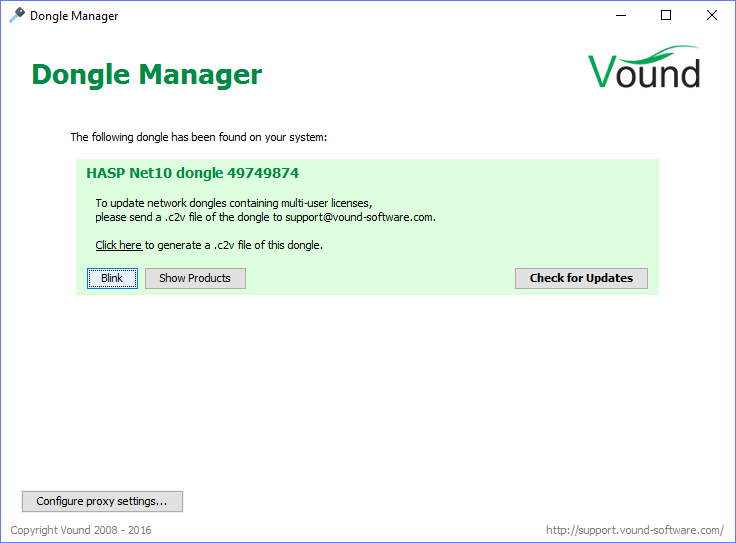
This screenshot shows a typical setup where only one Vound dongle is connected. When multiple dongles are present, they will each be listed separately in this list.
Click on Blink to see to which physical dongle an entry in the list corresponds. This will cause the LED in the represented dongle to blink rapidly. This can be useful when you have multiple Vound dongles plugged in or are using HASP dongles from a different Vendor.
Show Products will list the licensed products on that dongle. All products typically have a perpetual license; hence no license restrictions are displayed by the Dongle Manager.
Show Products also shows a list of expiration dates. These reflect the end date after which you will not be able to receive technical product support and license updates. These end dates do not affect the ability to use the existing licenses on your dongle.
To update your dongle, click on Check for Updates. This will contact the Vound license server and download and apply any updates. When the process has finished, the Dongle Manager will show which products, if any, have been added to the dongle. The update procedure will only add new licenses to the dongle; it will leave your existing licenses untouched.
|
An active Maintenance Agreement with at least 60 days remaining until the expiration date is necessary to qualify for maintenance updates. |
When you are on a network using a proxy, Intella will automatically try to detect and use it. If this fails, the proxy settings can still be set using the Configure proxy settings…. Consult your IT admin for further instructions.
6.2. Activation with haspupdate.exe
If the dongle cannot be updated in this fashion, e.g. because external network connections are not allowed, please follow the steps below.
Step 1: Collect your dongle and license information and send it to Vound Support at: support@vound-software.com.
-
Plug your dongle into an available USB port.
-
Start
haspupdate.exe. You will find haspupdate.exe in the bin folder in the installation folder of Intella. The default installation folder is:C:\Program Files\Vound\Intella 2.2 -
Select the Collect Key Status Information tab. Click Collect information.
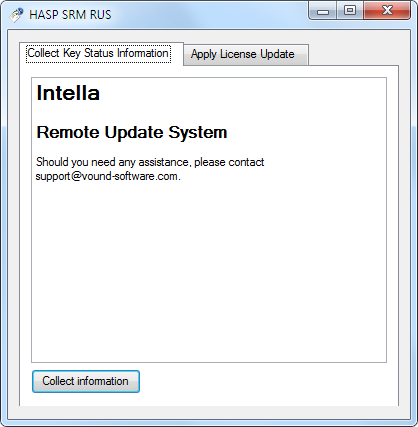
-
In the next dialog, you will be asked to Save key status as. Please save the file with your company name. If you are activating more than one dongle, please number the files. The file(s) you create will have a c2v file extension. Example:
-
ACME_Forensics_1.c2v
-
ACME_Forensics_2.c2v
-
-
After you clicked Save, you will see the Select HASP dialog.
|
Please select the HASP HL key, not the HASP SL key! |
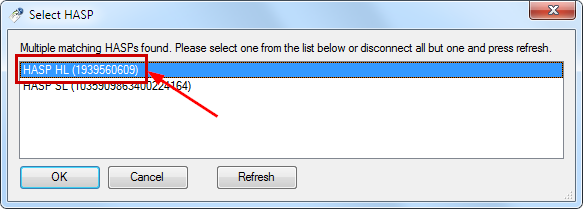
-
Record the dongle ID numbers for each dongle. This will help when applying the update files.
-
Send the created c2v files to support@vound-software.com. Please ensure you include the following details in the email when sending the c2v files:
-
Organization Name
-
Address
-
Zip code
-
Country
-
Contact Name
-
Phone Number
-
Email Address
-
Vound Product type – select only one per dongle:
-
Intella 10 GB
-
Intella 100 GB
-
Intella 250 GB
-
Intella Professional
-
Intella Viewer
-
Intella TEAM Manager
-
-
Step 2: Apply the license update file(s) you receive from Vound Support.
-
Make sure your dongle is connected to the computer that runs Intella.
-
Vound Support will send a dongle activation file. The activation files are dongle-specific. The file will end with a .v2c file extension and the name of the file contains the dongle ID. Example:
-
HaspUpdate_68_304466763.v2c
-
(the dongle ID in this case is 304466763) Save the .v2c file on your computer. Be sure to remember where it is stored!
-
Start
haspupdate.exeas before. -
Click the Apply License Update tab. Then click the Browse button labeled
…next to the Update File field. This opens a file selector dialog.
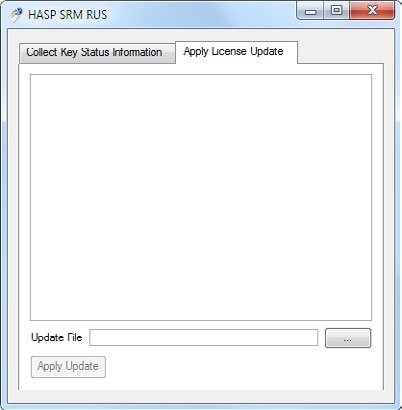
-
Select the .v2c file in the file selector and click Open.
-
Click Apply update button. This will activate the dongle.

Your Intella dongle is now activated!
In case of questions or problems, please contact Vound Support at http://support.vound-software.com/.
6.3. Network dongles
A prerequisite for using network dongles is that the so-called HASP driver is installed on both the client and the server.
This driver is in fact known under several different names due to
historic reasons. When it is installed, it is typically visible as
Sentinel LDK License Manager in the Windows Services application and
under that same name or as hasplms.exe in the Windows Task Manager and
Windows Resource Monitor.
On a standalone PC, the driver provides a bridge between the licensed application (Intella) and the dongle holding the license. Furthermore, it handles software-based licenses such as the bundled trial license. In case of a network dongle, the drivers on the machines stretch that bridge across the network, making the products on the network dongle available to other PCs in the network.
Getting this driver installed is best achieved by simply running the Intella installer on both machines, as it includes the installation of the HASP driver.
Once the HASP driver is up and running on both machines, the drivers will communicate with each other automatically, or after a bit of network configuration (see below). When Intella starts on the client and requests a license from its local driver, the driver will communicate with the server’s driver and exchange information about the network-enabled licenses on the server’s dongle, making the licenses also available to the client. The server’s driver will register that one more user is using Intella, or refuse the operation (and block the client machine from starting Intella) when the allotted maximum number of concurrent users has been reached.
Network dongles often work out-of-the-box, but may in some cases require a small amount of network configuration. This depends mostly on the locality of the client running the Intella server and the server holding the network dongle.
6.3.1. Client and server in single subnet
When the client and server are within the same subnet, no network setup is usually necessary. The drivers on both machines will usually find each other automatically and the client will be able to use the licenses on the network dongle.
For example, in the following setup:
-
Server IP address: 172.168.12.223
-
Client IP address: 172.168.12.26
-
Subnet Mask (Class-C): 255.255.255.0
the drivers will be able to communicate directly, if port 1947 is not blocked.
If Intella is not able to use the network dongle’s licenses, please follow the steps below for setting up usage with different subnets. This may resolve the issue.
6.3.2. Client and server in different subnets
Given the following setup:
-
Server IP address: 172.168.12.223
-
Client IP address: 172.168.16.46
-
Subnet Mask (Class-C): 255.255.255.0
the drivers will require some configuration for the client and the server to be able to find each other.
Step 1: Make sure that port 1947 (used by the drivers) is not blocked by
any firewall. The drivers use this port to communicate with each other
and with the Intella application. Step 2: Ensure that the server and
client machines can ping each other. Step 3: Plug the network dongle
into the server. Make sure that the key is detected when viewing the
Admin Control Center on http://localhost:1947 on the server, like
this:
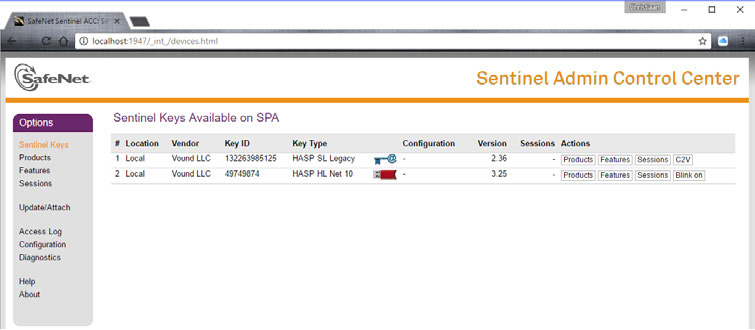
All network dongles show up as HASP HL Net… dongles in the Key Type column, with the number at the end varying (typically 10 or 50).
Step 4: On both the server and the client, do the following:
-
On
http://localhost:1947, click on Configuration. -
Select the Basic Settings tab, if that tab is not already selected.
-
Make sure that the Allow Remote Access to ACC checkbox is selected.
-
Click Submit if a change was made.
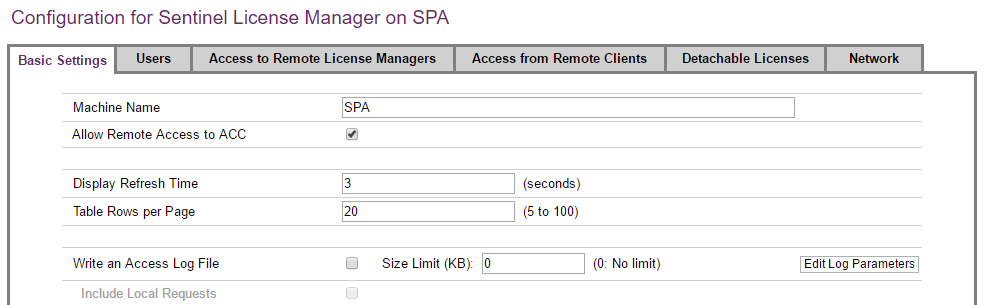
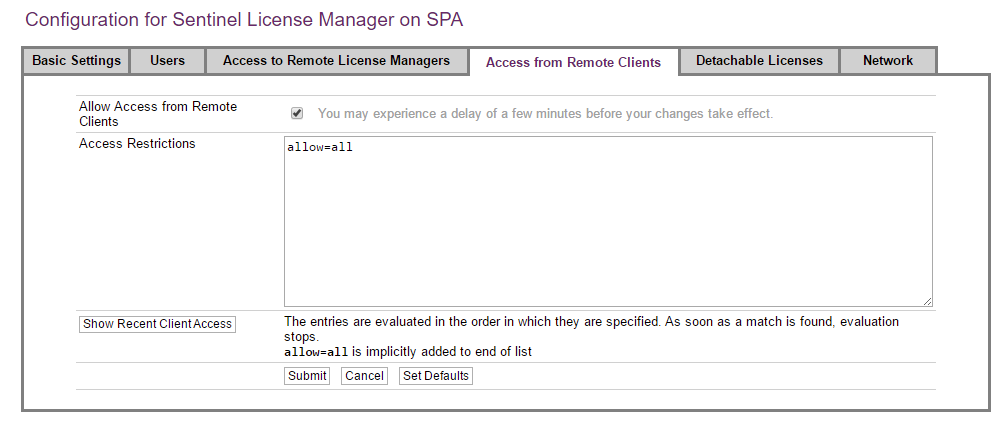
Step 5: On the server, do the following:
-
On
http://localhost:1947, click on Configuration. -
Select the Access from Remote Clients tab.
-
Make sure that the Allow access from Remote Clients checkbox is selected.
-
Click Submit if a change was made.
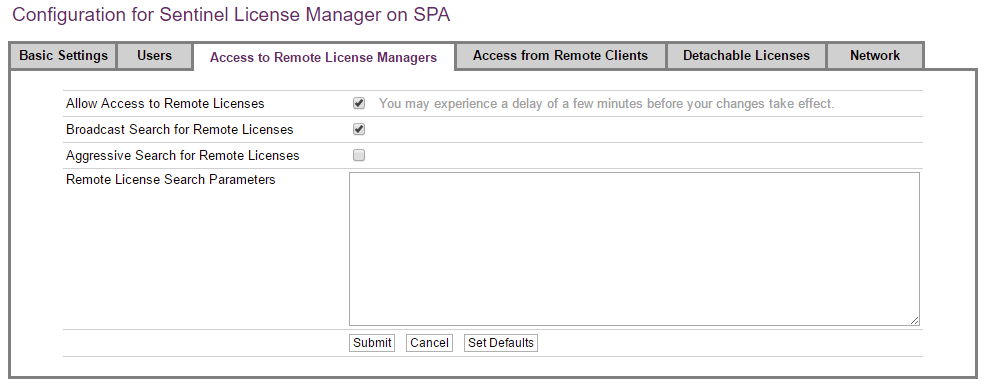
Step 6a: When client and server are on the same subnet, then on the client:
-
On
http://localhost:1947, click on Configuration. -
Select the Access to Remote License Managers tab.
-
Make sure that the Allow Access to Remote Licenses checkbox is selected.
-
Make sure that the Broadcast Search for Remote Licenses checkbox is selected.
-
Click Submit if a change was made.
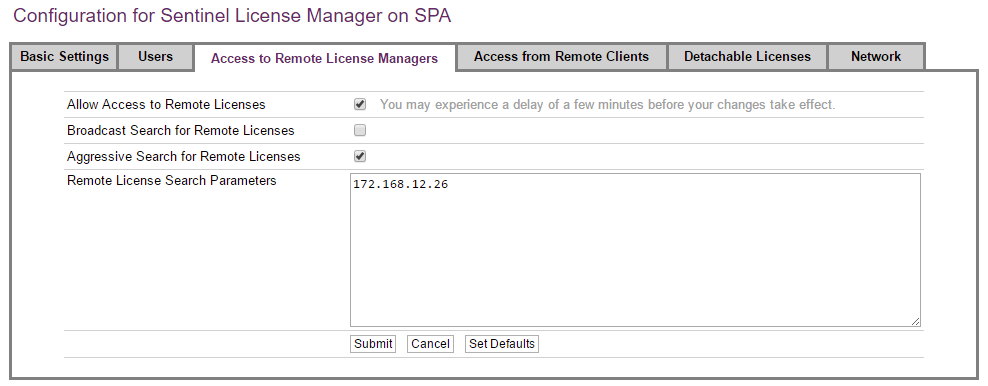
Step 6b: When client and server are on different subnets, then on the client:
-
On
http://localhost:1947, click on Configuration. -
Select the Access to Remote License Managers tab.
-
Make sure that the Allow Access to Remote Licenses checkbox is selected.
-
Make sure that the Broadcast Search for Remote Licenses is deselected.
-
Make sure that the Aggressive Search for Remote Licenses is selected.
-
Enter the IP address of the server in the Remote License Search Parameters box.
-
Click Submit if a change was made.
Step 7: Start a web browser on the client machine and open the following
URL: http://<server IP address/host name>:1947 In the example scenario
that would be: http://172.168.12.26:1947 Verify that you can see the
Admin Control Center and that the network dongle is listed. This
verifies that the client and server can communicate properly. You should
now be able to start Intella on the client, using a license from the
network dongle. You can verify this by checking the Case Manager window;
it should list the network dongle’s ID:

6.4. Preferred dongles
For users having more than one dongle with Intella Connect licenses, starting Connect will use arbitrary dongle. In a similar way, if the dongle in use is unplugged, Connect will switch to another arbitrary dongle with Connect license. If use of specific dongle would be preferred, then Intella Connect can be instructed to prefer license from particular dongle with dongle ID.
You can specify the dongle ID by adding the PreferredLicenseIds entry
in user.prefs file located in:
%USERPROFILE%\AppData\Roaming\Intella Connect\prefs
If the preferred dongle won’t be found, then Intella Connect will look for arbitrary dongle.
For example: PreferredLicenseIds=12345
Optionally, multiple dongle IDs can be specified, divided by comma, which will result in Intella Connect preferring first dongle from the list. If the first dongle is not available, it will try to use second dongle from the list and so on. In a similar way, if Intella Connect will be using second dongle from the list and first dongle will become available (by for example plugging in the dongle or fixing network connection), then Intella Connect will stop using second dongle and use first dongle. If none of the preferred dongles won’t be found, then Intella Connect will look for arbitrary dongle.
For example: PreferredLicenseIds=12345,12346,12347
7. Intella Connect Dashboard
The Intella Connect Dashboard is the administrative part of Intella Connect and enables the administrator to share cases, define users, index cases remotely, view the activity stream from shared cases and modify the general settings of Intella Connect.
7.1. Toolbar
Clicking on the user’s name in upper right corner allows user to change the password or log out from Intella Connect:
To change password, select Change password from the menu.
Once the password fields are filled in, click on the Set button to
change the user’s password. After changing the password, you will be
asked to log in with new password.
|
Passwords can be generated by clicking on the |
The left-side menu divides the administrative part into the following parts:
7.2. Cases
The Cases view contains following subviews:
-
List view
-
Activity view - gives detailed view about the activities performed by users logged into a case.
The List view shows the list of cases prepared by the Intella desktop product or Intella Node. For each of the cases it also shows its status, which can be:
-
not shared: the case is not shared.
-
shared: the case is currently being shared and accessible by reviewers.
-
indexing: the case is currently being indexed by one of registered Intella Nodes.
-
indexing finished: the indexing operation has finished and case is still open by Intella Node.
-
converting: the case is currently being converted by one of registered Intella Nodes.
-
conversion finished: the conversion operation has finished and case is still open by Intella Node.
-
locked: the case is currently used by another Intella process, e.g. the Intella PRO desktop application.
|
A case can also be without a status, which means that it is not available. The reason for this can be that the directory where the case files used to be, is no longer accessible. |
Clicking on a case shows its details on the right side, along with a set of buttons depending on status of the case:
-
Share: shares the case, which will be accessible via the URL shown in the
Case URLfield in the case details. -
Authorizations: allows to assign users to various roles.
-
Stop sharing: stops sharing of the case (visible only for shared cases).
-
Delete case: removes the case from the list and optionally also from the disk.
-
Convert: allows to convert a case to a newer format supported by the current version of Intella Connect (visible only if a conversion is required and possible, see note below).
-
Sources: opens up Sources page where sources can be added, removed and (re)indexed.
|
Before attempting case conversion please check if evidence files are available in correct location. See Sources section for details. |
7.2.1. Creating new case
Creating a new case in Intella Connect is straightforward.
After pressing Create case button located at the top of the cases list
the Create case dialog will be shown.
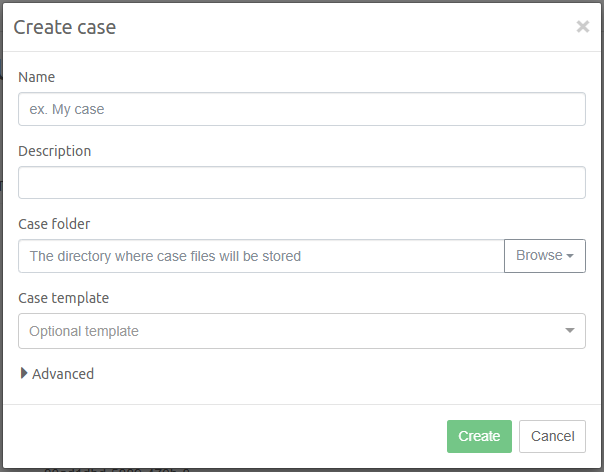
Please populate the form with case name, case description (optional) and desired path to the case folder.
You can paste the case location from clipboard or click on browse button to open a file system browser which allows for manual selection of case folder. If case folder cannot be used (ex. due to lack of file system permissions), detailed validation warnings will be presented. An empty folder is expected when creating a new case, which can be created by clicking on New folder button, if it was not created beforehand.
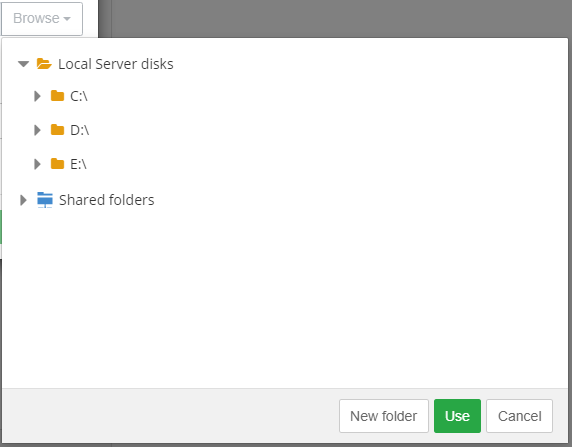
Optionally, you can specify the case template which will be used to initialize the case.
By expanding Advanced panel you can get access to additional configuration options. Setting the optimization folder can be used to speed up indexing by distributing certain database files during indexing across the case folder drive and the optimization folder drive.
|
Assuming that Intella Node is installed on different computer than the one running Connect, it is possible to have Case and Optimization folders reside on computer which is running Connect. You will need to use network path instead of local path to be able to index evidence which does not reside on local disk with Intella Node. To be precise, you will need to use network path when creating case (Case folder field and Optimization folder field are the ones, which will need network path). |
After you’ve entered all data, press Create button. You will be
presented with Sources page of newly
created case where you will be able to add and index newly added
sources.
7.2.2. Adding an existing case to the list
If you have existing case on the disk which is accessible to Intella
Connect, then you can manually import it to the available cases list. In
order to do that you will have to provide a path to the Case Folder
(parent folder of a case.xml file).
Click on the Add case button located at the bottom of the cases list.
In the modal window, please type in the absolute path to the case
folder. It’s the best to copy and paste it directly from Windows
Explorer window. The server will then analyze provided path and if the
case is found in that location, it will render basic details about the
case. This is presented on the image below. If provided path is invalid,
then appropriate message will be shown.

|
Case with same location cannot be added multiple times. In an attempt to add case to the list when case with same location is already present in cases list, a message will be shown highlighting the case with same location. |
Intella Connect can also be configured to add cases automatically. For more information see General settings section.
7.2.3. Deleting an existing case from the list
Click on the Delete case button located at the bottom of the selected
case details panel. In the modal window, leave the checkbox empty if the
case should only be removed from cases list. Check the checkbox if the
case should be removed from cases list as well as from disk.
7.2.4. Case Sources management
You will be presented with this part each time new case is created or after Sources button in the case details panel is clicked.

Using this view it’s possible to:
-
Add new sources.
-
Edit sources.
-
Remove sources.
-
Re-Index entire case.
-
Index new data.
-
Import an overlay file.
-
See overlay file import statistics.
-
See latest indexing statistics.
-
Finish source management operation.
7.2.5. Case Templates
A case template is a collection of configuration settings, preferences and case metadata that can be exported from an existing Intella case and re-used for the creation of other cases. Case templates allow for initializing new cases quickly with predefined sets of tags, keyword lists, tasks, column settings, etc.
You can manage case templates in a dedicated view accessible under Cases / Templates. It allows for:
-
Creating a new template, created from an existing case.
-
Importing an existing template from Intella Case Template ("*.icf") file
-
Deleting case template
-
Browsing contents of the case template
Creating a case template
To create a new template click on the Create button. This opens a modal window where you can specify for which case you want to create template, as well as the path and name of the Intella Case Template file. Please note that you can only select cases which are not currently shared. If you want to create a case for currently shared case, please unshare it first. This modal also allows you to choose components to include in the template. This is illustrated below:
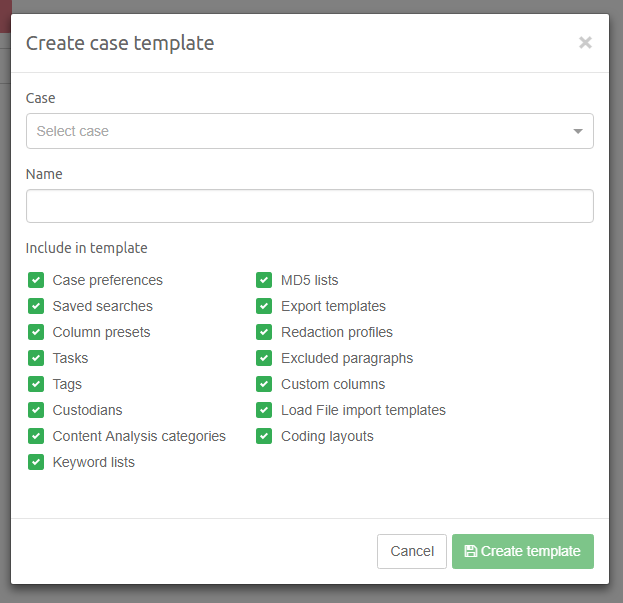
The available template components are:
-
Case preferences - this component also includes the number of crawlers and service memory settings.
-
Saved Searches
-
Column presets
-
Indexing tasks
-
Tags
-
Custodians
-
Content Analysis categories
-
Keyword Lists
-
MD5 lists
-
Export templates
-
Redaction profiles
-
Excluded paragraphs
-
Custom columns
-
Load File import templates
-
Coding layouts
|
Few of components listed above are derived from standalone Intella products and may not have graphical user interface which would allow to change them in Intella Connect. They may be included in the case template though, to preserve interoperability between both tools. Examples are: Case preferences, Column presets. |
Press the Create template button to create the template and add it to list of available case templates.
Using a case template
To apply a template when creating a new case select it in the Case template dropdown in the Create case dialog.
Importing a case template from file
Press the Import button to open the Import existing case template modal window. Provide a name of the template and select the Intella Case Template file from local file system. After pressing Import button, the file will be uploaded to server and this template will be added to the list of available templates.
Deleting a case template
To delete existing case template first select it in the dropdown of available templates. Then press Delete button. The following dialog will ask you for confirmation if you want to proceed with deletion, as this action cannot be undone.
Browsing contents of a case template
To see what case template contains, simply select it from the dropdown list. This will automatically populate the view with components included in this template.
7.2.6. Case Merging
You can merge two cases in a dedicated view accessible under Cases / Merge, as illustrated below:
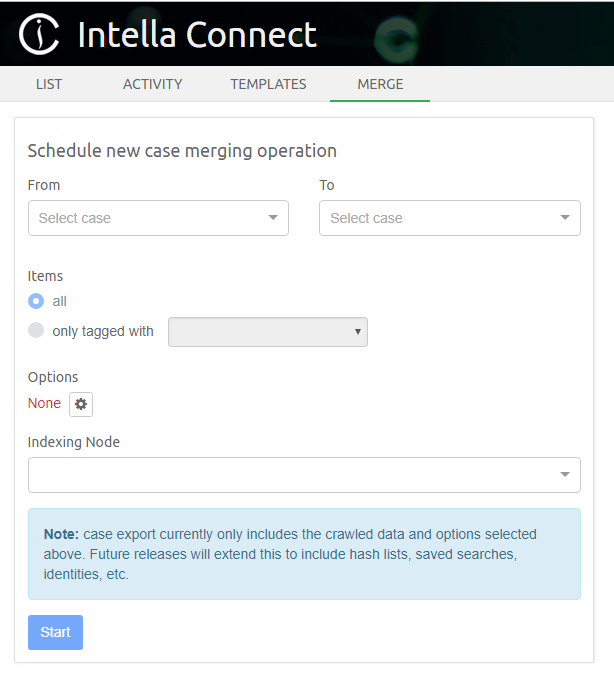
Items in a case can be exported to another case. We refer to these as the source case and target case, respectively. This functionality supports several use cases:
-
Exporting selected items to a new (and empty) case, e.g. to filter privileged information or irrelevant items, or to divide the work among reviewers in such a way that each reviewer only has access to their own assigned subset.
-
Merging of two or more cases to create one unified case, or to import the work done on a previously exported case back into the main case.
When items are exported to another case, Intella will add the related sources to the target case, and the items will be added to those new sources. However, when the target case is a copy of the source case, or if items from the source case were exported to the target case before, then the target case can already contain these sources. In such cases Intella will add the exported items to the existing sources. Any items that already exist in the target case will not be added again. Subject to the selected export options, the associated data like tags and comments will be copied though.
Exporting items to a case will increase the registered case size of the target case. Intella calculates the increase based on the size of the selected items and their (recursive) parent items, as far as these contributed to the case size of the source case. For example, exporting a set of email items from a PST file that was stored in a crawled file system folder will increase the size of the target case with the size of that PST file. When the to-be-exported items were indexed with Intella 2.1.1 or older, the required information is not available though, and Intella will add the full size of the source case to the target case instead.
|
The size of the target case after export cannot exceed the limit imposed by your current Intella license. |
| When the Intella case that is being exported to is re-indexed later, the evidence files referenced in the sources involved in the export will be re-indexed completely (provided that the evidence files are available). As a result, you may end up with a case that has all of the data that was in the original case that you exported from. This is a limitation that will be addressed in a future Intella release. |
You can export either a subset or all items from selected case. To export a subset of items to another case, use the following procedure (if you want to export all items skip to next list of steps):
-
Open a shared case from which you want to export items.
-
Run a query that contains all the to-be-exported items and tag them with a tag of your choosing.
-
Unshare this case.
-
From Admin Dashboard navigate to Cases / Merge.
This view allows to schedule a new case merging operation. In order to do this:
-
Select Source and Target cases using two dropdown lists (see note below on which cases can be used).
-
Select which items you want to export. If you want to export a subset of items, select a tag using dropdown. This will cause only items tagged with selected tag to be exported.
-
Select at least one merging option using the modal window (see next paragraph for details).
-
Select an instance of Intella Node which is currently available to accept an indexing operation.
-
Press Start to begin merging operation.
|
Source and Target cases must not be shared, indexed or locked by any other instance of Intella. |
Case Merging Options
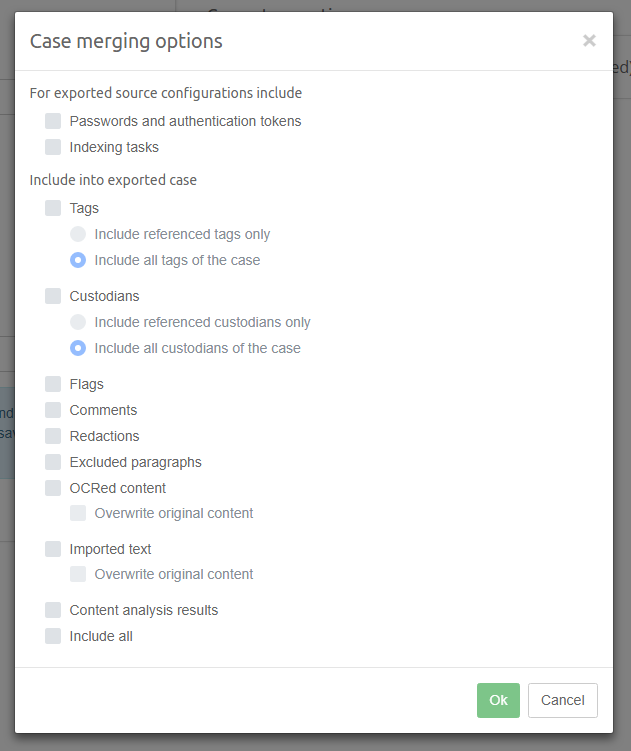
This modal window allows you to specify which information should be included in the export, along with the item content:
-
Passwords and authentication tokens that are stored in source configurations (IMAP, iCloud, etc.). When these are not included in the export, the source cannot be re-indexed in the target case.
-
Indexing tasks defined in source configurations.
-
Tags that are referenced by exported items, or the complete tags hierarchy defined in the source case.
-
Custodians that are referenced by exported items, or all custodians defined in the source case.
-
Flags.
-
Comments.
-
Redactions.
-
Excluded paragraphs.
-
OCRed content, with an option to overwrite existing OCR content in the target case for exported items that already exist in the target case.
-
Imported text, with an option to overwrite existing imported text in the target case for exported items that already exist in the target case.
-
Content Analysis results.
|
The case export currently only includes the crawled data and the options shown above. Also, the timestamps of exported annotations are not yet preserved; their timestamps will be the time of export. This will be extended and improved in future releases. |
Locking and closing cases
During case merging Intella Connect will open and lock both Source and Target cases. Once the operation finishes (either with success or error) both cases will be closed and the Target will get unlocked. However, the Source case will still be locked. In order to unlock it you need to click on the Finish case merging in the case details panel.
|
Requirement for manual closing of Source case may be removed in future versions of the software. |
Item stubs
When exporting items to an Intella case, Intella Node will export only the items that are in the current selection. If you want to export emails with their attachments, you must include the emails and all their attachments in the selection for exporting.
This functionality therefore allows for specific items to be excluded. E.g., if an email has an attachment and that attachment is privileged (should not be included in the export), the email can be exported without the attachment by simply exporting only the email itself. Note that the binary file associated with that email will still contain the attachment in binary form though! This is therefore not a secure way of filtering out all privileged information.
When items are exported without their parents, their parents will still be represented in the target case by item stubs. These stubs are necessary to show the context of the exported item. An item stub contains a minimal set of metadata of the original parent item, such as its name, location and type.
Intella will record the start and end of the export process in the event logs of both the source case and the target case. Besides the user and timestamp, these events record:
-
The Case ID of the case that the items were exported to/imported from.
-
The Case name of the case that the items were exported to/imported from.
-
A unique Event ID that can be used to identify corresponding import and export events in source and target cases.
Tracking case merging progress
Once case merging operation starts you will be able to track its progress in the details panel on the right. This panel, once expanded by clicking on the arrow icon, will show detailed progress of each step of case merging operation.
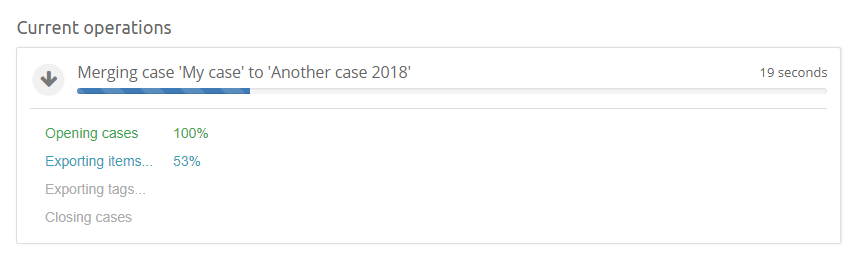
7.3. Remote servers
7.3.1. Intella Connect Grid
If you are running more than one Intella Connect servers then likely you could benefit from configuring them as a part of the same Grid. This feature allows reviewers to have a single point of entry to all Intella Connect servers. This simplifies case management in larger organizations, as reviewers do not need to be aware which Intella Connect server is hosting the case.
For this feature to work, each server forming a Grid must have LDAP integration enabled. This is required to establish a consistent user base for each of the servers.
|
Each server in Intella Connect Grid must be configured to reuse the same LDAP provider. Not doing so can lead to potential authentication/authorization conflicts. |
It’s imperative to manually pick one server which will act as a single point of entry for the Grid and apply any configuration there. Other Grid servers do not need to be further configured (assuming that LDAP configuration was already applied).
It’s common in networking to identify servers interchangeably by their IP, domain or network name (ex. IP 1.1.1.1 matching pc1.mycompany.com). However when Intella Connect server is being added to the Grid only one URL will have to be provided and will be used as a unique identifier of the server. For security reasons these URLs will be used internally to validate the origin of requests accepted by Grid servers. Therefore the grid might not work properly if you set up a server using it’s IP address and then later are accessing it using its domain name.
|
When adding a server to "Known servers" list make sure to use the URL under which it will be accessible to reviewers. |
The same rule applies to the server which acts as a single point of entry. You must make sure to apply any grid configuration using the URL which will later be used to access user dashboards.
|
When user is accessing his dashboard he will see all cases in Grid which are currently shared with him. If he decides to open one, he will still be redirected (HTTP 302) to the appropriate server. The data hosted by servers is not proxied through the server which acts as single point of entry. This is deliberate behavior which means that at all times reviewers need to be able to communicate with grid servers on a network level. |
Example
This example will walk you through the hypothetical use case of setting up Grid in a company distributed across three continents. It gives you some general guidelines how to approach this task and stresses points which should be discusses with your IT department.
Let’s say that we have three Intella Connect servers running in our company. Here are their details:
-
Server1; IP=1.1.1.1; domain=connect.mycompany.com; Location: London
-
Server2; IP=2.2.2.2; domain=newyork.mycompany.com; Location: New York
-
Server2; IP=3.3.3.3; domain=sydney.mycompany.com; Location: Sydney
Until now there was no strict policy as to how to access those servers so users were using different mix of IPs or domains. The first step is to define a scheme of addressing our servers. We decided to rely on domain/subdomain names as IPs are too fragile to rely upon them. We also decided to promote the Intella Connect server located in London to become our single point of entry. We also asked our IT department to disallow direct access to server by IP (as an additional precaution).
In the next step we went through all three servers and made sure that each one of them is using the same LDAP provider. It turned out that the one in New York had a bunch of local accounts which were interfering with LDAP (username clashes) so we decided to clean this up and create LDAP accounts for those people.
After that we logged in to connect.mycompany.com (entry point) to set up Grid there. Under Remote Servers > Intella Connect Grid > Known servers we added the remaining two servers. The first one as:
-
Name: New York
And the second one as:
-
Name: Sydney
Right after that they were added to Known Servers list with the online status.
We then validated the setup by sharing 1 case on each of the servers and logged in to User Dashboard on the server which we chose as single point of entry (http://connect.mycompany.com). User was successful presented with a list of cases showing three entries.
7.3.2. Intella Nodes
Intella Connect can make use of unlimited number of remote Intella Nodes to perform remote indexing. For installing and setting up an Intella Node please see Getting started section.
|
One Intella Node license is needed for each running Intella Node instance. |
Using this view it’s possible to add/edit/remove remote Intella Nodes that can be used to perform remote indexing.
Make sure that remote Intella Node server is properly running and is directly accessible via network on particular IP and port.
Intella Node’s local status page shows detected host name and port, which can be used when adding new Intella Node.
The IP address that is being detected by Intella Node can be just one of addresses on which that computer can be reached and it might not be always the best one to use. There are few examples that come to mind:
-
your computer can have multiple networking interfaces, such as 1Gb/s TP (twisted-pair) ethernet network card and WI-FI network card. If you would connect both of those to different routers or switches, then your computer will be assigned two IP addresses and you can be reached by either of those. In this case you might want to use IP address assigned to the cable-connected network card rather than WI-FI as it might be faster. It could happen, however, that the IP address shown as detected is the one from your WI-FI network card.
-
a router or switch to which your computer is connected can be configured to have multiple subnets. That means that the IP address and network mask will depend on the interface to which you are connected on that router or switch. Not much to do here unless you are also network administrator and you understand how the router was configured and how the computer is connected.
-
your computer can be reachable on multiple IP addresses and ports even if you have just one network interface connected in your computer. For example: localhost:9999 or 127.0.0.1:9999 (also known as loop-back interface, which points to your own computer), 192.168.1.109:8082 (your local network on your directly connected router), 192.168.0.159:8081 (your company network on your second hop router), 85.74.198.115:80 (your public address). In this case you might want to use IP address which will make least hops on the route to server.
Please note that these are only simple scenarios and there can be much more complex network topologies and configurations. It really depends on what network you have and how it is built and configured. The detected IP address is being read from system configuration, it is not an algorithm that would detect your network and perform speed and reliability measurements to determine what exact address to use. It is meant to be a hint rather than anything else. When in doubt about which IP address to use, please consult your IT/network administrator.
When you have gathered all relevant data (host, port) you can add new remote Intella Node by clicking on the plus sign when hovering mouse over UNUSED remote Intella Node slot.
The Intella Node can now be added in place of the UNUSED slot.
Enter name, description (optional), host, port and enable the use of HTTPS if SSL is configured for this Intella Node. After pressing Add Node the Intella Node will show up in the remote Intella Nodes
list with status Connecting… which indicates that there is a check being made whether remote Intella Node is up and running and is reachable.
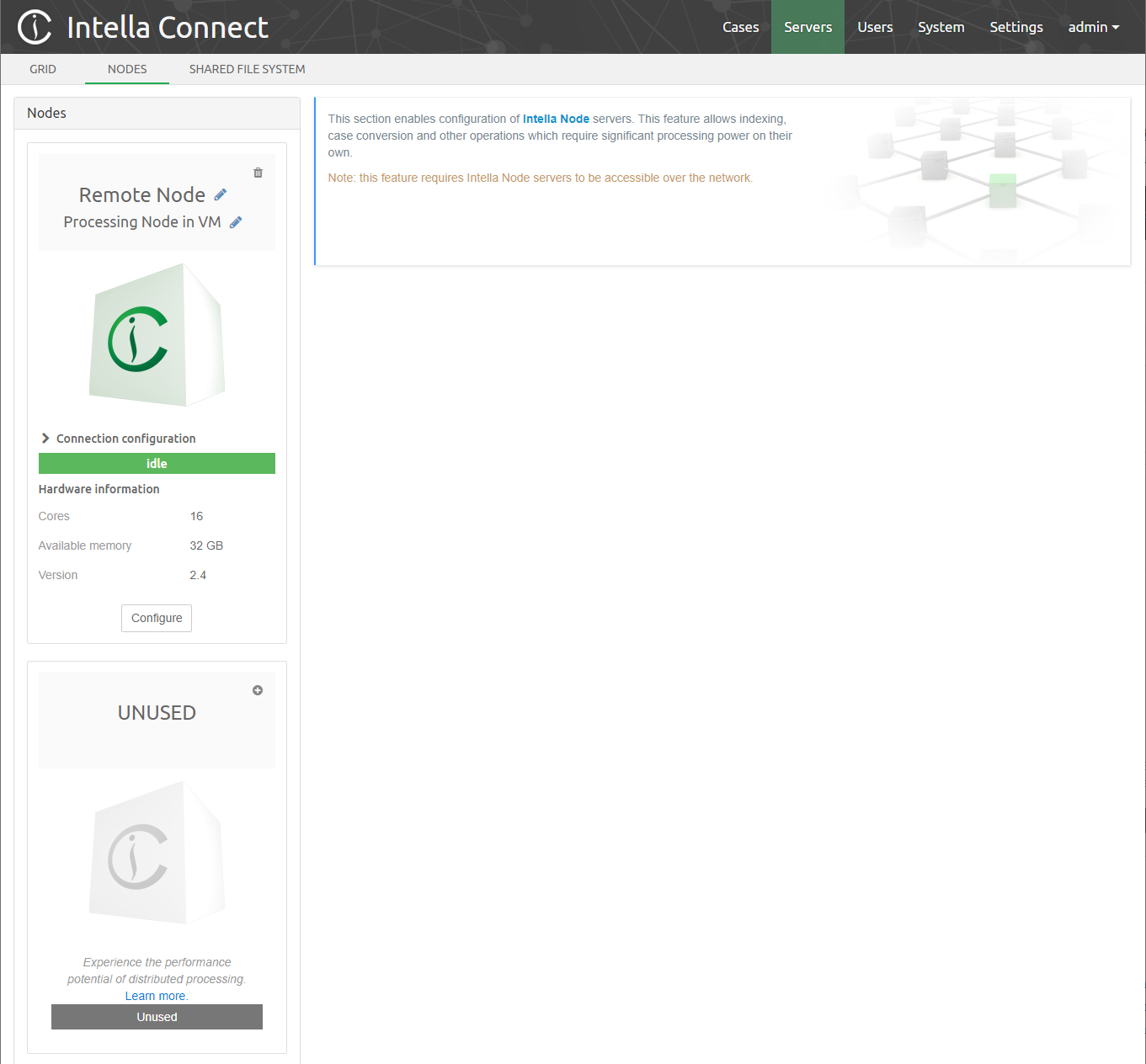
If all entered data were correct and remote Intella Node server was reachable the status of the newly added Intella Node should be Idle which indicates that Intella Node is ready to be used for remote indexing. Connection error status indicates that server is not reachable. If that happens you should check whether:
-
Remote Intella Node is properly running which can be done by opening it’s local page.
-
Entered data (host, port) were correct.
-
Remote Intella Node server is reachable from Intella Connect Server.
Click on Configure button to show configuration that can be changed on selected Intella Node.
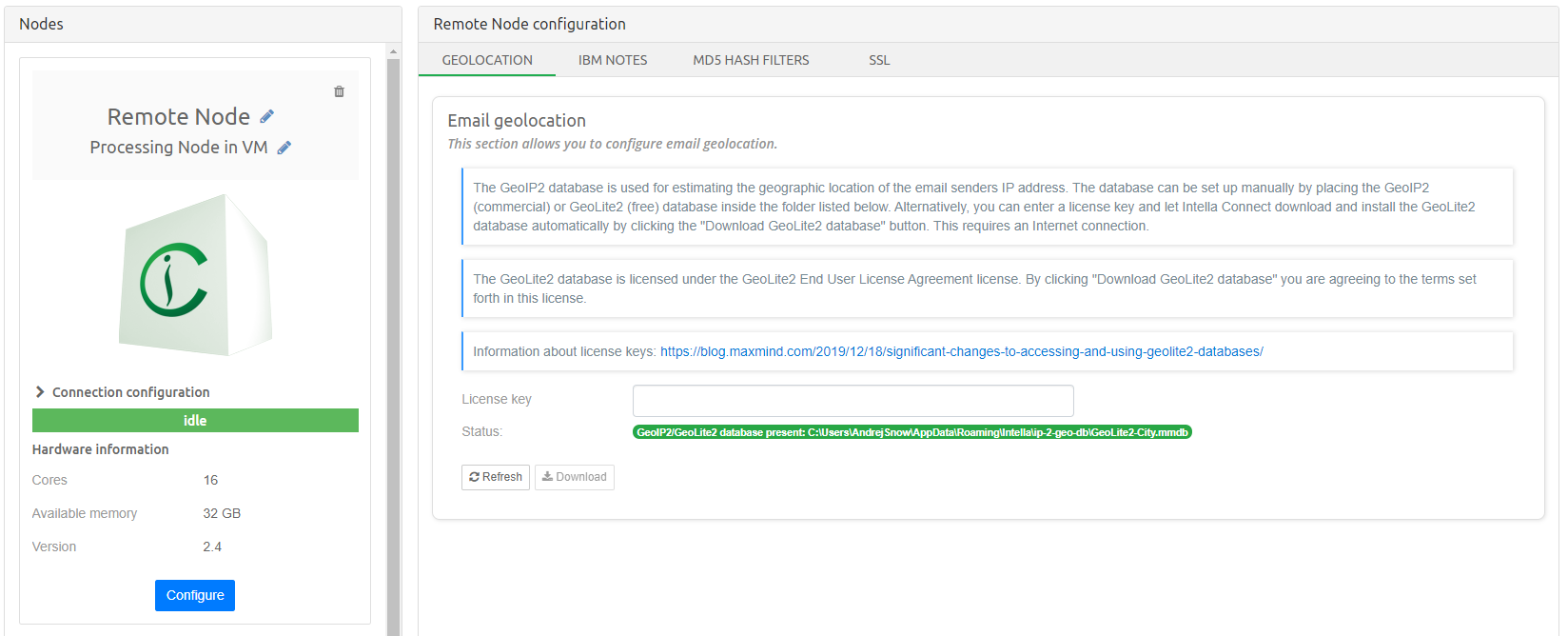
It consists of following sections:
-
Geolocation - allows configuration of email geolocation capability during indexing - see section Email geolocation
-
IBM Notes - IBM Notes configuration which allows indexing NSF files - see section IBM Notes
-
MD5 Hash Filters - can be used to exclude items that have a specific known MD5 hash from a case during indexing - see section MD5 Hash Filters
-
SSL - configures the server so that it uses secure HTTPS protocol for communication - see section Enabling HTTPS support on Intella Node
7.3.3. Shared folders
Shared folders management is actually a way of logically organizing shared folders that are based on UNC paths.
Each defined folder represents specific type of location:
-
Evidence location - folder where evidence resides.
-
Cases location - folder where cases reside.
-
Optimization location - folder used for optimization.
-
Configuration location - folder used when configuring paths to various resources.
When such Shared folders are defined, the user is able to access them in a file selection tree under Shared folders branch next to Local Server disks.
|
Folders that represent Evidence location will be shown only when adding new sources, folders representing Cases location will be shown when creating new case, folders representing Optimization folder will be shown when selecting optimization folder and folders represeting Configuration folder will be shown when configuring paths to various resources, for example MD5 hash filters. |
To add a new shared folder, click Add shared folder
Enter name, description, UNC path and select type of the location that folder represents. After pressing Add Remote folder will be added to the list of the Remote folders.
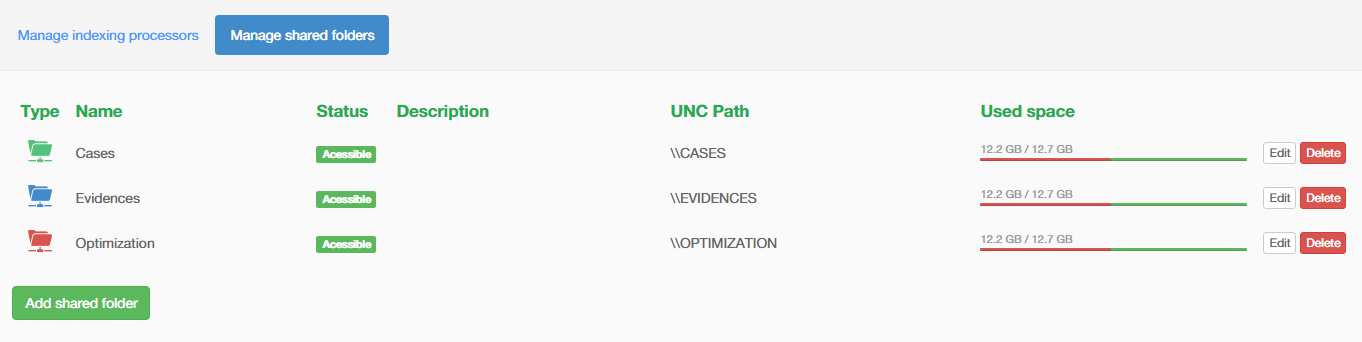
You can see Shared folders in action on this particular screenshot:
Note that only Shared folder "Cases" representing Cases location is shown when specifying Case location in order to prevent selecting folders representing other locations (Evidence location, Optimization location or Configuration location).
Troubleshooting shared folders
When creating shared folder of type "CONFIGURATION" in version 2.4 of Intella Connect, then shutting it down and starting version 2.3.1 or earlier of Intella Connect will cause the following:
-
Shared folders view will be empty - it will show that there aren’t any shared folders configured.
-
Logs contain following error:
java.lang.IllegalArgumentException: No enum constant com.forensicsmatter.intella.server.admin.model.SharedFolder.Type.CONFIGURATION
The solution is to remove shared folder of type "CONFIGURATION" prior to switching to earlier version of Intella Connect.
7.4. User management
This part is explained in the User management section.
7.5. Settings
This part lets the administrator configure certain aspects of Intella Connect server and external systems it may integrate with. It consists of five sections:
-
General - controls general server behavior
-
Branding - allows to add customized/branded logos to appear in several parts of the UI
-
SSL - configures the server so that it uses secure HTTPS protocol for communication
-
LDAP - allows integration with an LDAP compliant server (ex. Active Directory)
-
ABBYY - configures an external OCR server
Each of these sections are further divided into smaller subsections and grouped by settings which affect similar features. For example, General section allows to configure Case sharing and default Admin password independently.
Each section of settings offers independent Apply and Discard buttons. Those buttons will became active once a change to settings is detected. A rule of thumb is that changes are not persisted unless you commit them by clicking Apply button.
Most of inputs render an auxiliary Information Icon which, when hovered over, will show additional hints about specific setting.
|
Intella Connect will try to guard you from accidental loss of unsaved changes by showing a warning when you try to navigate away from the current view. In such case you should discard or apply your changes. |
7.5.1. General
Case sharing
Changing server host
By using the checkbox Override server host in case URLs and text field
Server host it is possible to change how Case URLs are constructed in
the Cases List screen.
|
Overriding the server host only changes how Case URLs appear in the
cases list. It has no effect on your networking settings. Depending on
your network infrastructure such Case URL might still not be accessible
due to the router configuration. For example, when you own a certain
domain name, setting |
Case auto discovery folder
This option allows you to make Intella Connect automatically discover cases available in a specified local disk folder. To enable this feature, simply enter an absolute path to the folder that might contain case folders.
Intella Connect will check this folder every 15 minutes to find new
cases (discovered by the presence of a case.xml file) and
automatically add them to the available cases list. It will also scan
the disk each time that you change this path.
For performance’s sake, Intella Connect scans files three levels deep
starting from the provided folder. You can increase this depth to any
value you like by adding the CaseAutoDiscoveryDepth entry in
user.prefs file located in:
%USERPROFILE%\AppData\Roaming\Intella Connect\prefs
To prevent access denied errors, Connect will by default skip scanning
following folders: $RECYCLE.BIN, System Volume Information. You can
specify path prefixes to exclude from scanning by changing the
CaseAutoDiscoverySkippedDirs entry in user.prefs file located in:
%USERPROFILE%\AppData\Roaming\Intella Connect\prefs Multiple path
prefixes need to be separated by comma.
To turn off this feature simply change the path to a blank value.
|
Disks are usually the main bottlenecks in hardware setups that we are usually dealing with. Adding a case usually happens rarely, so we do not recommend sacrificing even a tiny bit of a reviewing performance for it. Therefore we don’t encourage you to make use of this option unless it’s absolutely critical to your workflow. You can always consider switching it on and off depending on requirements. |
Changing default admin password
This section allows to change the default password used by an admin account.
Current password
For security reasons, specifying the current admin password is required. By default this equals to 'admin'.
New password and Repeat password
These fields represents the new desired admin password. Values entered must match in order to eliminate typographical errors.
Locale
The Locale section allows configuration of page format.
The Page format lets you select which paper size to use when exporting to PDF. Available options are ISO A4 and US Letter.
|
When printing item from previewer by clicking on Print button, then the page format is driven by paper size chosen in browser print dialog. |
7.5.2. Login Page
This section lets the administrator configure these two aspects of the login page:
-
Custom messages to be shown on the login page next to the login form
-
Custom links to be shown at the bottom of the login page
Login page messages
Here you can define a custom message that will be shown on the login page.
In order to create a new message, press on Add message button.
This will instantly create a new entry and place it at the bottom of the current custom messages list.
After creating a new custom message, following fields needs to be defined:
-
Message type:
-
Default: Renders message using black text.
-
Info: Renders message using blue text.
-
Warning: Renders message using orange text.
-
-
Start date (optional) - defines the date on which the message should be shown.
-
End date (optional) - defines the date after which the message should be hidden.
-
Message - defines message body.
-
Enabled - defines whether this message should be visible.
| The order of custom messages can be changed by simply dragging them to the desired place. |
Custom links
Here you can provide a custom links that will be shown on the login page. Custom links can point to either external page or custom HTML content.
Custom link
In order to create a new custom link pointing to external content simply click on Add link and populate the following fields:
-
Label - this is link text that will be shown.
-
Link - URL pointing to the external content.
-
Enabled - controls whether link should be visible.
Custom content
In order to create a new custom content, press on Add HTML content button and populate following fields:
-
Label - this is link text that will be shown.
-
HTML File - upload desired HTML file.
-
Enabled - controls whether link to HTML file should be visible.
| The order of custom links can be changed by simply dragging them to the desired place. |
7.5.3. Branding
Intella Connect can be partially or fully branded with a custom logo of your choice. The process of setting this up is pretty straightforward. It’s just the matter of uploading image files. You can also optionally align the logo appearing in the Intella Connect header, so that it appears in the correct location.
You can find more details on this topic in Branding section.
On login page
This logo appears on the login page, where user signs in to application.
In application headers
This logo will be shown in the Intella Connect header (top of the screen), as well as in various places inside the application’s User Interface.
Header logo alignment
By adjusting the value in this field you can control the vertical alignment of the logo located in the header.
|
This feature will be enabled only for users having extended Intella Connect license. Please contact your sales representative for details. |
7.5.4. SSL
Intella Connect supports protecting your server with a secure HTTPS communication layer. The details on how to set it up is a part of a separate guide available in SSL setup guide section.
7.5.5. LDAP
Intella Connect can be integrated with an LDAP server. This integration allows for the user base available in LDAP being used by Intella Connect. The details on how to set it up is a part of a separate guide available in the LDAP setup guide section.
7.5.6. ABBYY Recognition/FineReader Server
When you have access to an ABBYY Recognition Server, or its successor ABBYY FineReader Server, you can utilize it to OCR selected items in the case fully automatically. The configuration specified here will apply to all cases shared by this Intella Connect server.
|
ABBYY Recognition Server 3.5 or 4.0, or ABBYY FineReader Server 14, should be used. |
Before attempting to configure this section, please make sure that your ABBYY Recognition Server is configured correctly:
-
The Web Service component is installed and configured properly.
-
You can open the Service URL in a browser and it shows: RSSoapService. The following operations are supported….
-
The latest versions of FineReader Server come with a demo app that can be used to test whether the web service component is installed and configured correctly. Open the following web page and enter the fields to test the API:
http://SERVER_IP:PORT/FineReaderServer14/demo/
-
A separate document should be generated for each input file.
-
The output format is a format that Intella can index.
-
The following parameters need to be set correctly in the following file
(suggested parameters allow for processing files up to 30 MB):
C:\Program Files (x86)\ABBYY Recognition Server 3.5\RecognitionWS\web.config
Parameters:
<?xml version="`1.0`" encoding="`UTF-8`"?> <configuration> <system.web> <httpRuntime maxRequestLength="`409600`" /> </system.web> <system.webServer> <security> <requestFiltering> <requestLimits maxAllowedContentLength="`300000000`" /> </requestFiltering> </security> </system.webServer> </configuration>
If the FineReader Server is configured to use a non-standard port such as 8080, do NOT include the port in the "Server IP address" field. But instead click on the "Use custom service URL" checkbox and add the port directly after the IP address. For example: Server IP Address: 192.168.0.1 and Service URL: http://192.168.0.1:8080/FineReaderServer14/WebService.asmx.
|
Host
IP address of machine hosting ABBYY Recognition Server. The Service URL field will be populated automatically based on the entered value.
Version
The version of ABBYY Recognition Server installed. The Service URL field will be populated automatically based on the entered value.
Use custom service url
If you know that your server uses a different URL, you can override it by checking the Use custom service URL check box. This will cause the Service URL field to become editable.
Service URL
The value of this field will be automatically generated based on input in other fields. It should point to the appropriate SOAP service of the ABBYY Recognition Service.
Workflow name
Specify the workflow name that should be used. Alternatively, you can press the Get list from server button to select a value from all available workflows on that server. This button can also be used to validate connection to ABBYY -Recognition Server.
Number of workers
Specify the number of workers to let the Recognition Server process more than one document at a time. The optimal number of workers depends on the Server capabilities (in particular the number of CPU cores on the server) and is also restricted by the server’s license (the number of CPU cores allowed to be used by the Recognition Server license). The number cannot exceed 64.
See OCR section for more information about OCR.
7.6. About
This part shows information about the Intella Connect version that is used.
It also allows to generate a report listing server diagnostics and usage over past 12 months. This information is often handy when resolving support issues or determining overall system health. The report can be generated by clicking on the "Generate report" button, after which report will be downloaded as a regular text file. It contains basic information about the hardware hosting Intella Connect, number of shared (and active) cases, memory distribution, number of active users etc. It does not include any confidential, case-specific data.
8. User management
8.1. Admin user password
To change the admin user’s password, click on Settings in the top menu
in the Intella Connect Dashboard.
In section Admin password, the fields New password and
Repeat password are used to change the admin user’s password. For
security reasons, the field Current password must be filled. Once
these fields are filled in, click on the Change password button to
change the password. After clicking the button, the notification
Password changed successfully will be shown and you will be logged out
from the Intella Connect Dashboard. To log back in, please use admin
as user name together with the newly configured password.
8.2. Managing Users and Permissions - the RBAC model
For managing Authentication and Authorization Intella Connect uses a mechanism called Role Based Access Control (RBAC). To effectively manage user accounts and their permissions, it is advisable to get familiar with this mechanism. It is a very simple yet powerful tool, allowing for full flexibility in creating various levels of access restrictions.
Below we describe the key entities used in an RBAC model:
-
User (account) - represents a single person who has access to an application. Each user is identified by a unique username and password, which needs to be presented for authentication purposes. This is how Intella Connect is able to recognize their identity and determine what each one of them can or cannot do.
-
Permission - represents access to a given resource or operation, for example the ability to tag items, access to a case or to a specific item. Permissions can grant or prohibit access to a certain action. There are different types of permissions defined in Intella Connect. Administrators should get acquainted with them, because only then they will be able to properly manage access to various parts of Intella Connect.
-
Role - roles can be considered as a set of permissions with a unique name. Roles are defined by server administrators. There is no limit on the number of roles that can be created. A roles can have zero or more permissions assigned to them. Permissions assigned to a role effectively define what actions a user with a given role is entitled to.
|
RBAC gives Administrators unlimited flexibility in defining complex hierarchies of users closely matching their own organizations. However, we strongly recommend keeping the number of roles relatively small, so that the whole model remains manageable over time. |
For simplicity, managing user accounts has been separated from managing
roles and permissions. Both those features are accessible after clicking
on User management in the left side menu in the Intella Connect
Dashboard.

8.3. Create new users, modify and revoking existing users
To create new users, modify and revoke existing users, click on Users
in the top menu in the Intella Connect Dashboard.
|
Revoking of the user account will not result in such account being deleted which means that creating new user account with the same username will make revoked account active again. |
8.3.1. Create new user
New users can be added by clicking on the Add button.
|
Passwords can be generated by clicking on the |
Once the user name and password fields are filled in, click on the Set
button to add a user.
8.3.2. Usernames
Intella Connect uses case insensitive comparison for usernames. This means, that "Admin", "admin" and "aDmIn" are essentially the same user. In various places in the user interface the username will be rendered using a lowercase. The current set of acceptable characters in usernames contains of:
-
digits (0-9)
-
letters (a-z, A-Z)
-
the underscore (_)
-
the at sign (@)
-
a dot (.)
Usernames should be at least 3 characters long.
|
Despite the fact that Intella Connect renders usernames in lowercase, they are never modified when compared on the server (comparison simply ignores casing). Therefore Intella Connect is safe from issues that might be a result of lowercasing UTF-8 characters using custom system locale. |
8.3.3. Change user’s password
Select the user whose password you would like to change and click on the
Set password button.

Once the password fields are filled in, click on the Set button to
change the user’s password.
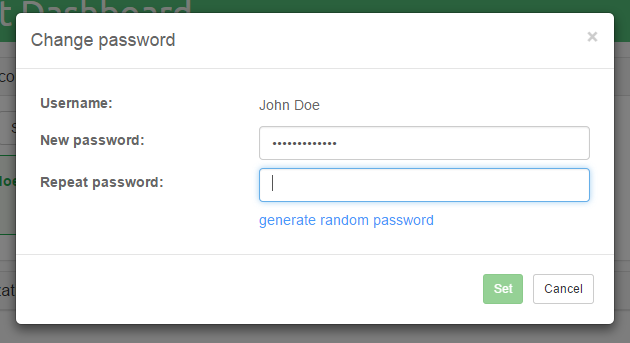
|
Changing a user’s password will take effect after the user’s session expires or when the case sharing is restarted. |
8.3.4. User’s authorized cases
Select the user whose list of cases (to which that user is authorized)
you would like to see and click on the See authorized cases button.
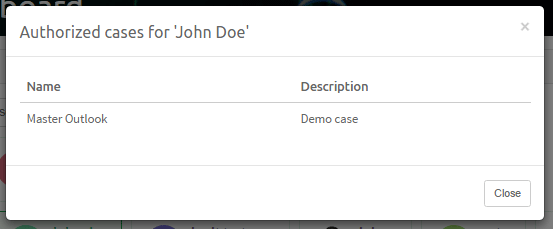
8.3.5. Revoking existing user
Select the user for whom you want to revoke access and click on the
Revoke access button.
After confirmation, the selected user will no longer have access to any part of the Intella Connect system.
|
Revoking a user’s access will take effect after the user’s session expires or when the case sharing is restarted. |
8.4. Managing Roles and Permissions
Intella Connect comes with a set of predefined permissions that can be assigned to any of the roles defined by the server administrator. It also comes with following default roles: Administrator, Reviewer, Senior reviewer, Investigator and Case manager. The default roles are added only when authorization configuration does not exist, i.e. auth.xml file does not exist and needs to be created by Intella Connect. If Intella Connect is being migrated to new version, then these default roles will not be added.
Backwards compatibility notes
If you are migrating from previous versions of Intella Connect 1.7.x, the Reviewer role will be created for you and assigned to all the users that previously had access to a particular case. This means that you will not have to perform any manual actions yourself when upgrading to Intella Connect 1.9.1.
If you are migrating from previous versions of Intella Connect 1.8.x, the Administrator role will be created for you and assigned to the "admin" user that previously had unrestricted access to Intella Connect Dashboard. This means that you will not have to perform any manual actions yourself when upgrading to Intella Connect 1.9.1 and you will still be able to login using "admin" account as you used to with earlier versions.
If you are migrating from previous versions of Intella Connect 1.9.1, all users having "HAS_ACCESS_TO_A_CASE" permission will be granted with following permissions automatically:
-
CAN_USE_DASHBOARD_UI
-
CAN_USE_SEARCH_UI
-
CAN_USE_REVIEW_UI
If you are migrating from previous versions of Intella Connect 2.0.0, all users having "CAN_EXPORT_ITEMS" permission will be granted with the "CAN_DOWNLOAD_ORIGINAL_ITEM" permission automatically. Moreover, users with "CAN_CREATE_BATCHES" permission will be automatically granted with "CAN_MANAGE_CODING_LAYOUTS" permission.
If you are migrating from previous versions of Intella Connect 2.0.1, all users having "HAS_ACCESS_TO_A_CASE" permission will be granted with the "CAN_USE_INSTANT_MESSAGING" permission automatically.
If you are migrating from previous versions of Intella Connect 2.2.1, all users having "CAN_USE_REVIEW_UI" permission will be granted with the "CAN_SEE_ALL_BATCHES" permission automatically.
This automatic conversion affects the "auth.xml" file located in the Intella home directory. A backup file with the name "auth.xml.bak-*" will be created automatically.
|
After this conversion is done switching back to older versions of Intella Connect can result in clearing all roles and permissions previously defined. If this happens user can recover part of the RBAC model structure from the mentioned backup file, however changes made to the model after it has been created will not be preserved. Therefore we strongly advise to back up Intella and Intella Connect home directories before upgrading or downgrading the software. |
The Reviewer role has seven permissions assigned to it by default, which lets users with this role to:
-
access cases in which they are assigned this role
-
download original item
-
create export packages
-
print item reports from inside the previewer
-
can use Dashboard view
-
can use Review view
-
can use Search view
This is demonstrated in the picture below, along with the user interface for RBAC management.
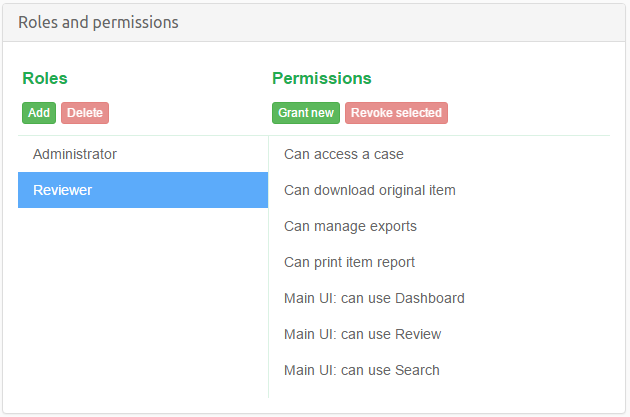
|
In this section we only manage roles and their permissions. The last
step will be to assign some roles to users in a context of given case,
but this task is performed in the |
The Administrator also comes with few default permissions assigned to it. Those allow to manage all cases handled by Connect and also manage users and modify crucial server settings. This role cannot be removed or altered. Moreover, the user "admin" has this role assigned by default and it cannot be revoked from this user. This prevents situations where administrators would accidentally lock themselves out from access to Intella Connect by not leaving a single user with server management permission. The user "admin" is also the first user to create roles for other users with server or case management permissions and assign them.
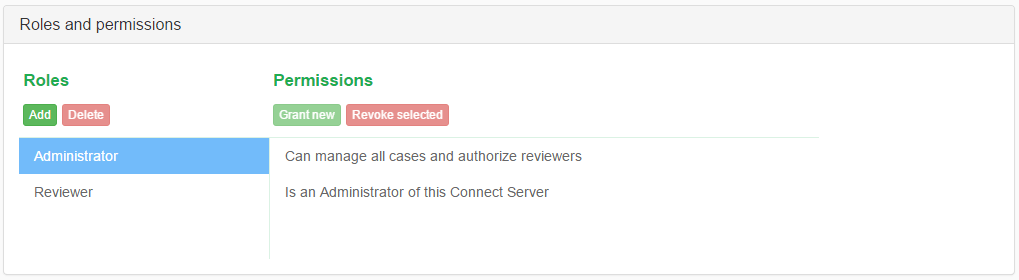
8.4.1. Adding and Deleting roles
Adding new roles is straightforward: click on the Add button located
underneath the Roles label. You will be asked for a name for the new
role. Roles names should be unique. The new role will be immediately
visible in the roles list.
|
After a role has been added, it does not have any permissions assigned to it. It is also not assigned to any user automatically. This means that after a role has been added, it does not affect effective user permissions yet. |
You can also delete roles easily, by selecting them in the roles list
and clicking on the Delete button. You will be asked for confirmation,
after which the role will be removed from the list. Deleting a role does
not mean that this deletes the permissions associated with it, as those
are defined by Intella Connect itself.
|
Deleting a role that was already assigned to some user will have an instant impact on the user’s permissions, they will be recomputed instantly. This will happen even if the case is currently being shared. |
8.4.2. Granting and Revoking permissions
Granting (or adding) and revoking permissions works very similar to roles management. Remember that permissions are always managed in a context of a role, so you have to select a role first in order to see what permissions are assigned to it already and modify this set.
Clicking on Grant new will open up a modal dialog that is used for
selecting a desired permission. Permissions have their own unique
internal IDs which are hidden from the view, so in the first combobox
you can see a more human-readable description that should immediately
let you know what that permission stands for.
Some of the permissions can be added to a role just once (like case access), other can be assigned multiple times (like reducing access to tagged items). In the latter case, the user interface will change a bit and you will be asked to add additional data which is needed by the permission to fulfil its purpose. Again, for the example of limiting access to tagged items, you will be asked to supply the tag name so that Intella Connect knows which tagged items are considered off-limits for users with that role. The user interface should render some hints as you proceed, making the process fairly straightforward.
Granting a new permission for the mentioned example is illustrated below:

Revoking a permission works similar to deleting a role. You will be asked for a confirmation, after which the permission should disappear from the permissions list. This will have an immediate impact on the role that it was assigned to.
8.4.3. Permission types
Below is the list of permissions currently available in Intella Connect. We intend to add more permission types to this list in future releases.
Global permissions:
-
Can manage own cases and authorize reviewers- user with this permission will have access to Intella Connect Dashboard, specifically, sections Cases, Activity stream and About. The cases list will be showing only those cases of which this user is the creator. Additionally, cases which have been shared where user is only a reviewer will also be shown in cases list, however, such user will not be able to manage it. -
Can manage all cases and authorize reviewers- user with this permission will have access to Intella Connect Dashboard, specifically, sections Cases, Activity stream and About. The cases list will be showing all available cases. -
Is an Administrator of this Connect Server- allows users to access Intella Connect Dashboard, specifically, sections User management, System notifications, Settings and About.
General permissions:
-
Can access a case- this permission allows users to access a given case. If a user does not have this permission for a certain case, he will not be able to get past the login prompt. -
Can manage a case- user with this permission will have access to Intella Connect Dashboard, specifically, sections Cases, Activity stream and About. The cases list will be showing only those cases to which user with (role having) this permission is assigned. Additionally, cases which have been shared where user is only a reviewer will also be shown in cases list, however, such user will not be able to manage it. -
Can download original item- allows users to download items in their original format. -
Can manage exports- allows users to create export sets. -
Can print item report- allows users to print a PDF report for an item rendered inside the Previewer. -
Can perform email threading- enables Email Threading action in contextual menu of Details panel of the Search view. Using this feature allows emails to be grouped into Email Threads, as discussed in Email threading.
UI related permissions:
-
Main UI: can use Dashboard- allow users to access Dashboard view. -
Main UI: can use Review- allow users to access Review view. -
Main UI: can use Search- allow users to access Search view. -
Main UI: can use Report- allow users to access Report view. -
Can send and receive Instant Messages- allow users to access built-in Instant Messaging feature. Lack of this permission will cause the Instant Messaging side panel to be inaccessible. -
Can manage and execute case tasks- allow case reviewers to create, edit, delete and execute automated tasks. Lack of this permission will cause the Tasks side panel to be inaccessible.
Review related permissions:
-
Can create new tags- allows users to create new tags. -
Can edit all tags- allows users to edit tags, even if they were created by other user. -
Can delete tags and taggings from other reviewers- users having this permission will be allowed to delete tags and taggings created by other reviewers. In previous versions of Intella TEAM, only Case Manager was allowed to do that. Now this action is available to every user having this permission. -
Can manage coding layouts- allow users to create and edit Coding Layouts. -
Cannot see items tagged with…(this one needs an extra parameter: a tag name) - this permission allows for hiding certain items from certain reviewers, while letting others see the entire data set. Please read more below.
Batch review related permissions:
-
Can archive and delete review batches- allow users to archive and/or delete review batches. -
Can browse others batches- allow users to browse unassigned or others batches. -
Can see all batches (including unassigned)- allow users to see all batches in the list. -
Can skip review of items while coding- allow users to skip review of items when coding. -
Can apply coding decision to all emails in a thread- allow users to use "Apply to all emails in this email’s thread" checkbox when coding. -
Can change any reviewer assigned to a batch or leave it unassigned- allow user to re-assign batches. -
Can create review batches- allow users to create batches. -
Can force recalculation of batch progress- allows users to recalculate the progress of batches. This can be useful if user wanted to skip initial batch progress calculations and later check if the batch is properly coded. -
Can reopen and complete batches which are assigned to him- allows users to reopen batches if their statuses were set to Completed and the batch is assigned to that user. Also allows users to change status to Completed if the batch is assigned to that user. -
Can reopen and complete others batches- allows users to reopen batches if their statuses were set to Completed and the batch is assigned to other than current user. Also allows users to change status to Completed the batch is assigned to other than current user. -
Can complete batches regardless of their previous status- allow users to mark the batch as completed even if they were not coded entirely.This has several use cases, but most importantly it allows to:
-
reopen & close a batch during second pass review
-
forcefully mark batch as completed, due to external factors (for example Quality Assurance)
-
Predictive Coding related permissions:
-
Can create Predictive Coding reviews- allow users to create new Predictive Coding reviews. -
Can delete Predictive Coding reviews- allow users to permanently delete Predictive Coding reviews.
Background Tasks related permissions:
-
Can manage background tasks- allow users to create/delete background Tasks.
8.4.4. Note on "Cannot see items tagged with…" permission
This permission must be used with an extreme caution because in case of any user error it can lead to disclosing of privileged items.
One must observe that always the data is organized in a tree-like hierarchy, where child items are linked to their parents. This tightly relates to the data consistency and opens an interesting question. If only the parent of an item would be hidden, where to Location Facet should place it’s children?
To avoid such purely theoretical debates Intella Connect will hide an item along with all of it’s descendants when using "Cannot see items tagged with…" permission.
Consider this: user A is granted with this permission (for "Privileged" tag) in a data set of 100 items. 10 of those items are tagged with the "Privileged" tag. One of these privileged items has 5 children, e.g. attachments or nested items. This means that user A will be able to see 85 items from this data set (10 + 5 = 15 items are hidden). The privileged 15 items will not show up in the cluster map, search results, facets, etc. If tagged items contain child items, they will be filtered from the results as well. User A will also have no access to the "Privileged" tag in the Tags facet, so he cannot himself modify it to change what he can or cannot see.
Introduction of hierarchical tags in Intella Connect has caused for this mechanism to be extended as well. Since now "Privileged" tag can be anywhere in the tag tree structure, then all tags (and items tagged with them) in a tag subtree starting with this tag will also be considered hidden. Also, tag names are no longer guaranteed to be unique in the entire tag tree. Therefore if there are several tags called "Privileged", all of them will be managed by this set of rules.
|
Disclaimer about limiting access to items Use of this permission should be undertaken with caution in order to prevent leaking of sensitive data. We advise users to test this solution thoroughly before using it in production. It is also important to apply a proper workflow when limiting access to items. For instance, creating an export set first and later applying restrictions to items is a potential leak of information, because the export set could have included privileged items before any restrictions were applied. Also, if a user with access to privileged items adds them to an export package, they become accessible to all other users with access to that case and with the exporting permission. Moreover, using this permission requires much more processing power to be used on filtering intermediate results for various parts of the case database. It can also invalidate some of caches that are put in place to speed up delivering results. Therefore one must be aware that using this permission on larger cases can cause them to behave much different comparing to when this permission is not used. Finally, using permissions to hide privileged items does not mean that those items are removed from the case. They are still present in the case database, but simply excluded from the results and hidden in the user interface for those users not entitled to view them. Therefore a clever attacker could still try to gain access to privileged data by attempting various attacks or malicious usage of communication channels. We advise to conduct a thorough security audit before giving case access to untrusted parties. |
8.4.5. Assigning roles to users
It is important to understand that Roles can be assigned in two ways:
-
Roles are assigned to users per case. This means that a user can have different roles in different cases. In Intella Connect each user can have zero, one or many roles assigned to it in any given Case. To assign roles to users per case, click on
Casesin the top menu in the Intella Connect Dashboard, select a case and then click onAuthorizationsbutton: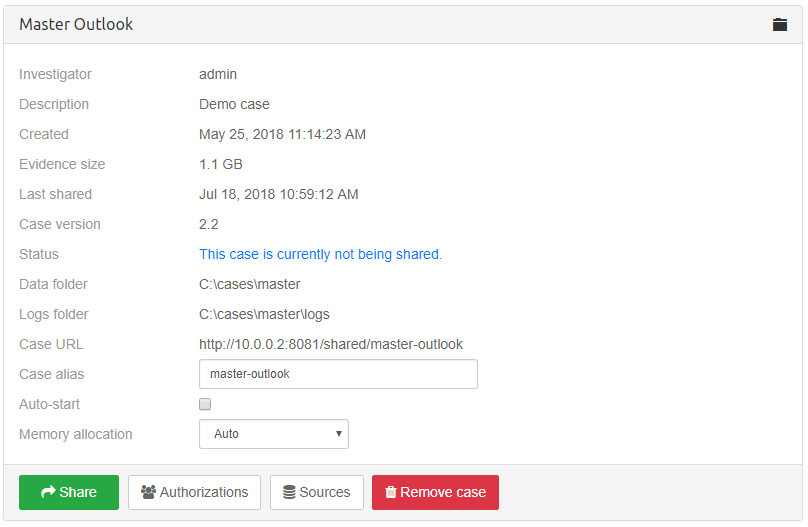
-
Roles are assigned to users globally. Only certain permissions can be assigned to users globally and such permissions are related to server or case management. To assign roles to users globally, click on
Usersin the top menu in the Intella Connect Dashboard,Server and case administrationsection and thenGlobal authorizationsbutton:
9. Sources
Sources are one of the key concepts of Intella Connect. They represent the locations where items such as emails, documents and images can be found. Sources are explicitly defined by the user, providing full control over what information is searched.
9.1. Source types
Intella Connect distinguishes between various types of sources:
-
File or Folder: A single file or folder with source files on a local hard drive or on a shared/network drive. Such source files could be:
-
Regular loose files like MS Word, Excel and PDF files.
-
Email containers such as MS Outlook PST/OST, Outlook for MAC OLM and IBM Notes NSF files.
-
Cellphone XML reports such as made by Cellebrite XRY, MicroSystemation’s XRY and Oxygen Software’s Forensic Suite.
-
Even large containers like EDB files and disk images can be indexed this way, together with many other files in one go. The downside of doing this is that any EDB- or disk image-specific configuration options are not available this way
-
-
Load file: a Concordance, Relativity or CSV load file.
-
Hotmail Search Warrant Result (experimental): a collection of files in HTML and other formats, provided by Microsoft pursuant to a search warrant.
-
Disk image: one or more disk images in E01, Ex01, L01, Lx01, S01, AD1, VHD, VMDK or DD format.
-
MS Exchange EDB Archive: a single MS Exchange EDB file.
-
IMAP account: an email account on an IMAP email server.
-
Dropbox: all files stored in a personal Dropbox or DropBox for Business account.
-
Gmail: a Gmail email account.
-
SharePoint: the complete contents of a SharePoint instance.
-
Office 365: the complete contents of an Office 365 account, incl. the Outlook, OneDrive and SharePoint services of that account.
-
iCloud: The complete contents of an iCloud account, incl. iCloud Drive, Mail, Calendar, Contacts, and other services.
9.1.1. Notes on mail formats
Intella Connect/Node supports PST and OST files created by the following versions of Microsoft Outlook: 97, 98, 2000, 2002, 2003, 2007, 2010, 2013, 2016 and 2019. Make sure that Intella Connect/Node has exclusive access to the PST or OST file; it cannot be open in Outlook or other application at the same time. Intella Connect/Node will try to recover the deleted items from the file. Recovered items will be placed in a special folder named "<RECOVERED>". Furthermore, Intella Connect/Node may encounter items outside the regular root folder. Any such items are placed in a special folder called "<ORPHAN ITEMS>". There is limited ability to recover deleted emails from OST 2013 files, this is being worked on.
To index NSF files, IBM Notes 8.5 or higher needs to be installed. For NSF files made with IBM Notes 9 it is recommended to install IBM Notes 9. Intella Connect/Node supports all NSF files that can be processed by the installed IBM Notes version. Make sure that Intella Connect/Node has exclusive access to the NSF file; it cannot be open in a Notes client or other application at the same time. Only NSF files containing emails are supported by Intella Connect/Node, all other types are not supported. Make sure to use a default Notes installation and user configuration. A "corporate" Notes installation is often problematic for indexing, e.g. because of installed plugins interfering with access to the NSF file, the installation being tied to the corporate identify management system, etc.
|
The IBM Notes tool "nupdall.exe" can be used to convert older NSF files to NSF files that can be processed by IBM Notes 8.5 and higher. |
Intella Connect/Node supports DBX files created by the following versions of Microsoft Outlook Express: 4.0, 5.0, 6.0.
Intella Connect/Node has been tested on Thunderbird Mbox files.
Intella Connect/Node supports MS Exchange EDB files of Exchange versions 2003, 2007, 2010, 2013 and 2016.
9.1.2. Notes on cellphone formats
When indexing Cellebrite, MicroSystemation or Oxygen cellphone reports, each report should be in its own subfolder. Any additional files that were produced together with the XML report, such as audio, video and image files, should have the same relative location to the XML file as the exporting application produced them. These two requirements are crucial for correctly linking the binary files with the XML report. Finally, no other evidence files should be placed in these folders, as they will be ignored.
The folder should reside in the file system, i.e. not in a ZIP file or disk image, as quick random access is needed to be able to process the files linked from this report.
A folder with the XML report and its related files can in principle be indexed straight away. However, most XML reports will often only contain the external numbers related to the calls and messages, i.e. the number of the phone itself is not in the report. This has valid technical reasons (e.g. it cannot be guaranteed that the current SIM card was used for these calls and messages), but it makes analysis of the communication a lot harder. Also, Intella Connect functionalities like message deduplication require this information. When the number is known by the investigator, e.g. obtained from the network provider, it may be specified through a separate text file:
-
Create a text file named after the XML report. For example, if the report is called "report.xml", the text file should be named "report.numbers.txt".
-
Put it in the same folder as the XML report.
-
Store the phone’s own number in this file. When the XML report holds information about multiple phones, enter the number of each phone on a separate line, like this:
number1 number2 <…>
The first line will be used for the first phone found in the report, the second line for the second phone, and so on.
When indexing XRY’s XML reports, we recommend using the Extended XML report introduced in XRY 6.4. This new format solves many issues with the encodings of dates and other fields. Furthermore, the older XML format did not support exporting binary items. To get binary items with the Extended XML report, you need to select the "Export media files and manifest" option.
|
The XML formats used by these cellphone extraction vendors are often evolving over time and are not fully documented. While we strive to extract all information from these reports as completely and correctly as we can, we can only offer this functionality on a best-effort basis. We recommend that you verify any results that you may rely on in your report with the original cellphone extraction software. |
9.1.3. Notes on instant messages
When instant message items (SMS/MMS/iMessage/Skype/Jabber/etc.) have a timestamp and the sender and receiver(s) are all known, Intella will bundle all messages of that group of participants into "conversation items". A conversation item bundles the messages between a group of people on a day-by-day basis. All messages of a single day are now placed below each other in the Previewer’s Contents tab, rather than being presented as one message per item. Hyperlinks are provided to navigate to the previous and next day in the conversation.
Compared to emails, instant message texts are typically very short and do not contain the previous thread. Therefore, bundling messages in this way greatly improves reviewing of instant messages.
Other instant messages, that don’t have enough metadata to be bundled into conversations, will be reported as conversations consisting of a single message.
9.1.4. Notes on IBM Sametime dumps
When indexing an IBM Sametime dump, each dump and its related files should be in its own subfolder. This should be file system folder, i.e. not a ZIP file or disk image, as quick random access is needed to be able to process the files linked from this report.
9.1.5. Notes on disk image formats
|
Intella will NOT recover deleted files and folders from unallocated or slack space. |
|
Intella will only extract deleted file content from NTFS file systems. For all other supported file systems only file and folder metadata will be extracted. |
|
The recovered content may contain data blocks that didn’t belong to the original file. Additional verification may be required. |
If the "Recovery deleted emails, files and Notes deletion stubs" option is turned on then Intella will try to recover deleted files and folders using the information extracted from the Master File Table (MFT). The content of the deleted files will only be extracted from NTFS partitions where it’s possible. For all other supported file systems only the metadata will be extracted.
When indexing a disk image Intella will scan all the MFT entries. Those entries which are marked as unallocated will be reported as deleted items. Additionally, for NTFS file systems, Intella will analyze the allocation status of all the data blocks referred by the MFT entry. The entire content of the deleted file will be extracted if any of the following conditions is true:
-
there is at least one unallocated data block referred by the MFT entry or
-
the MFT entry has only resident data. That means the entire file content is located inside the MFT and therefore can be extracted.
In all other cases only the metadata will be reported.
Any deleted item recovered from a disk image can be one of three types, depending on how many data blocks are available:
-
Recovered entire file content. All the data blocks are unallocated or the file has only resident data. The entire file content has been extracted.
-
Recovered partial file content. Some of the data blocks are allocated to other live files. Please see the "MFT Deleted File - Overwritten Blocks" raw data field for the number of such blocks. The entire file content has been extracted.
-
Recovered file metadata. None of the data clusters are unallocated or recovery is not possible. Only the metadata has been extracted.
You can find those three types in the Feature facet under the Recovered category.
The following raw data fields items are available for recovered items:
-
MFT Allocated. "True" for regular files, "False" for deleted files.
-
MFT Resident. "True" if the file has only resident data, "False" otherwise.
-
MFT Deleted File - Total Blocks. The total number of data blocks.
-
MFT Deleted File - Overwritten Blocks. The number of data blocks which are allocated to other live files. Such data blocks are considered as overwritten.
-
MFT Deleted File - All Blocks Available. "True" if all the data blocks are available (unallocated), "False" otherwise.
9.1.6. Common file locations
MS Outlook PST and OST files are typically located in the following folder:
-
Windows 7, Windows 8/8.1 and Windows 10:
C:\Users\<username>\AppData\Local\Microsoft\Outlook -
Windows 2000 and XP:
C:\Documents and Settings\<username>\Local Settings\Application Data\Microsoft\Outlook
MS Outlook Express DBX files are typically located in the following folder:
-
Windows 2000 and XP:
C:\Documents & Settings\<username>\Local Settings\Application Data\Identities\{<arbitrary string>}Microsoft\Outlook Express
IBM Notes NSF files are typically found in the following folder:
-
Version 7.x:
C:\Program Files\Lotus\Notes\Data -
Version 8.x:
C:\Program Files\IBM\Lotus\Notes\Data -
Version 9.x:
C:\Program Files\IBM\Notes\Data
9.1.7. Notes on cloud sources
Each of the supported cloud services (Dropbox, Gmail, SharePoint and Office 365) provides a so-called REST API for data retrieval. Access to a cloud service via this API often requires an authorization token, rather than or in addition to a username and password. Each cloud service provides a web portal where users can register the client application (in this case: Intella) and obtain the authorization token.
Depending on what the REST API supports, Intella Connect/Node uses read-only data operations wherever possible, as to minimize changes to server-side data. Nevertheless, access may be visible to the cloud service and to the account holder, e.g. due to the presence of an authorization token in the server settings, access logging, altered metadata, etc.
9.1.8. Notes on document length
The indexing of a document text for keyword search can consume a considerable amount of RAM. With multiple documents being processed in parallel, this carries the risk of one of Intella’s processes running out of memory. To combat this, Intella Connect/Node imposes a maximum length to the document text. This way, typically problematic textual files such as large server logs and database dumps in CSV format can be processed without terminating the indexing abruptly.
The maximum length is set to 50M (52,428,800) characters. Any text beyond that point is skipped. Consequently, the document will not be returned when using query terms that only occur after this point. Affected documents can be located using the "Exception Items" category, "Truncated text" branch in the Features facet.
The limit can be adjusted on a case-specific basis via the case.prefs file. For example, alter or add the following line to set the limit to 100M characters: "ItemTextMaxCharCount=100M"
A future Intella Connect/Node version will make this configurable via the user interface. The limit can also be adjusted globally via the IntellaNode.l4j.ini file: "-Dintella.itemTextMaxCharCount=100M"
9.2. Adding sources
Adding sources is done with the Add New Source wizard. It can be opened by pressing (+) icon on the empty source slot on the Sources page. The first page of the wizard allows to select the type of the new source, which is illustrated below:
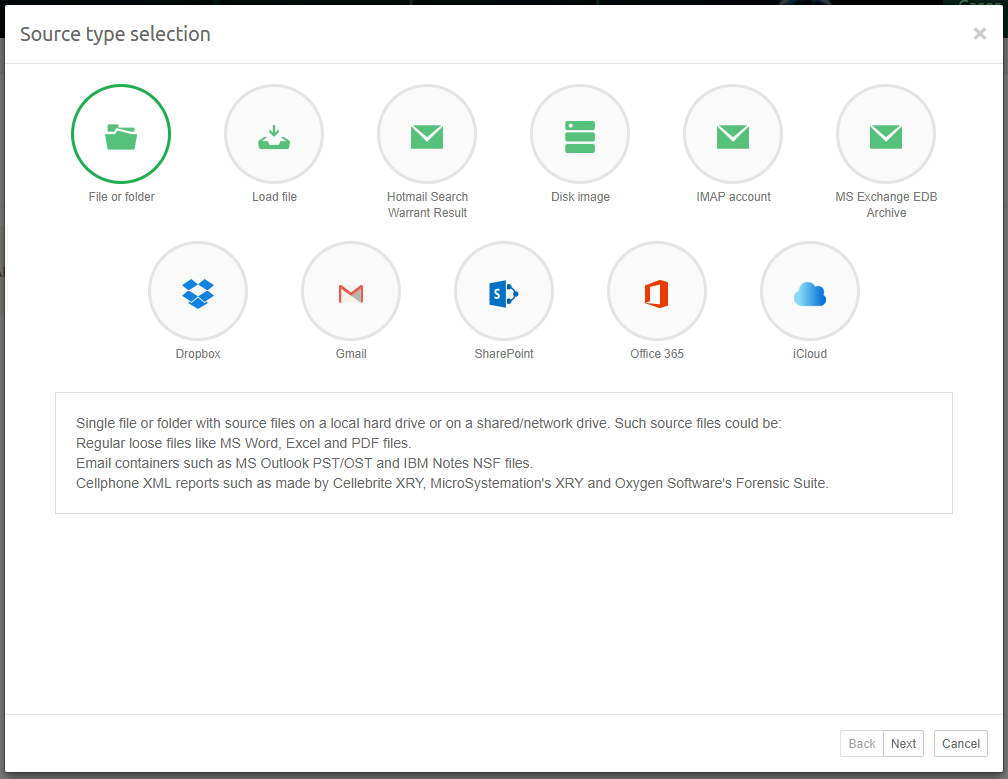
9.2.1. Note on source locations
|
When providing paths to evidence make sure to use locations which are accessible for both Intella Connect as well as selected Intella Node on which indexing operation will be performed. |
9.2.2. Files and Folders
Follow these steps to add a File or Folder source to Intella:
-
Source type
Select "File or Folder" source type and click "Next". A folder tree will be displayed next.
-
Specify file or folder
Select the folder or file from the tree that you want to index, or enter the folder or file name in the text field above the tree. When selecting a folder, all files in the selected folder will be indexed. When the "Include subfolders" checkbox is selected, files in all subfolders (and sub-subfolders, etc.) will also be indexed. When the "Include hidden folders and files" checkbox is selected, hidden files and folders will be indexed as well.
|
Folder trees containing many items may take some time to be displayed. Please be patient. |
Click "Next" to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
9.2.3. Load files
|
The built-in export and import templates "Intella Standard Relativity Export (All Columns)" and "Intella Standard Relativity Import" can be used to export items and re-import them in another case, effectively creating a subset of the original case. Please note that not all metadata fields are supported. |
Follow these steps to add a load file to an Intella case:
-
Source type
Select "Load file" source type and click "Next".
-
Import load file
-
Select the import operation: New Data or Overlay. When New Data is selected, Intella Connect will import new items to the case. An Overlay operation is used to import tags, comments and tag columns into existing items.
-
Add the file name and location of the load file that you wish to investigate; use the tree component to browse for the file. If the load file comes with an Opticon image file, then you should specify it in the "Opticon image file" field.
-
Specify the source name.
-
Specify the custodian. If the custodian information is stored in one of the columns, then leave the text field empty and use the column chooser on the "Map fields" page instead.
-
Specify the time zone. By entering the time zone, all dates associated with items from this load file will be displayed in that time zone, rather than the time zone of the investigator’s system.
-
You can use a previously saved import template.
-
Click "Next" to continue.
-
-
Configure delimiters
On the "Configure delimiters" page you can set the file encoding and delimiter settings for:
-
Column delimiter – the character that separates the columns in the load file.
-
Text qualifier – the character that marks the beginning and end of each field.
-
New line – the character that marks the end of a line inside a text field.
-
Multi-value delimiter – the character that separates distinct values in a column.
-
Escape character – the character that is used for escaping a separator or quote.
-
Strict quotes – sets if characters outside the quotes are ignored.
-
Use absolute path – select this option when the load file uses absolute paths rather than relative paths.
You can click the Detect button when you are not sure about the encoding used in the load file.
You can specify date, time and number formats in the right part of the screen. The Size unit option allows to change the way how the Size field is imported.
Intella Connect will validate the load file using these settings and display the validation result in the status line. When the file can be validated successfully, the number of columns found in the load file will be displayed. When validation fails, a reason will be given in this line.
The "Load file preview" table can be used to make sure that you have specified the correct parameters for the load file. Additionally, the "Image preview" panel will show the first image associated with the selected table record. It can be used to ensure that the Opticon file is correctly loaded. The "Text preview" shows the raw text of the load file and can be used to check the delimiters.
Click "Next".
-
-
Map fields
-
Overlay options: this is only used when Import operation is set to Overlay. See the "Importing an overlay file" section for details
-
External files:
-
Select the "Load native files" checkbox if you want to import original format files associated with the load file into the case. Specify the column containing the paths to the native files. When the native files are imported, you will be able to use functions such as Preview tab and Open in External Application.
-
If you select the "Extract type information from native files" check box, then Intella Connect will analyze the native files and import the type information into the Mime Type and Type columns. This option may be useful in case the load file does not have any type information such as File Extension.
-
Select "Load extracted text" when you want to import the extracted or OCRed text of the document. Select the "Extracted text column is a link to an external file" checkbox when the column contains a link to the text file rather than the text itself. Select "Analyze paragraphs" to let Intella Connect determine the paragraph boundaries and to let it build a database registering which paragraph occurs in which item and where (see section Last steps in a source definition for more details). When the extracted text is imported, it will be shown in the Contents tab of the Previewer.
-
-
Field mapping – You can see the Field chooser in the bottom part of the panel. The table on the left shows all fields in the load file ("Load file field") and the Intella columns they are mapped to. In the table on the right you can see the list of all Intella columns available for mapping. To map a column:
-
Select one of the load file fields on the left.
-
Select one of the columns on the right.
-
Click the left arrow button. That will move the selected column from the right to the left table.
Click the right arrow button to remove the selected mapping.
When the load file contains a field that cannot be mapped to any existing columns, then you can create a tag or custom column and map the field to it. Click the "Add" button to add a new column to the right table. Click the "Remove" button to remove the selected column. Note that a tag or custom column can only be removed if there is no data in the case associated with it. Tag columns should only be used for importing tag-like data where the number of unique values is not high. In all other cases custom columns should be used instead.
Click the "Clear all" button to remove all the selected columns from the right table. Click the "Save template" button to save the current settings as an import template which can be reused later. Select the "Extract text and metadata from native files" checkbox when you want to extract the text and metadata from the native file. The button with a gears icon can be used to adjust the processing options. See Last steps in a source definition section for more details about the processing options. Note that Intella Connect will replace any original metadata from the load file with the new metadata extracted from the native file. The option is turned off by default.
It is highly recommended to resolve all errors by clicking the "Check for errors" button before importing the load file. That will let Intella Connect validate the load file using the entered settings. Among other things, it will check each row and ensure that:
-
-
The Document ID is unique and not empty.
-
The Parent ID refers to an existing record.
-
Native and extracted text paths are correct.
-
Date and time fields can be parsed using the selected date and time formats.
-
The MD5 field contains a valid MD5 hash.
-
Number fields such as File Size and Page Count contain a valid number.
-
Boolean fields such as Encrypted and Decrypted contain either "true" or "false".
-
The Source IP field contains a valid IP address.
Select the "Skip error records" checkbox to instruct Intella Connect to skip items with errors during import.
-
|
Date and time values (separate columns) will be merged into one column. |
Important notes on load file importing
There are several aspects to be aware of when importing a load file into an Intella case:
-
All paths in the load file to external resources should be relative to the load file, unless the "Use absolute paths" checkbox is selected.
-
The original load file record identifiers will be imported into the "Document ID" and "Parent Document ID" columns and can be used in a subsequent load file export.
-
Imported images can be viewed in the "Image" tab in the Previewer.
You can save the specified load file import options as a template for later usage on the last page using the button Save Template. All import templates are stored as XML files in the "<Intella Home Folder>import-templates" folder.
9.2.4. Hotmail Search Warrant Results
|
This source type is still in an experimental stage. We welcome any feedback; please visit our support portal at http://support.vound-software.com/. |
Follow these steps to add a Hotmail Search Warrant Result to Intella:
-
Prepare evidence files
The evidence files you have received may consist of a folder containing a "Click Here.html" file and some legal files related to the search warrant, with a subfolder for each account involved. It may also be that you have only one of those account subfolders, recognizable by a "Folders.html" and "Messages" file in this folder. In case you have received a ZIP file or some other type of archive file, please unpack this archive file first.
-
Source type
Select "Hotmail Search Warrant Result" source type and click "Next".
-
Specify file
Select the folder holding the Hotmail Search Warrant Result files that you wish to investigate in the folder tree. Make sure to select the top-level folder of the provided file collection. Click "Next" to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
9.2.5. Disk Images
Follow these steps to add a Disk Image source to Intella:
-
Source type
Select "Disk image" source type and click "Next".
-
Select disk image file
Select disk image file in the folder tree. List of supported image types is displayed underneath the tree. You can add more parts in the next step. Press "Next".
|
If the disk image contains encrypted volumes, such as BitLocker or APFS, a notification will be shown instructing to update Keystore of this case with matching passwords or recovery keys to access the image. |
-
Specify disk image files
You can specify here additional parts of your disk image: click "Add…" to go back to "Select disk image file" page to do so. Select another file and click "Next". All selected files will be listed in the disk image list. Alternatively, one can select a single image part and then click Find Parts. Intella will then try to find the related image parts that belong to that same multi-volume image (see below) and add them to the list. Files of a multi-volume image should be listed in the correct order. Select rows and use the Move Up and Move Down buttons to put files in the correct order.
-
Select files and folders to process
Indicate which files and folders should be processed by selecting a pre-defined profile or creating a custom one. See below for detailed instructions.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
|
A single disk image source should only contain the files relating to a single conceptual image. Files relating to a different image should be entered as a separate source. |
Filtering disk image content
A disk image often contains a lot irrelevant files, such as executables, DLLs. These files add to the processing time and disk space that the case will consume. It is possible to define a set of rules to filter out unnecessary files and folders, to save processing time and disk space.
|
Filtering disk image content is not possible for DMG images. |
On the "File types and locations page" you can choose either to index all the data by selecting "Index all files and folders" check box, or use a specific disk image indexing profile. There are several built-in profiles:
-
All supported files. Index all file types supported by Intella Connect. "Supported" means that Intella can do something meaningful with it besides detecting the file type, i.e. it can extract text, metadata and/or embedded items from the file, or display it as an image. All executables for example are not hashed and cached with this profile.
-
All supported files, exclude system files. Index all file types supported by Intella Connect and exclude three system folders: "Windows", "Program Files" and "Program Files (x86)".
-
Mail stores. Index only mail store files: PST, OST, NSF, Mbox, etc.
-
Mail stores, exclude system files. Index only mail store files. Also, exclude the three system folders listed above.
You can also adjust any index profile to your needs. To create a new profile, type a new name in the "Use index profile" box and click the Save button. You can delete any profile by selecting it first and clicking the Remove button.
The first section on this page defines the rules on which files should be included or excluded. You can filter files by type and by file name. If you select "Include selected entries", then only the listed files and file types will be indexed. Otherwise, the listed entries will be excluded. Note that you use wildcard names such as "*.txt" to filter all files that end with ".txt".
A single "File name" entry can contain only a single file name definition; you cannot enter several file names in a row such as "*.txt, *.exe". You should add two separate entries to the list in this case.
The second section on this page defines a list of locations that should be included or excluded. If you select "Include selected entries" then only the listed locations will be indexed. Otherwise, the listed locations will be excluded from indexing. You can adjust the folder selection on the next screen called "Select Folders".
All index profiles are stored in XML format in the "<Intella Home Folder>index-profiles" folder and can be used in all local cases.
Note that search results can also be filtered after indexing, using the Hide Irrelevant filter option in the Details tab.
Supported disk image formats
The Disk image source type supports EnCase E01, Ex01, L01, Lx01 and S01 files. Password-protected files are supported and indexed without manual interaction, except for FTK-encrypted files.
DD images are supported, but when a Folder source is used, they need to use the .dd file extension to be detected and processed as DD images. Because of potential issues with DD image detection, we recommend using the Disk Image source directly. This is also required when you want to index a multi-volume DD image
Supported file systems and partition types
The following file systems have been tested: FAT16, FAT32, ExFAT, NTFS, Ext2, Ext3, Ext4, HFS, HFS+, APFS and ISO 9660.
MBR and GUID partition tables (GPT) partitions are supported. Apple Partition Maps (APM) have been tested but results were mixed. When Intella fails to index such an image, we recommend mounting it manually and indexing the mounted drive using a "File or Folder" source.
Multi-volume files
When using a Folder source to index multiple image files, Intella Connect will rely on the following file name convention to determine which files together make up a single image:
image1.e01 (first volume of image 1) image1.e02 (second volume of image 1) image1.e03 (third volume of image 1) … image2.e01 (first volume of image 2) image2.e02 (second volume of image 2) image2.e03 (third volume of image 2) … image2.e99 (99th volume of image 2) image2.eaa (100th volume of image 2) image2.eab (101st volume of image 2) …
9.2.6. MS Exchange EDB Archives
|
Processing an EDB archive may require to adjust memory settings. Please see the "Memory settings" section for detailed instructions. |
The currently supported MS Exchange versions are 2003, 2007, 2010, 2013 and 2016.
Follow these steps to add a MS Exchange EDB Archive source to Intella:
-
Source type
Select "MS Exchange EDB Archive" source type and click "Next".
-
Specify EDB file
Specify the location of the EDB file you wish to investigate either by typing it’s location or by selecting it in the folder tree. Click "Next" to continue.
-
Select mailboxes
Check all mailboxes that you wish to process. Click "Next" to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
When an EDB source has been added and not all mailboxes were selected, it is still possible to index additional mailboxes in that EDB file at a later stage. To do that, the following steps should be performed: 1. Click on the "Edit" button for the respective source on Sources page. 2. Indicate which mailboxes should be processed. Note that you cannot unselect or remove already processed mailboxes. Click OK. 4. Use the "Index new data" button option to index the new mailboxes.
9.2.7. IMAP accounts
|
The IMAP standard is implemented in many ways. Furthermore, some mail servers may throttle the network connection during mass downloads. We tested Intella Connect on several IMAP servers with good response. However, we cannot guarantee that Intella Connect can create IMAP account sources for every IMAP server. |
|
We recommend using a mail client to download the entire mailbox and indexing the resulting PST or Mbox file instead, rather than using Intella Connect to download the mailbox. This way a copy of the mailbox is created outside of the Intella case. This results in a cleaner and better auditable workflow, allowing e.g. cross-validation of the investigation results with other forensic tools or indexing with future Intella Connect versions. |
Follow these steps to add an IMAP Account source to Intella:
-
Source type
Select "IMAP account" source type and click "Next".
-
Specify account
Enter the settings for the target email account, e.g., "mail.my-isp.com" with the username and password. Select the "use secure connection (SSL)" checkbox if you want or need a secure connection to the mail server. This is recommended, because without a secure connection your password will be sent as plain text. Click "Next" to continue.
-
Select folders
In the next step, Intella Connect will contact the specified email server to retrieve the folder tree of the target mail account. You can then select the folders that you want to make searchable by placing a check in the box next to the desired folders. When you want to index subfolders, you will need to select them; otherwise they will be ignored. The wizard has two convenient buttons for selecting and deselecting all folders. Click Next to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
9.2.8. Dropbox accounts
A Dropbox source reconstructs the entire folder tree in a Dropbox account and downloads current and past revisions of the files in the account.
The official Dropbox REST API used by Intella Connect limits this to a maximum of 10 revisions per file. All revisions except for the last one have their file names decorated with the revision identifier. Furthermore, additional Dropbox-specific metadata is retrieved for both files and folders. These are displayed in the Previewer’s Raw Data tab and are subject to full-text indexing.
Intella Connect uses the OAuth2 (Open Authorization) protocol to access the account. Prior to defining the source, the investigator needs to obtain an OAuth2 token for the account.
This process is described in detail in the following Knowledge Base Article: Collecting data from a DropBox source.
Next, follow these steps to add a Dropbox source to Intella Connect:
-
Source type
Select "Dropbox" source type and click "Next".
-
Connect to Dropbox
Open the OAuth2 token in a text editor. Copy the file’s textual content into the Oath2 Token field in the wizard. Click Connect to Dropbox.
A connection will be established and the token will be validated. If the token validation is successful, basic information about the account such as the account owner’s name and email address will be shown beneath the token field.
Note the Help button above the token field. Clicking it will display the steps required to create the OAuth2 token.
Click Next to continue.
-
Select files or folders
Besides indexing of the entire account, it is also possible to index specific files or folders only. The next wizard sheet shows the folder tree of the account. Nested folders are loaded on demand when the parent folder is expanded. Click the checkboxes of the desired files or folders. Selecting a folder automatically marks all nested elements as selected.
Click Next to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
9.2.9. Gmail accounts
A Gmail source reconstructs the mail collection in a Gmail account. Optionally, the set of retrieved emails can be restricted to a certain date range.
Benefits of using the Gmail source over the generic IMAP source are: faster performance, more accurate data representation (e.g. folders vs. Gmail’s Labels, threads), and a read-only data connection ensuring that no data is altered on the server.
Intella Connect uses the OAuth2 (Open Authorization) protocol to access the account. Prior to defining the source, the investigator needs to obtain an OAuth2 token for the account. The token will be downloaded as a JSON file, which Intella can use to access the account. This process is described in detail in the following Knowledge Base Article: Collecting data from a GMail source.
Next, follow these steps to add a Gmail source to Intella Connect:
-
Source type
Select "Gmail" source type and click "Next".
-
Connect to Gmail
Click the Select button and select the JSON file saved above in the file chooser that opens. Alternatively you can also drag and drop this file directly to the file upload box. Click Connect to Gmail.
A connection will be established and the token will be validated. A browser window will automatically open, through which Gmail will request permission to continue. If the token validation is successful, basic information about the account such as the account owner’s email address and the total number of emails will be shown beneath the OAuth2 File field.
Note the Help button above the upload box. Clicking it will display the steps required to create the OAuth2 file.
Click Next to continue.
-
Configure download
Select whether all email messages are to be downloaded or whether a date filter is to be applied. If so, enter the desired date range.
The end date is included, so that emails on that day are also retrieved. Both the start and end dates are optional, making it possible to enter a half-open date range, e.g. "all emails since May 1st, 2015".
Click Next to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition.
9.2.10. SharePoint
SharePoint is organized as a recursive hierarchical tree of sites. A SharePoint source will reflect all subsites, document libraries, discussion boards containing posts and Microfeed posts. Furthermore, a SharePoint source extract all user accounts, including both system accounts and regular user accounts. What information is required to retrieve information from a SharePoint instance depends on whether it is an on-premise instance or an instance hosted in the Azure Cloud (as a separate Office 365 service). For both types, a server URL, username and password are required. For SharePoint instances in the Azure Cloud, a client ID token is additionally required.
This process is described in detail in the following Knowledge Base Article: Collecting data from an Office 365 or a SharePoint Source.
Next, follow these steps to add a SharePoint source to Intella Connect:
-
Source type
Select "SharePoint" source type and click "Next".
-
Connect to SharePoint
Enter the server URL, username and password of the SharePoint account. For Azure Cloud-hosted SharePoint instances, click the Hosted in Azure Cloud checkbox and enter the Client ID in the field that appears. Click Connect to SharePoint.
A connection will be established and the token will be validated. If the token validation is successful, basic information about the account will be shown in the wizard.
The following authentication methods are supported: OAuth2 (for cloud instances), Kerberos, NTLM and basic authentication.
Click Next to continue.
-
Select files or folders
The next wizard sheet shows the site and folder tree of the account. Nested folders are loaded on demand when the parent folder is expanded. Click the checkboxes of the desired sites.
In this version, only entire sites can be retrieved. A future version may add retrieval of parts of a site.
Click Next to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition .
9.2.11. Office 365
The Office 365 source types allows for retrieving both user account and user groups. For each user account, used to access Office 365, the source can retrieve data from Outlook, OneDrive and SharePoint. For each user group, the source retrieves titled conversations containing emails.
Before a source can be added, the Office 365 account must be properly configured. This process is described in detail in the following Knowledge Base Article: Collecting data from an Office 365 or a SharePoint Source.
Once the credentials are established, follow these steps to add an Office 365 source to Intella Connect:
-
Source type
Select "Office 365" source type and click "Next".
-
Connect to Office 365
Enter the username, password and client ID obtained above. Click Connect to Office 365.
A connection will be established and the credentials will be validated. If credentials validation is successful, basic information about the account such as the tenant name and location will be shown beneath the configuration fields.
Note the Help button at the top of the screen. Clicking it will display the steps required to create the client ID.
Click Next to continue.
-
Select items
The next screen shows the available accounts. Select the accounts that you wish to retrieve.
Selective indexing of part of the account data is not possible at this moment.
Click Next to continue.
The last steps in the definition of a source type are almost the same for all types. They are described in the section Last steps in a source definition .
9.2.12. iCloud
The iCloud source type is used for indexing the contents of an iCloud account, such as emails, photos and notes.
Prior to defining an iCloud source, the investigator must obtain the Apple ID and password used by the account owner. When the account has been configured to use two-factor authentication (2FA), iCloud additionally sends a verification token. The verification token is sent only if a valid phone number is set for the Apple ID. Hence, the investigator needs to have access to one of the physical device (an iPhone or an iPad) associated with the account, including the passcode to unlock the device.
Intella supports the retrieval of the following data from an iCloud account:
-
Contacts
-
Emails
-
iCloud Drive
-
Reminders
-
Calendar
-
Event notifications
-
Photos
-
Account settings
-
“Find my phone” data
-
Notes
Follow these steps to add an iCloud source to Intella:
-
Source Type
Select "iCloud" source type and click "Next".
-
Connect to iCloud
Enter the Apple ID and password of the account. Click Connect to iCloud.
When this account requires two-factor authentication, Intella will extend the form with an option to choose the verification delivery method: SMS or Idmsa.
Both methods are equally capable of providing access to the account’s data. When the account is linked to an iPhone and/or iPad, the Idmsa method is recommended. When the account is linked to a non-Apple device (e.g. a cellphone or tablet from a different vendor), SMS is the only way to obtain the verification code. Even when using an Apple device, SMS can be selected as the preferred method for delivering the verification code. In that case, the registered device may receive multiple notifications from Apple’s identify management service (IDMSA). Such notifications should then be ignored and the code from the SMS message should be used.
Choose the desired delivery method and click Get Verification Code. A six-digit verification code will be either sent as an SMS or show up as a native iOS notification on the Apple device. The controls for choosing the delivery method will be replaced by a Verification Code field. Enter the received verification code in this field. Click Connect to iCloud.
When the credentials and the verification code are all valid, Intella will list some account info such as the Full Name of the account owner. Click Next to continue.
-
Select items
In the next step, the available iCloud services for this account are listed. The user can choose whether to retrieve one or more specific services, or whether to retrieve all account data.
The last steps in the definition of a source are almost the same for all types. They are described in the section Last steps in a source definition .
When Intella establishes a connection to iCloud using the account credentials, it will obtain a trust token. This token allows Intella to connect to iCloud at a later point in time without requiring the user to re-enter the credentials and perform any two-factor authentication steps. The trust token has a limited validity period. iCloud sources can be indexed and re-indexed during the validity period of the token. Once the token has expired, the source must be re-created; there is no way to refresh the token of an existing source.
|
Documents in Keynote, Pages and Numbers format are converted by the iCloud web service to MS Word, MS PowerPoint, and MS Excel format respectively when they are retrieved by Intella. Processing of the documents in their native format may be added in a future release. |
|
The Notes branch currently lists Note items in a flat list; folders are not reported. This may be addressed in a future release. |
9.2.13. Last steps in a source definition
The following final steps are the same for all source types.
Source name and time zone
In the Source Name and Time Zone sheet you are asked to enter a name for the source. The name will be shown in the list of sources in the Sources panel and functions purely as a label for your reference.
Furthermore a suspected system base time zone can be entered. This setting indicates the time zone of the system from which the evidence file(s) were obtained. By entering this time zone, all dates associated with items from this source will be displayed in that time zone, rather than the time zone of the investigator’s system. This often makes it easier to correctly interpret those dates, e.g. determine whether a given timestamp falls inside regular business hours. By default, the local time zone is used for new sources. Time zones supporting Daylight Savings Time (DST) are marked with an asterisk (*).
Click Next to continue.
MD5 Hash Filters
MD5 hash filters can be used to exclude items that have a specific known MD5 hash from a case. The so-called "De-NISTing" of evidence data is the most well known application of such hash lists: it excludes many files that belong to the operating system or common software applications from your case. But you can also add other types of MD5 hash lists, or create your own.
When selecting one or more of the hash filters for the source, Intella Node will ignore any items that have an MD5 hash that is in at least one of the filters. After the source has been indexed, such items will not be visible in your case. A future Intella Node release will add the ability to add "stubs" for such items.
The list of MD5 hash filters shown in add new source wizard is shown as detected by Intella Connect. This allows adding a source without indexing it right away. That means, however, that in order to index such source, Intella Node will need access to MD5 hash filters that were selected when adding that source. It is therefore recommended that the path in which Intella Connect and Intella Node look for MD5 hash filters is via a shared folder. The shared folder type required when setting path to MD5 hash filters is Configuration type. See section Intella Connect Dashboard > Shared folders for more information.
Intella Connect can only view list of MD5 hash filters. The list that Intella Connect detected can be seen in menu → Settings → MD5 Hash Filters view. The path in which Intella Connect looks for MD5 hash filters can be seen in Hash filters folder, which is by default a local disk path. This can be changed to a shared filter as mentioned above.

Likewise, the list of MD5 hash filters that Intella Node detects can be seen in menu → Servers → Nodes → click Configure button on a node panel → MD5 Hash Filters view. The same applies to Hash filters folder of Intella Node as mentioned above.
After configuring both Intella Connect and Intella Node to use shared folder, which points to MD5 hash filters location, the list of MD5 hash filters will be the same. Alternatively, if shared folder will not be used, then the hash filters will need to be copied manually between Intella Connect and Intella Node in order to be able to use MD5 hash filters during adding or re/indexing source.
Intella Node can create an MD5 hash filter from a CSV file, where the MD5 hash is encoded as a hexadecimal value. To do so, navigate to menu → Servers → Nodes → click Configure button on a node panel → MD5 Hash Filters view. Click "Create" button to open the "Create MD5 hash filter" dialog. After specifying the path to the CSV file, Intella Node will analyze the CSV file and show you the values for the first few lines. If there’s a single column that contains MD5 hash values then that column will be automatically selected. After specifying an appropriate name for the hash filter you can start the filter creation by clicking "Create hash filter".
Intella Node can process plain CSV files, but also CSV files that are compressed using ZIP or GZIP. Processing the files in compressed form is often preferable as the uncompressed files can be very large (multiple gigabytes).
The Reference Data Set (RDS) that is made available by the National Institute of Standards and Technology (NIST) comes in the form of an ISO file. You will need to extract the NSRLFile.txt.zip file that is stored in this ISO.
This NSRLFile.txt.zip file is a ZIP-compressed CSV file that can be processed by Intella Node.
You can find the most recent versions of the RDS at https://www.nist.gov/itl/ssd/software-quality-group/national-software-reference-library-nsrl/nsrl-download/current-rds.
For the "Modern RDS" set the "minimal" version is the smallest download that still contains the complete set of hashes.
Any MD5 hash filters that you create will also be available for use in other Intella cases.
They are stored in the folder C:\Users\<USERNAME>\AppData\Roaming\Vound\Intella\hash-filters (click Open folder to open this folder in Windows Explorer).
The files in this folder can be copied to/from other computers to make them available there as well. Clicking Rescan folder will update the list of available filters.
|
| Deleting MD5 hash filter files will affect the ability to re-index other cases that use the same hash filter. |
Items
Intella Connect makes the indexing of certain complex file types optional. You can disable this to improve indexing performance at the cost of fewer results.
-
Select Index mail archives if you want to extract all emails and attachments from mail archives like PST and NSF files. Subsequent processing of documents, archives and other items found in the attachments are still subject to the other options.
-
Select Index chat message if you want to index chat messages inside Skype SQLite databases, Pidgin accounts and Bloomberg XML dumps. This also controls what happens with Skype, WhatsApp messages etc. in cellphone reports.
-
Select Index archives if you want Intella Connect to index files inside archives such as ZIP and RAR files.
-
Select Index content embedded in documents if you want to extract images embedded in emails, MS Office, OpenOffice, XPS and PDF documents. This will make these images separately searchable and viewable.
-
Select Index databases to enable the indexing of all tables in SQLite databases.
-
Select Index Windows registry to make all keys and values in a Windows registry file searchable by full-text keyword search. When turned off, a limited amount of registry indexing necessary for populating the Insight tab will still take place. The overhead for this is negligible.
-
Select Index Windows event log to let Intella process the contents of Windows event log files (evtx).
-
Select Index browser history to let Intella Connect process the contents of web browser histories.
-
Select Recover deleted emails, files and Notes deletion stubs to enable the processing of deleted emails from MS Outlook (PST, OST) and MS Exchange (EDB) files, deleted files and folders from disk images and deletion stubs in IBM Notes files (NSF).
-
Select Extract text fragments from unsupported and unrecognized file types to enable heuristic string processing on all items whose type is not recognized by Intella Connect (they are binary blobs) or whose type is not supported apart from type detection (e.g., executable files).
Options
This sheet provides additional options affecting the time needed for indexing.
-
Select Cache original evidence files to copy all evidence files into the case folder. Use this option if you want to create a self-contained case where the evidence files can be opened or exported even when they are not found in their original locations, for instance when the case is moved to another system).
When this option is turned on, additional processing time (especially for compression) and disk space is needed.
This setting has no effect on storing of the items extracted from these evidence files (e.g. the mails, attachments and other embedded items extracted from a PST file), as these are always stored in the case folder after extraction.
-
Select Analyze paragraphs to let Intella Connect determine the paragraph boundaries and to let it build a database registering which paragraph occurs in which item and where. This enables various search and review options at the expense of additional processing time. The required storage space is negligible. For subsequent sources this setting is forced to be same as what has been used for the first source.
Tasks
This sheet lets the user define post-processing steps that need to take place once all evidence files have been crawled and all indices have been build. See the Tasks section for more details.
Completed source definition
Finally you will be presented with a dialog to inform you that you have successfully defined a new source. You may optionally start indexing the source. Indexing is required to be able to search and explore the items in this source, but can be only performed on Intella Node. Once you click the Finish button, the indexing process will proceed according to the options you have selected.
|
Because the active indexing process prevents you from defining more new sources, you may wish to skip this part now (e.g., to define more new sources) and index the sources later by clicking the Re-index menu item in the Sources page. |
|
At any time except before the step "Completed Source Definition," you can click the Cancel button to return to the Intella Connect interface without having added a new source to the case. |
|
Error message "Server response timed out" after adding source to be
indexed could be related to the network issues as Connect tries to add
the source to the case, but does not complete this operation within a
time frame. This time limit can be adjusted via the |
9.3. Indexing
After defining a source Intella Node can index it. During indexing it will inspect all items (emails, files etc.) that it can find in the source file(s), enabling Intella Connect to return instantaneous results during your investigation for relevant evidence.
|
Having anti-virus software active during indexing can lead to certain items not being indexed. This will usually be restricted to the files that are blocked by the anti-virus software, but this cannot be guaranteed. Running anti-virus software may also affect indexing performance. |
During indexing, Sources page will show you a panel displaying various types of information:
-
Statistics on indexing speed.
-
Statistics on encountered file types.
-
The amount of data that is being indexed and how much has been indexed already.
-
The number of indexing steps to perform, which current step is being performed and (for some steps) a progress percentage.
You can stop the index process at any time by clicking the Stop button. Intella Connect/Node will finish processing the current item and then complete its case databases with the information that has been extracted thus far.
|
For remote indexing example please take a look at the Using Node section. |
9.3.1. Note on finishing indexing operations
After certain operations related to indexing (ex. indexing of new source or reindexing the entire case) the case will remain open on an instance of Intella Node. To release it, one has to navigate to Sources page and click on Finish source management button.
9.3.2. Re-indexing a case
There may be circumstances when you want to re-index the entire case, e.g. to use extraction features offered by a newer Intella Connect/Node version or fix a broken index. To rebuild the case index from scratch, use the Re-index option on the Sources page. Intella Connect/Node will remove all indices it has previously created and create new ones. In order for this to work, all evidence files have to be present at the location they had during the initial indexing.
|
Re-indexing a case will cause Content Analysis and Email Threading results to be removed. These operations need to be re-run after re-indexing finished in order to make use of them. |
9.3.3. Updating a case
Alternatively, there may be times when you want to update an index, e.g. in the following scenarios:
-
Files and/or folders have been added to folders that have already been indexed.
-
New sources have been defined but were not indexed immediately.
-
The set of mailboxes to index in an EDB source has been extended.
-
You interrupted indexing using the Stop button.
In these cases the "Index new data" option in the Sources view will scan all sources for new evidence items. Items that have already been indexed are not changed, also when their original evidence items are no longer available.
9.4. Automatic item decryption
Intella Node can automatically decrypt several file formats, if the required credentials are supplied before indexing starts. Therefore, you may want to uncheck the checkbox in the Add Source wizard that starts indexing and use the Re-index option (see above) after these credentials have been entered.
Intella Node will store decrypted versions of emails and documents in the case. For more details about exporting decrypted data see subsection "Preferred content type options" of section Exporting in the Reviewer’s manual.
9.4.1. Supported formats
The following file formats can be decrypted by Intella Node when the credentials are specified before indexing:
-
IBM Notes NSF files.
-
S/MIME- and PGP-encrypted emails, regardless of the container type they reside in (e.g. EML, MSG, PST, OST, NSF, Mbox, DBX).
-
PDF documents.
-
Old format MS Word documents (.doc), MS Excel spreadsheets (.xls) and MS PowerPoint presentations (.ppt).
-
MS Office 2007 formats (OpenXML): .docx, .xlsx, .pptx, …
-
ZIP, RAR and 7-Zip archives.
-
Partial support for ZipX.
-
BitLocker volumes.
-
APFS file systems.
Furthermore, password-protected PST files can be automatically decrypted without specifying any passwords.
9.4.2. Supplying access credentials
To let Intella Node automatically decrypt the encrypted items that it encounters, their keys (passwords, certificates, etc.) need to be added to the Key Store first.
Navigate to Sources page and click on Key Store button and follow the instructions below. Afterwards you can (re)index your data and let the items be decrypted automatically.
All credentials that you enter will be tried on all encrypted files to which they can apply. It is therefore not necessary to specify e.g. which password applies to which file or file type.
After indexing you can see which items were successfully decrypted by using the "Decrypted" category in the Features facet or by using the "Decrypted" column in the Details table. Note: due to technical reasons, decrypted NSF files will not be marked as such.
Password-protected files
Passwords are the simplest type of key. They are used for decrypting PDF and MS Office documents and archives.
You can add passwords one by one.
IBM Notes ID files
To decrypt IBM Notes NSF files, so-called ID files need to be added to the key store. Select "IBM Notes ID Files" from Manage dropdown and click "Add…". Enter the location of an ID file and the password associated with the file. Click "OK" to add it to the store. Intella Connect will validate the ID file to make sure you entered the password correct. Repeat this for all ID files.
X.509 Certificates
To decrypt emails with S/MIME encryption, one or more X.509 certificates and private keys need to be added. Select "X.509 Certificates" from Manage dropdown and click "Import", then select a PKCS12 archive file (.p12 or .pfx file) that contains the keys. Intella Connect will analyze the key file and import all found certificates and keys.
Usually you can export the certificates and keys from a mail client in this format. Do not forget to include private keys as they are critical for decrypting the emails.
PGP keys
To index PGP-encrypted emails you will need to import the PGP private keys. Select "PGP Keys" from Manage dropdown and click "Import". Intella Connect can import ASCII armored PGP private keys (.asc files), but it is also possible to import key in binary format.
An ASCII armored PGP private key usually starts with the following text:
-----BEGIN PGP PRIVATE KEY BLOCK-----
Importing multiple .p12 files
At the moment it is not possible to enter multiple .p12 files in a single action, they need to be entered one by one. We have put this feature request on our roadmap for future development.
Please note that .p12 files can contain multiple certificates. Therefore, if your environment is able to export multiple certificates into a single .p12 file, or you can find a third party tool that merges them, you can effectively import multiple certificates at once.
Furthermore, note that you can copy the keystore files to another case. That way you can reuse the entered credentials if they apply to other cases/evidence sets as well.
Encrypted volumes in disk images
To decrypt BitLocker and APFS volumes in disk images, a correct password, recovery key or recovery file needs to be added. Passwords can be added via the "Passwords" option from Manage dropdown. "BitLocker Recovery Keys" and "BitLocker Recovery Files (.bek)" options should be used to add BitLocker specific credentials.
9.5. Custom columns
There may be a need to extract specific metadata fields and put them into separate columns. This is what the custom columns functionality can be used for. An example is extracting the "X-Mailer" header and putting it into a dedicated column "Email Client" column.
Custom columns are populated during indexing. Therefore, they need to be set up prior to indexing. If the custom column is added after indexing, re-indexing will be required to populate the custom columns.
To add Custom columns, navigate to Sources page and click on Custom columns button.
Click on the Add button to add a new custom column. Specify the name, description, and type of the column. The following column types are supported:
-
Text — The column can hold arbitrary text of any length.
-
Integer — The column can hold a whole number in range between -2,147,483,648 and 2,147,483,647.
-
Long Integer — The column can hold a whole number in range between -9,223,372,036,854,775,808 and 9,223,372,036,854,775,807.
-
Floating Point — The column can hold a 64-bit floating point number.
-
Boolean — The column can hold either True or False.
-
Date — The column can hold a date-time value.
The Extract Data section below shows which metadata fields will be used to populate the column. Click the plus sign button to add a new rule:
-
The Type option allows to restrict the rule to a specific file type or type category. By default, the type is set to "Any" which means that the rule applies to any item.
-
The From option defines where the metadata field comes from: Raw Data or Headers.
-
The Field option defines the name of the metadata field that should be extracted.
-
The Date Format option allows to specify a date format if this is a date column. The Language option can be used to tell which language should be used when parsing certain date elements, like day of the week or month names.
-
The Case Sensitive option can be used to specify whether the Field name is case sensitive.
It is possible to add more than one rule to a custom column. In this case the option below the table defines the way in which the extracted values should be merged. By default, the first non-empty value will be used. For text columns the values can also be joined together.
Once added, the new custom columns will appear in the column chooser of the Details table, in the Custom Columns section. The date columns will also appear in the Date facet panel, Histogram and Timeline views and can be used when defining Primary Date rules. Custom columns will also be shown in the Properties tab of the Previewer.
Examples of using custom columns:
-
Extract the email client information into an "Email Client" column:
-
Name: Email Client.
-
Type: Text.
-
Extract data from:
-
Type: Email Message
-
From: Headers
-
Field: X-Mailer
-
-
Extract the camera model information from JPEG photos into a "Camera Model" column:
-
Name: Camera Model.
-
Type: Text.
-
Extract data from:
-
Type: JPEG Image
-
From: Raw Data
-
Field: Model
-
9.6. Post-processing
After indexing has completed, the case owner can opt to refine the indexing results in a number of ways. These steps are kept separate from indexing as they typically contribute considerably to the processing time and disk space usage and, depending on the case at hand, may not be needed.
9.6.1. Tasks
Intella Connect/Node allows for the definition of "tasks". These are essentially compound processing steps such as searching for all items that match a certain keyword or keyword list and tag or export the results. These tasks can be defined and selected during source creation, which will run these tasks right after indexing. The tasks editor can also be reached by selecting Tasks from the File menu, which allows for defining and running the tasks at any point in time after index creation.
Each task consists of conditions, post-conditions and actions. A task must have at least one condition and one action.
A condition (Step 1 in the task dialog) defines a search query that select items from the case. Currently the following conditions can be defined:
-
A keyword search.
-
A keyword list search.
-
An MD5 list search.
-
An arbitrary Saved Search, which can combine all of Intella’s search facets.
-
A tag, possibly assigned by one of the tasks executed earlier.
-
A date range search on all date fields.
-
An OCR Candidates search. It allows to select various categories of images and documents that are usually subject to OCR.
-
All items search
A task may combine any number of conditions. The match option controls if the items should match all specified criteria or at least one of them, i.e. a Boolean AND or OR of the specified conditions.
An optional list of post-conditions (Step 2) specify how to transform the item set retrieved in the previous step. Possible post-condition steps are:
-
Deduplicate results
-
Identify parents of the retrieved items
-
Identify children of the retrieved items
-
Suppress irrelevant items
It is possible to define multiple post-conditions for a single task. The first post-condition is applied on the set of items resulting from the conditions in Step 1. Subsequent post-conditions are applied on the outcome of the preceding post-condition.
Finally, task actions (Step 3) define the operations that will be applied to the items resulting from the previous steps. The following actions can be defined:
-
Tag all found items with one or more tags. The tag(s) can optionally be inherited by items in the same family hierarchy and/or by duplicates of the found items.
-
Set custodian attributes.
-
Flag all found items.
-
Add a comment to all found items.
-
Export all found items using an export template.
-
Export the metadata of all found items to a CSV file. Click the Configure button to set the CSV file name and path and to select the metadata fields that are to be included.
-
Start an OCR process on the found items using the embedded ABBY Fine Reader, by connecting to an ABBYY Recognition Server or by running an external OCR tool.
-
Start a Content Analysis process on the found items for the selected entity types.
-
Start the email threading process on the found items.
-
Generate custom IDs for the found items.
Every task may define multiple actions that will be applied sequentially to the determined item set.
Tasks can be exported to a file so that they can be reused in other cases. These files are self-contained, i.e. when the task involves MD5 hash lists or keyword lists, these lists are embedded in the task file.
Tasks are executed in the order they have in the task list. This makes it possible to "pipeline" tasks, e.g. use one task to assign specific tags to a subset of the items and use a subsequent task that is based on those tags. The order can be changed by selecting a task and using the "Move Up" and "Move Down" buttons.
9.6.2. Custodians
The Custodian attribute can be assigned to items after indexing. This can be used to represent the custodian of the evidence items. To enable automated assigning of multiple custodians in a folder source, the root folder should organize the evidence in subfolders, one subfolder for every custodian. If the evidence folder is structured in this way, the "Indexing Tasks" step in the Source Wizard will contain a "Custodians" tab that opens the settings panel for automated assigning of multiple custodians. By default the custodian names are set to equal the subfolder names. It is possible to alter the used custodian names in the table. This Custodian value will be assigned to all items obtained from the evidence files within the respective subfolder. For other types of sources, the "Indexing Tasks" tab contains a text field for setting a single custodian name. Besides the above method, the Custodian attributes can also be set or changed using the "Set Custodian" indexing task with an arbitrary condition, or edited manually in the Details’ right-click menu.
9.6.3. Thumbnail generation
To improve the images loading speed you can pre-generate thumbnails after processing case sources. You can learn more about this in Reviewer’s manual > Preferences > Thumbnails Pre Generation .
9.6.4. Importing an overlay file
An overlay file is a file that contains additional information about the current items in a case. By importing the overlay file, the metadata of these items can be extended.
Intella currently only supports the importing of tags, tag columns, comments and metadata columns (both regular and custom). Importing overlay images, texts, and natives may be added in a future release.
The following file formats are supported for overlay files:
-
Concordance/Relativity load file (.DAT)
-
Comma Separated Values file (.CSV)
To import an overlay file you need to add another Load file source. Set the Import operation to Overlay and specify the location of the file. You can optionally use a previously saved template.
On the "Configure delimiters" page you can set the file encoding, delimiter settings and date formats. Please see the Load files section for a description of these options.
On the "Map fields" page you need to specify the identifier field and type. This is how Intella Connect will match items in the overlay file with the existing items in the case. There are four options for matching items:
-
By Document ID, also known as DocID. This is the most common way to import new tags and comments into previously imported load file.
-
The Item ID is the internal item identifier used by Intella Connect. This is the simplest way to process your data using an external tool and then import the result back into Intella Connect.
-
By MD5 Hash. This is the most flexible way of matching items. Using the MD5 hash it is possible to transfer tags from one case to another. Note that the imported tags will be applied to all copies.
-
The Item URI is an internal item identifier that is not changed after re-indexing the case, but it may be changed when re-indexed with a newer Intella Connect/Node version due to changes in the crawling software. This method can be used to transfer tags when other options are not suitable, e.g. when migrating tags from a case backup to a live case that has been re-indexed in the meantime.
The “Also overlay metadata shared with duplicates” option is used to control whether the imported metadata will be applied to all duplicates as well (see the limitations below for this setting).
Current limitations:
-
Overlaying images, texts and natives is not supported.
-
Location and MD5 columns cannot be overlaid.
-
It is not always possible to overlay metadata for regular items, not imported from a load file. For example, if an item from a non-load file source has duplicates, then the overlaid metadata should be applied to all duplicates as well using the “Also overlay metadata shared with duplicates” option. Otherwise, the overlaid metadata might not be applied. There is no such limitation when overlaying data to items from a load file source. In this case, each record in the overlay is unique and the “Also overlay metadata shared with duplicates” option should be unchecked.
-
Metadata imported into regular and custom columns will be lost after re-indexing the case.
Please see the Adding sources > Load file section for a description of the remaining options on this page.
9.6.5. Content analysis
Content analysis can be scheduled to run either as an indexing Task or by a reviewer directly from a shared case. The later procedure is described in Reviewer’s manual > Details panel > Content analysis .
9.6.6. Email threading
Email threading can be scheduled to run either as an indexing Task or by a reviewer directly from a shared case. The later procedure is described in Reviewer’s manual > Email threading .
9.6.7. Near-duplicates Analysis
A technique to reduce the reviewing time is Near-duplicates Analysis. It splits a selected set of items into several groups based on the similarity of their text content. Every group is centered around a "master item" which is the most common near-duplicate for other items in the group (usually, an item with the largest text size). Other items are included in the group if they are detected with an appropriately high similarity score to the master item. The similarity score is based on an amount of co-occurrent text fragments and represents a number between 0.0 and 1.0. The master item and its exact duplicates are assigned with a score of 1.0 in their group. The rest group items have the scores between 1.0 and a threshold value specified by a user before the analysis.
To start the Near-duplicates Analysis process, select multiple items in the Details table and select "Near-Duplicate Detection" in the right-click menu. In the dialog window, move the "Similarity threshold" slider to set the desired minimum similarity score for items to be included in near-duplicate groups. Select the "Ignore excluded paragraph" option if you don’t want the content of excluded paragraphs to be considered by the similarity calculation algorithm.
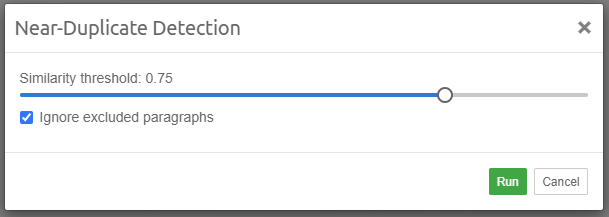
Upon completion, near-duplicate groups are available for search in the "Near-duplicates" facet (see Reviewer’s manual > Near-duplicates section for details). Additionally, "Near-Duplicate Group", "Near-Duplicate Master Item" and "Near-Duplicate Score" columns can be set visible in the Details table to show the group names, master item IDs and similarity scores of items included in near-duplicate groups.
To query for Near-Duplicates of specific item that was subject to Near-duplicates Analysis, select the item in the Details table, right-click, and choose "Show Near-Duplicates". This option will be enabled only when selected item has at least one Near-Duplicate.
The total set of analyzed items and items included in near-duplicate groups are available for search as "Analyzed for Near-Duplicates" and "Has Near-Duplicates" nodes of the Features facet.
9.6.8. Custom IDs
“Generate Custom IDs” task allows to assign each item a unique custom ID taking families into account. Such IDs can often then be used in load file exports. Or it can help to easier identify item position or role in its family.
Items are processed in hierarchical order starting from the roots and exploring as far as possible along each branch before backtracking (Depth-first search). Items that are on the same level of hierarchy are processed in the order defined by Sort Order setting. If the selected items don’t contain complete families, the task will add the remaining items automatically.
Click Configure button on the task action panel to configure the numbering settings:
-
Prefix defines the prefix for custom ID.
-
Start at defines the starting number. If the Auto option is selected, Intella will use the next available number for this prefix or 1 if the prefix has not been used before. The Manual option allows to set a custom starting number.
-
Number of digits defines the number of leading zeroes that will be used in the number.
-
Child numbering defines the way how child documents are numbered relatively to their parents:
-
Add suffix. Child document ID is derived from its direct parent ID by adding Child Suffix Delimiter (see below) and the child number starting with 1. For example, if the parent item is ABC123, then its children will be numbered as ABC123.001, ABC123.002 and so on.
-
Use sequential number after parent. Child document ID will use the next consecutive number after its parent. For example, if the parent item is ABC123, then its children will be numbered as ABC124, ABC125 and so on.
-
-
Child Suffix Delimiter defines the delimiter that is used to separate parent and child IDs when Add Suffix option is selected.
-
Sort Order defines the column by which items located on the same hierarchy level will be sorted by.
-
Family defines how Custom Family ID column is constructed:::
-
Use Parent ID. Custom Family ID is the custom ID of the top-level parent in this family.
-
Use Family Range (Start-End). Custom Family ID is the custom IDs of the first and last items in this family separated by hyphen.
-
-
If Overwrite Existing option is selected, Intella will overwrite any existing custom and custom family IDs.
Generated custom IDs can be used in load file export and can be imported from a load file.
Custom IDs don’t change when the case is re-indexed, provided that the case is re-indexed using the same version.
9.7. Showing Source Details
To see the configuration of a source, go to Sources page. When you click on the "Details" button for a respective source, its details will be shown in a modal window. The name, type and time zone are shown as well as source type-specific details such as files or folders to index, indexing options, etc. See the section on adding sources above for the precise meaning of these settings per source type. Presented properties are not editable.
To close the window click on the "Close" button.
9.8. Editing Sources
To edit the configuration of a source, go to Sources page. When you click on the "Edit" button for a respective source, its editable fields will be shown in a modal window. The name and time zone are editable for every source. The rest of editable fields depends on the source type.
To save your changes click on the "Add" button. If click the "Cancel" button then any changes you’ve made will be discarded.
9.9. Removing Sources
To remove a source, go to Sources page and click the "Remove" button for a respective source.
|
Source removal is an expensive operation as it requires several of case databases to be altered. |
Sources can be added again after removal, by following the normal "Add Source" procedure.
Removing a source will remove:
-
The data, metadata, OCR results and (load file) images associated with the removed items, except for those that are still associated with item duplicates originating from other sources.
-
Any redactions and comments associated with the removed items.
-
All references to the removed items in tags, flags, batches, export sets and custodian sets.
What remains after source removal are:
-
References to the source and the evidence items contained in the logs files.
-
References to the numeric item IDs in the event log.
-
MD5 hashes of item locations.
-
Metadata extracted by the email threading procedure, such as Message-ID headers and Conversation Index properties.
These artifacts are typically not visible to the end user, but could be obtained by reverse engineering of the case files. Please consider this when handing over a case with removed sources to an opposing party.
10. SSL setup guide
10.1. Preface
In order to enable usage of the HTTPS protocol in Intella Connect, you need to supply it with a valid Java keystore. Keystore is considered valid when:
-
it contains exactly one Private and Public Key pair
-
the certification chain belonging to this Key pair is trusted by embedded Java Runtime Environment
Starting with version 2.2, Intella Connect can guide you through the process of creating a valid keystore and manage as many of them as you wish.
|
Versions predating 2.2 required user to manually create keystores. Guides for doing so are still available in Appendices section. |
|
SSL 3.0 is no longer supported, to protect against the POODLE attack. |
10.2. Overview of the SSL settings UI
Keystores can be managed in a dedicated Settings section labeled SSL. This UI allows to create and manage as many keystores as you wish. That feature comes handy if you need to create new keystores for other domains or Intella Connect/Node servers. The following screenshot illustrates a situation where administrator created two keystores: SSL for 2018 and SSL for testing.
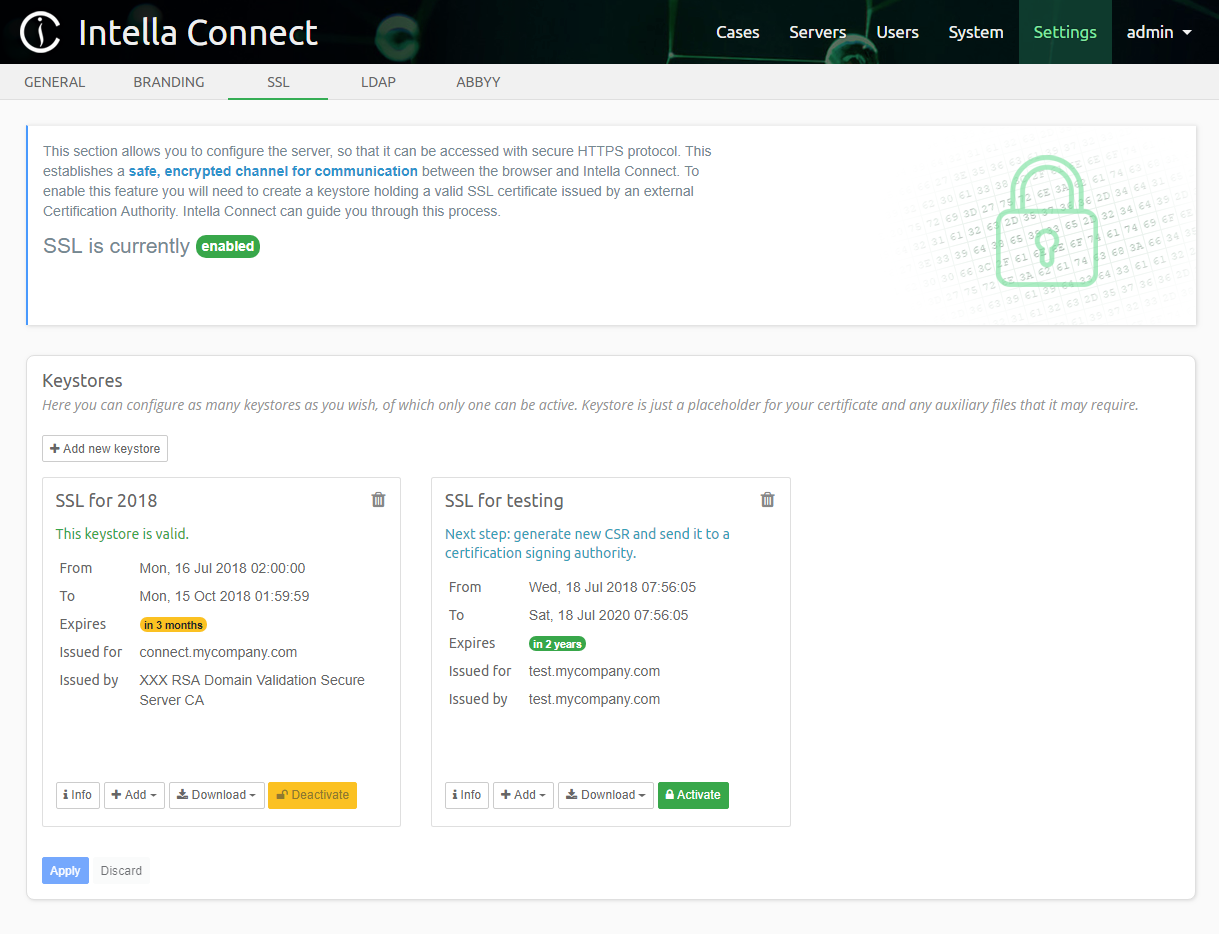
The top panel with a green padlock informs you that the SSL integration is enabled. When SSL is not active, the message would change to disabled and the padlock would be red.
The panel labeled Keystores contains a list of current keystores available in this Intella Connect instance. It also offers button Add new keystore which opens a simple wizard. Each keystore is represented by a card listing basic information about it. Concretely:
-
name - a human friendly name of the keystore. It must be unique, meaning that you can’t have two keystores with the same names.
-
status - helper message informing you if the keystore is valid, or what steps are needed in order to make it valid.
-
From and To - represents a date range for which the SSL certificate in this keystore was issued
-
Expires - gives you a quick overview of how much time left before the SSL certificate in this keystore expires
-
Issued for - the domain for which the SSL certificate is issued
-
Issued by - the name of the Certification Authority which signed the SSL certificate. For self-signed certificates that will be the same value as the Issued for field.
Besides that information each card will also contain buttons which allow you to run certain actions on given keystore.
|
It’s very important to remember that each action performed in this UI (ex. creating new keystore, adding certificates, setting as active, etc.) will not be saved unless you click Apply button at the bottom of panel. This works exactly the same as other Settings sections. |
10.3. Creating a new keystore
To start the process click on the Add new keystore button. This will open a two-steps wizard. While the goal is to create a keystore, the wizard must first establish if you are already in possession of a valid SSL certificate. This is illustrated below:
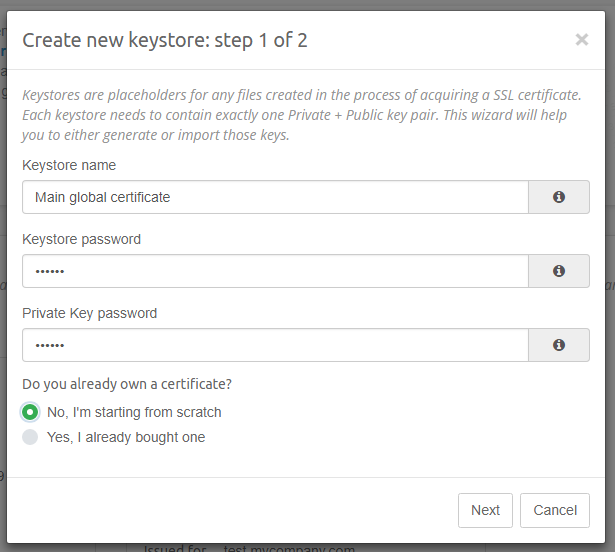
Fields:
-
Keystore name - unique identifier (and also a human friendly name) for the keystore. This value must be provided and has to be unique.
-
Keystore password - each keystore is protected with a password. Please choose a strong password and make sure you don’t lose it, because it cannot be recovered. This value is required.
-
Private Key password - Private Key is the most valuable part of the keystore, so it should be protected with a separate password. This value is required.
-
Do you already own a certificate? - please select Yes… if you already have a valid SSL certificate and you wish to install it. Selecting No… will cause a brand new Private and Public Key pair, and self-signed certificate to be generated.
-
Do you know the Private Key used to generate your certificate? - if you selected Yes… in the previous question, then you will be asked if you know your Private Key. Having the Private Key is mandatory to properly import an existing certificate (see note below).
|
Remember that having a Private Key is required just when creating a keystore for an existing SSL certificate. This is often causing confusion with people who already paid for an SSL certificate and think that they can now just import it to Intella Connect. Remember that "an SSL certificate" is technically just your Public Key signed by someone of trust. In order for the server to perform decryption it must apply the Private Key on the data coming through the secure HTTPS channel. That’s why having a SSL certificate is just a part of the equation, and you must also have the Private Key. Most certification providers offer a shortened procedure of certificate creation by keeping the Private Key in their possession if they also host the website when the certificate is used. This is sometimes causing confusion for our clients because the existing certificate cannot be used unless you also receive the Private Key from the provider. |
The next step depends on the fact if you choose to import an existing certificate. If you decided to create new keystore from scratch, then you will be asked to provide a domain and some information about your company. That data will become a part of your self-signed certificate. In the process we are also generating a RSA 2048 Private Key for you which will be placed into the new keystore. However, if you chose to use an existing SSL certificate, you will be asked to provide this certificate along with a Private Key which was used to generate it. Both variants along with fields definitions are listed below:
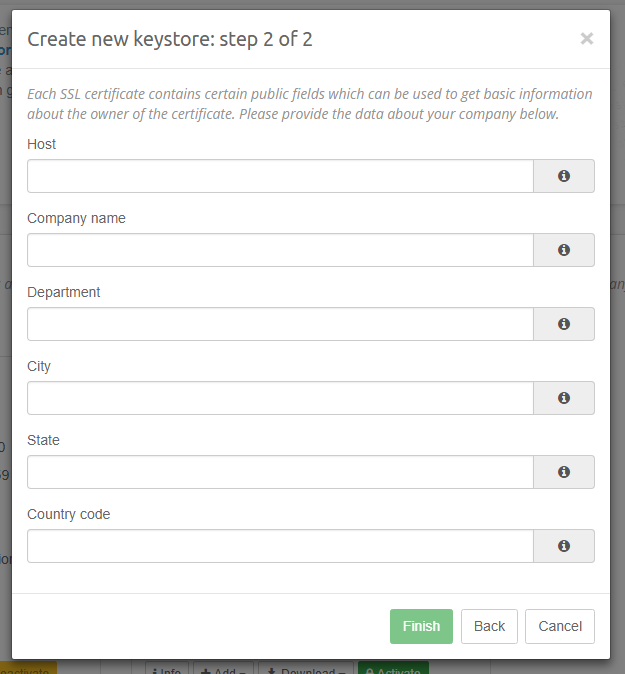
Fields:
-
Host - specifies the host (usually domain) under which Intella Connect will be accessible. Please make sure that you specify the proper value here and take your internal networking rules under consideration. Your certificate will only be valid when you access Intella Connect with this exact host. A typical value would be something like connect.mycompany.com or review-mycompany.com. Using IPs is allowed but not recommended. This field is required.
-
Company name - a human-readable name of your company. This field is required.
-
Department - Optional department name.
-
City - Optional name of the city in which your company/branch is located.
-
State - Optional name of the state.
-
Country code - Optional country code. Use "US" for United States of America.
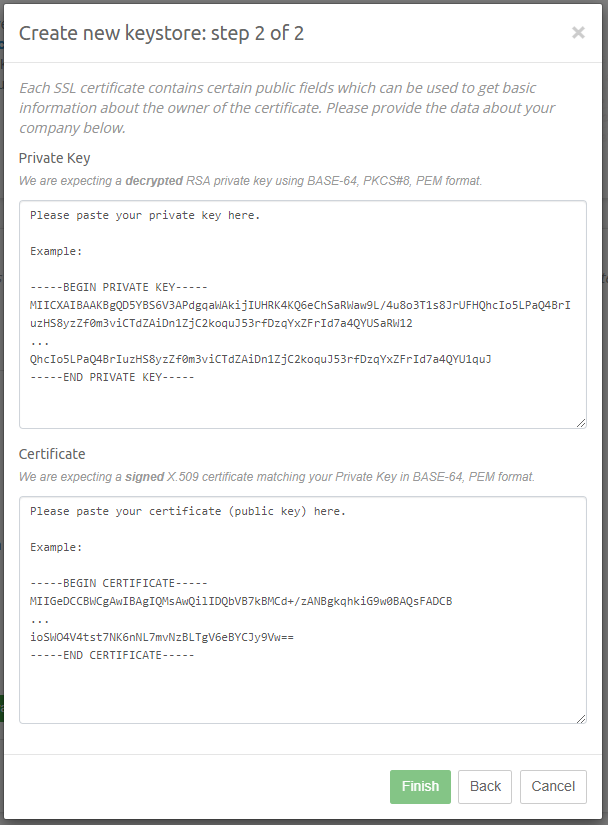
Fields:
-
Private Key - This field is required and represents the Private Key that was used to generate the SSL certificate which you wish to import. It must have the following characteristics:
-
it must use RSA algorithm
-
it cannot be encrypted
-
it must be of PKCS#8 format
-
it must be expressed as PEM
-
it cannot be binary format and must use Base64 encoding
-
-
Certificate - This field is required and represents the SSL certificate which you wish to import. It must have the following characteristics:
-
it must match the Private Key you supplied earlier
-
it must be of X509 format
-
it must be expressed as PEM
-
it cannot be binary format and must use Base64 encoding
-
After you properly fill in all required fields the Finish button will be activated. Once clicked, a new keystore card will be added to the list. You can now use additional action buttons to modify the state of your keystore.
|
We recommend to Apply your changes as soon as you create any new keystore. Accidental loss of your settings (for instance, by navigating out of SSL settings and ignoring the warning about unsaved changes) will make it impossible to retrieve contents of this keystore in case you’d need it in future. |
10.4. Actions
Each keystore in the list is represented by a separate card. There are several action buttons located on those cards:
-
Trash icon - permanently deletes the keystore from file system and the database. This action requires a confirmation through a modal window to prevent accidental damage.
-
Info - opens a modal window which allows to inspect keystore contents.
-
Add > Trusted chain certificate - opens a modal window which allows to add a trusted chain certificate. This allows to build up the certification chain. You should use that feature to add intermediate and root certificates belonging to your Certification Authority (certificate provider). CAs usually include two or more such certificates.
-
Add > Signed SSL certificate - opens a modal window which allows to add your SSL certificate. This is the certificate which was issued for your domain in reply to a Certification Signing Request (CSR).
-
Download > Keystore - downloads the current contents of the keystore. That file can be opened by a
keytoolutility or any other third party software capable of managing Java Keystores. -
Download > New CSR - generates and downloads new Certification Signing Request. This file is very often requested by a Certification Authority because it contains information needed to create a new certificate. You can create as many of those CSRs as you need and each invocation of this action will create a new one. Those files are not useful anymore once you get a SSL certificate in response and can be discarded.
-
Activate - sets the current keystore as active. Intella Connect allows only one keystore to be active and certificate stored in this keystore will be used to handle HTTPS traffic. For this change to take effect, a server restart is required.
-
Deactivate - if keystore is already active, then this button will allow to deactivate it. Deactivating a keystore will disable SSL integration. For this change to take effect, a server restart is required.
Once again please remember that changes made to a keystore are not immediately saved. To persist them you need to click the Apply button. In a case when server restart is required, appropriate message will be shown.
10.5. Inspecting keystore contents
Opening this view will allow you to inspect contents of your keystore to understand the details of it and troubleshoot certification issues. Most of information available relates directly to the certificate associated with the Private Key stored in this keystore. It will present to you a screen similar to the one illustrated below:
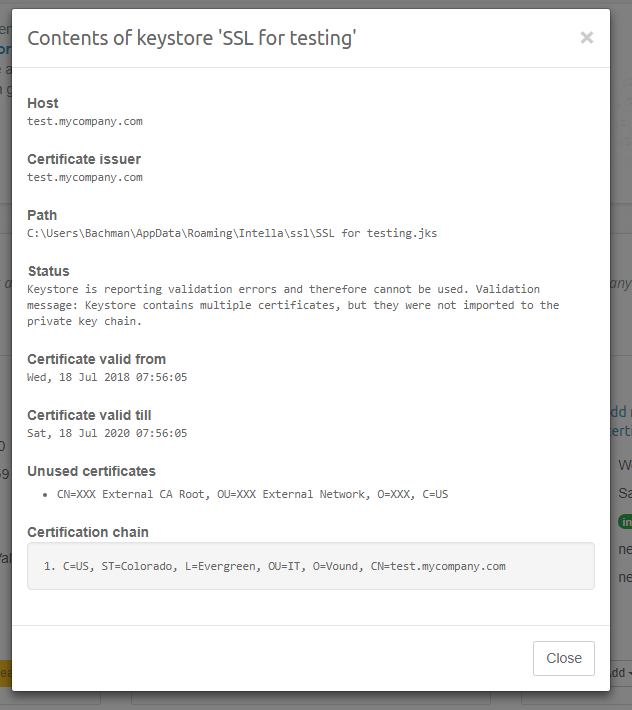
Fields:
-
Host - this matches the Common Name (CN) value of the certificate. This is the same value that you entered when creating new Keystore.
-
Certificate issuer - represents the signer of your certificate.
-
Path - shows the location of this keystore in file system. This value can change to a file in a temporary directory, if you have unsaved changes in your keystore.
-
Status - this field can give you some insights into what the status of your keystore is. It will inform you if it is valid and active. In case of any validation issues, they will be listed here too.
-
Certificate valid from and Certificate valid till - describes validity timeframe of your certificate
-
Unused certificates - list of trusted certificates which are present in your keystore, but are not a part of the certification chain. This field will be hidden if you have valid certification chain. If you see any entries here then this is a good indication that you haven’t imported every certificate received from your CA or that your CA is not trusted by Java Runtime Environment.
-
Certification chain - shows a list of certificates forming a certification chain. The first entry is the root of the chain, while the last one is your own certificate.
10.6. Recipes for managing a keystore
Below we describe in details few most typical scenarios for managing a keystore.
10.6.1. Creating a keystore with a new certificate
-
Click on Add new keystore and enter required information. Select No, I’m starting from scratch when asked if you want to add existing certificate. Click Next.
-
Enter required information in the next form. Make sure to use host which is appropriate to your domain / networking requirements. Click Finish.
-
Press Apply to save this keystore (makes sure you won’t lose your keys).
-
Press Download > New CSR to download new Certification Signature Request.
-
[Outside of Intella Connect] Present this file to your CA (Certification Authority). They will ask you to confirm that you are the owner of the domain. In the end you will be granted with: your certificate and a set of intermediate, trusted certificates.
-
For each intermediate certificate, press Add > Trusted chain certificate. Then open certificate file with a text editor, copy its contents and paste them into the form. Press Add button. If the certificate is of correct type, the modal window will be closed and you will see a confirmation message. If it’s not of proper format, please convert it to X509 certificate in PEM format encoded with Base64, then retry.
-
Press Add > Signed SSL certificate. Again, open the file containing your SSL certificate with a text editor and proceed just like in step 6.
-
Your keystore should report Keystore is valid. message.
-
Press Activate to set this keystore as active.
-
Press Apply to save your changes. Restart Intella Connect and navigate to your host with HTTPS protocol.
10.6.2. Creating a keystore for an existing certificate
-
Click on Add new keystore and enter required information. Select Yes, I already bought one when asked if you want to add existing certificate. Then select Yes, I can provide both Private Key and a certificate (signed Public Key). Click Next.
-
Obtain contents of your Private Key in PKCS#8 PEM format encoded with Base64 and copy it to clipboard. Then copy it to the Private Key field.
-
Obtain contents of your SSL certificate in X509 PEM format encoded with Base64 and copy it to clipboard. Then copy it to the Certificate field. In case you see any errors act accordingly, but make sure the formats of files are correct and that the Private Key matches the Certificate. Click Finish.
-
Press Apply to save this keystore (makes sure you won’t lose your keys).
-
For each intermediate certificate, press Add > Trusted chain certificate. Then open certificate file with a text editor, copy its contents and paste them into the form. Press Add button. If the certificate is of correct type, the modal window will be closed and you will see a confirmation message. If it’s not of proper format, please convert it to X509 certificate in PEM format encoded with Base64, then retry.
-
Press Add > Signed SSL certificate. Again, open the file containing your SSL certificate with a text editor and proceed just like in step 6.
-
Your keystore should report Keystore is valid. message.
-
Press Activate to set this keystore as active.
-
Press Apply to save your changes. Restart Intella Connect and navigate to your host with HTTPS protocol.
10.6.3. Renewing an existing certificate in a keystore
-
Press Download > New CSR to download new Certification Signature Request.
-
[Outside of Intella Connect] Present this file to your CA (Certification Authority). They will ask you to confirm that you are the owner of the domain. In the end you will be granted with: your certificate and a set of intermediate, trusted certificates.
-
[You can skip this step if intermediate certificates are the same as the ones already stored in keystore] For each intermediate certificate, press Add > Trusted chain certificate. Then open certificate file with a text editor, copy its contents and paste them into the form. Press Add button. If the certificate is of correct type, the modal window will be closed and you will see a confirmation message. If it’s not of proper format, please convert it to X509 certificate in PEM format encoded with Base64, then retry.
-
Press Add > Signed SSL certificate. Again, open the file containing your SSL certificate with a text editor and proceed just like in step 3.
-
Your keystore should report Keystore is valid. message.
-
Press Activate to set this keystore as active.
-
Press Apply to save your changes. Restart Intella Connect and navigate to your host with HTTPS protocol.
10.7. Enabling HTTPS support on Intella Node
When Intella Connect is using HTTPS protocol, it can still communicate with Nodes using plain HTTP. However, if your network is open to public access, we advise to setup HTTPS on Intella Node servers too. This section describes how to do it. Before reading it you should also get acquainted with Keystores database format.
|
If you configure Nodes to use HTTPs then you’ll need to set on the Use HTTPs switch when adding or updating them. See 'Intella Nodes' section in Intella Connect Dashboard section . |
Since instances of Intella Node do not have graphical user interface in which configuration could be performed, SSL configuration for Nodes is done in Connect administrator UI → menu → Servers → Nodes → click Configure button on a node panel → SSL view. Keystore database supporting both Intella Connect and Intella Node is the same, therefore it’s advised to first setup SSL on Intella Connect server and then on Intella Nodes.
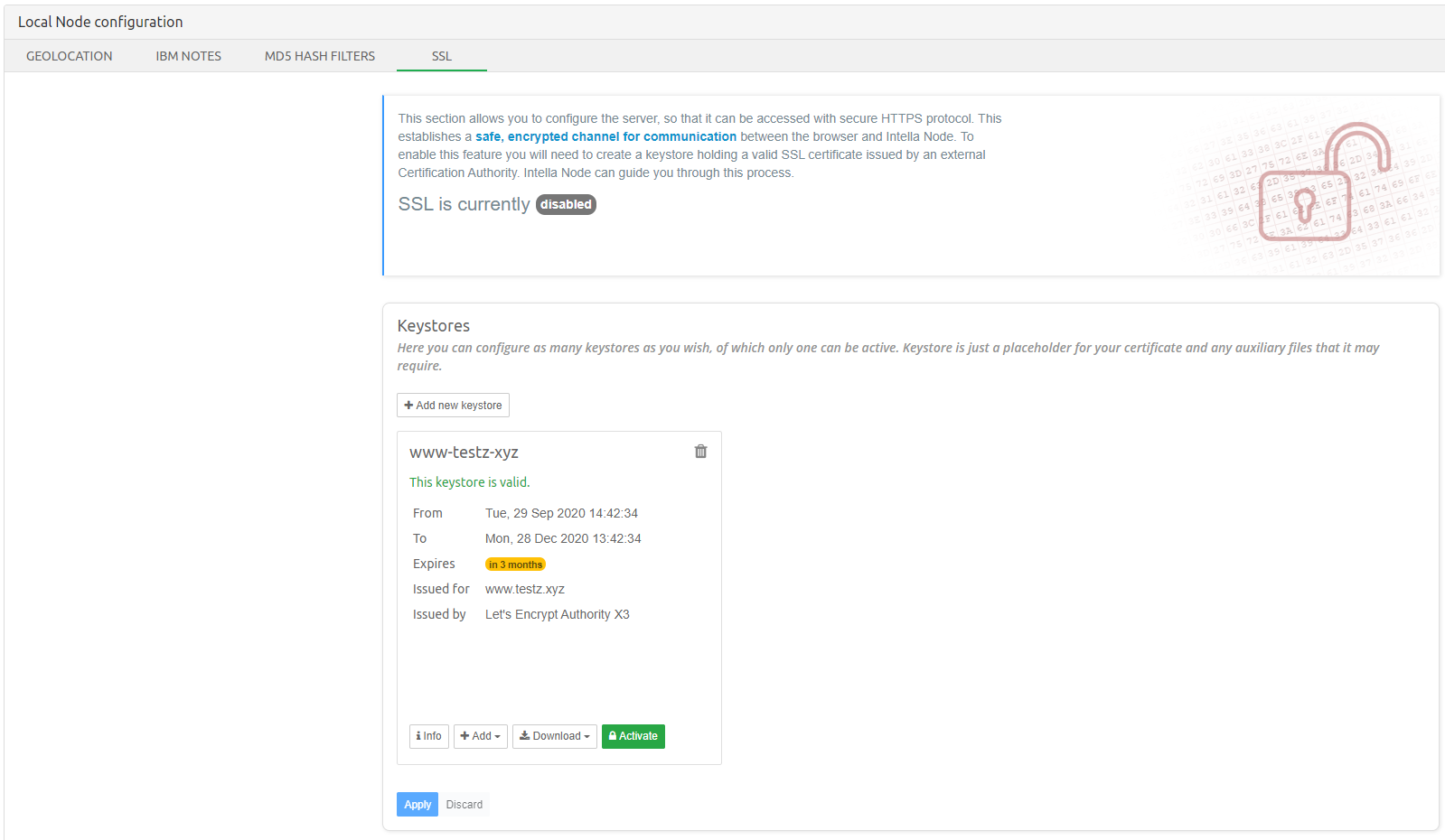
The actions that can be performed on keystores for Intella Node are the same as for Intella Connect. This means that Recipes for managing a keystore can be used to configure SSL for Intella Node.
Note that Intella Node needs to be restarted after applying changes to SSL configuration (as part of last step in recipes for managing a keystore).
After restarting Intella Node, the final step is to enable Use HTTPS switch of restarted Node server in Intella Connect’s user interface.

This will allow for both servers to communicate using secure HTTPS protocol.
10.7.1. Troubleshooting HTTPS support on Intella Node
Manual changes to configuration files can be performed to enable SSL in case of troubleshooting. Here are the necessary steps:
-
Configure a valid SSL keystore in Intella Connect, like described in the rest of this guide.
-
Locate the folder containing the keystore database, for example:
C:\Users\ConnectUserAccount\AppData\Roaming\Intella\ssl -
Shutdown Intella Node and locate the same folder on the Intella Node server, for example:
C:\Users\NodeUserAccount\AppData\Roaming\Intella\ssl -
Using text editor, open file
ssl-keystores.xmlon Intella Connect and copy one of its entries reflecting the keystore you created for Intella Node, for example:<keystore name='Keystore for Node' file='Keystore for Node.jks' password='Aywut0nB66XLOAyOiuHh4g' privateKeyPassword='bnfxJErKVntHYCPkzzkbnA' active='false'/> -
Edit the same file on Intella Node server and paste this line into the XML document. Make sure to change the value of active attribute from false to true. This will make the keystore active.
-
Locate the keystore file on Intella Connect server and copy it to the Intella Node server, for example:
C:\Users\NodeUserAccount\AppData\Roaming\Intella\ssl\Keystore for Node.jks -
Start Intella Node server. It should now be available using HTTPS protocol.
The final step is to enable Use HTTPS switch when adding or editing Node server in Intella Connect’s user interface.
This will allow for both servers to communicate using secure HTTPS protocol.
10.8. Verifying if HTTPS works correctly
To verify if your connection is secure try navigating to the host you selected when creating the certificate and specifying https as a protocol, for instance: https://connect.mycompany.com . You should be able to see the Lock icon in the web browser’s address bar, which is a proof that you are using a secure connection. You can also use tools built-in into your browser to inspect details of your certificate.
|
When HTTPS is enabled and working fine, then your server will no longer respond to requests made using plain HTTP protocol. |
10.9. Troubleshooting issues with SSL
Before a certificate is trusted, browser must verify that the certificate comes from a trusted source. This verification process is called path validation. This involves processing public key certificates and their issuer certificates in a hierarchical fashion until the certification path ends at a trusted certificate. Typically this is a root CA certificate. If there is a problem with one of the certificates in the path, or if it cannot find a certificate, the certification path is considered a non-trusted certification path. A typical certification path includes a root certificate and one or more intermediate certificates.
If the browser shows certificate warning, please verify certificate chain by reading the keystore using 3rd party tool. See references section of Wikipedia article on keystore.
10.10. Advanced: keystores database
Keystores database is very simple and consists of one XML file which lists keystore records. It is located in the following directory:
C:\Users\ConnectUserAccount\AppData\Roaming\Intella\ssl
Note: please substitute ConnectUserAccount with the account name under which you are running Intella Connect.
The XML index file is called ssl-keystores.xml. You can edit this file
manually, but you should only do so when the server is not running. Its
structure should be self explanatory, however few comments are
justified:
-
active attribute on keystore tags is a boolean variable representing which keystore is used by Intella Connect. It’s only allowed for one keystore
-
file attribute on keystore tags represents the keystore file located in the same ssl directory. This should never be modified.
-
password and privateKeyPassword attributes use proprietary encryption algorithm, which is not disclosed
Keystore index file can be saved and reloaded multiple times during the lifespan of the server.
10.11. Advanced: backwards compatibility
Intella Connect/Node versions predating 2.2 were using three preferences for managing the keystore file:
-
KeystorePath
-
KeystorePass
-
KeyPass
When Intella Connect 2.2 (and newer) starts, it will check for occurrences of those preferences and migrate the underlying keystore to the new database format. After the migration is finished, it will set the SslKeystoreMigrated=true preference, and during the next restart the migration will not be performed. This mechanism guarantees that configuration for versions predating 2.2 will not be affected (you can still start the old Intella Connect instance if needed).
If for some reason, you’d like to redo the migration, then you should set all three preferences listed above manually and remove SslKeystoreMigrated entirely.
|
Preferences are stored in:
|
10.12. Advanced: Using Self Signed certificates
|
We discourage the usage of Self Signed certificates. Those should only be used if there is specific reason to do so. |
If for some reason you would like Intella Connect/Node runtime
environment to accept a custom trusted certificate (usually a
self-signed one) you can do that by adding it to the cacerts file of
bundled Java Runtime Environment. Add it to both 32 and 64 bit variants
of JRE, but you must do that for both Intella Connect and Node in order
for them to communicate properly. You will also have to do that after
upgrading (or reinstalling) Intella Connect/Node because each version
uses independent JRE. The password for cacerts file is the default one
set by JRE: changeit.
The two cacerts files are available in these locations (make sure
%%INTELLA_CONNECT_INSTALLATION_DIRECTORY%% points to your Intella
Connect/Node installation directory):
%%INTELLA_CONNECT_INSTALLATION_DIRECTORY%%\jre\lib\security\cacerts
%%INTELLA_CONNECT_INSTALLATION_DIRECTORY%%\jre-x86\lib\security\cacerts
10.13. Advanced: Modifying supported protocols and cipher suites
If your security policy requires it, you may alter the way in which client and server communicate by specifying supported protocols and ciphers used. Intella Connect by default will not use SSLv3, relying on TLS instead. If you override disabled protocols, please make sure to add SSLv3 to the list.
The two settings that you can add to Intella’s Preferences are:
-
ServerDisabledSslProtocols - a white-space separated list of DISABLED protocols. Defaults to "SSLv3". Supported values are: SSL, SSLv2, SSLv3, TLS, TLSv1, TLSv1.1, TLSv1.2
-
ServerEnabledSslCipherSuites - a white-space separated list of ENABLED cipher suites. Defaults to an empty string, which results in supporting a vast stack of around 80 common cipher suites. Supply your own list if you need to have more fine grained control over which ciphers to exclude.
More details about both protocols and cipher suites can be found here: http://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html
Please note that at the time of writing this manual, specification requires to support following ciphers:
-
TLS_EMPTY_RENEGOTIATION_INFO_SCSV
-
SSL_DHE_DSS_WITH_3DES_EDE_CBC_SHA
You can learn more about recommended cipher suites in this online reference: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-52r1.pdf
10.14. FAQ
-
- I received a ZIP from my certificate provider. How do I know what’s inside there?
-
You should checkout documentation of your provider, as that is usually explained well there. A rule of thumb is that you usually receive at least two files. Certificates usually have some random name with a "crt" extension (because they are generated), whereas intermediate certificates have human friendly name. The latter often contain "root" or "ca" in the file name.
-
- How should I configure ports?
-
By default web browsers will try to connect to port 443 when HTTPS protocol is used. Therefore it’s best to change Intella Connect’s port to that value.
-
- How do I manually disable SSL?
-
You need to manually set all active attributes in keystores database to false. This is described in this section.
-
- I’m using different key/certification formats. What should I do?
-
Intella Connect’s UI only supports formats described in this guide. However, you can still create your Java Keystore by other means (including
keytoolutility or third party applications) and later import it to the database. This can be done by manually modifying the database or by leveraging backwards compatibility mechanism built into Intella Connect, which imports keystore based on filepath and credentials.
11. Single Sign On
11.1. Preface
Single sign-on (SSO) allows a user to log in with a single ID and password only once to gain access to any of several related systems. For example, a user logs in to Google account and afterwards that user can navigate to GMail, Google Cloud or Intella Connect without any of those systems asking for username and password.
From version 2.4, Intella Connect allows integration with third party SSO providers. The provider needs to be OpenID Connect (OIDC) standard complaint as described by the specifications: https://openid.net/specs/openid-connect-core-1_0.html Intella Connect uses Authorization Code Flow to authenticate user as described in OIDC specification.
11.2. Setup
In order for Intella Connect to integrate with OIDC provider and allow authentication via that OIDC provider, both OIDC provider and Intella Connect will need to be configured. Intella Connect allows multiple OIDC providers to be configured at once.
New section called SSO is now available in Settings panel:
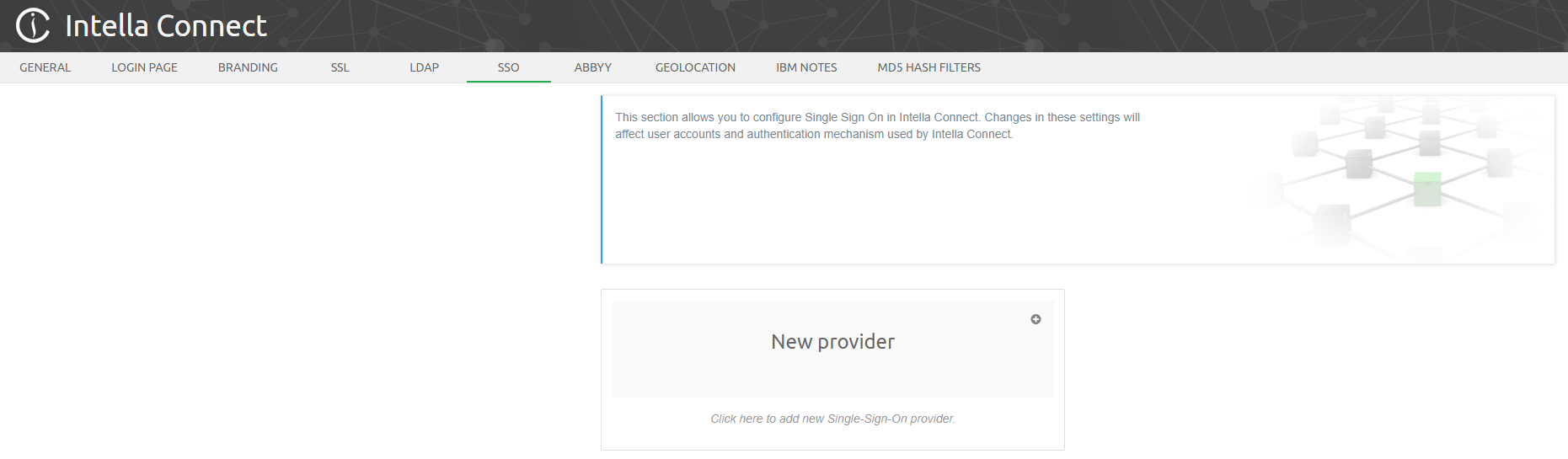
11.2.1. SSO with Intella Connect and Google
Prerequisite for this example is a G Suite account. Start by creating an account at Google Cloud Platform (https://console.cloud.google.com/) and log in:

Click on “Create project” button:
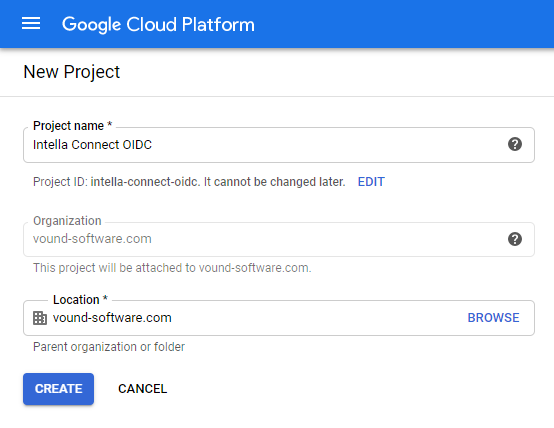
Fill Project name and click Create button. Wait for project to be created and to see following view:
In the navigation bar, choose API & Services → Credentials:
You will see following view:
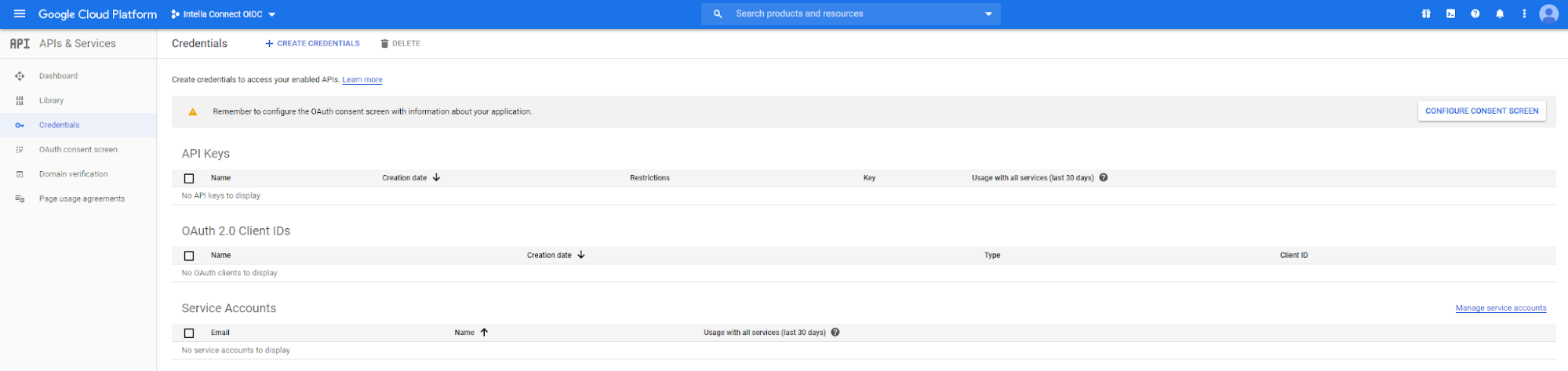
Click on “Create credentials” and choose “OAuth client ID”
You will see following view:

Click on “Configure consent screen” button:
Choose Internal and click Create button:
Fill out “Application name” field and click on Save button. You will see following view:
In left menu, go back to Credentials view and then click on “Create credentials” and choose “OAuth client ID”
You will see following view:
Choose Application type→Web application, fill out the Name and click on Create button.
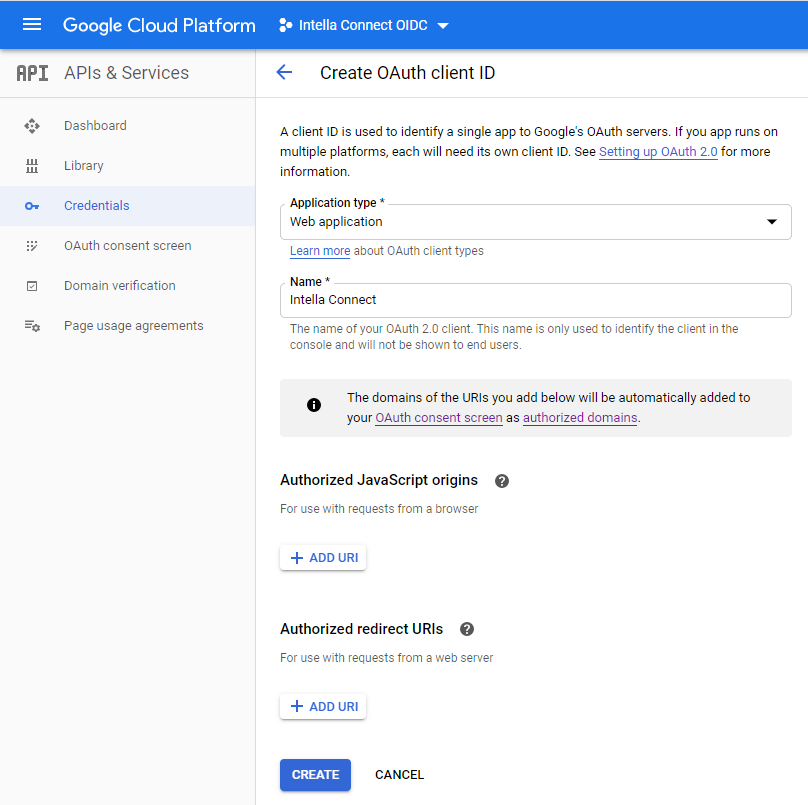
You will see following view:
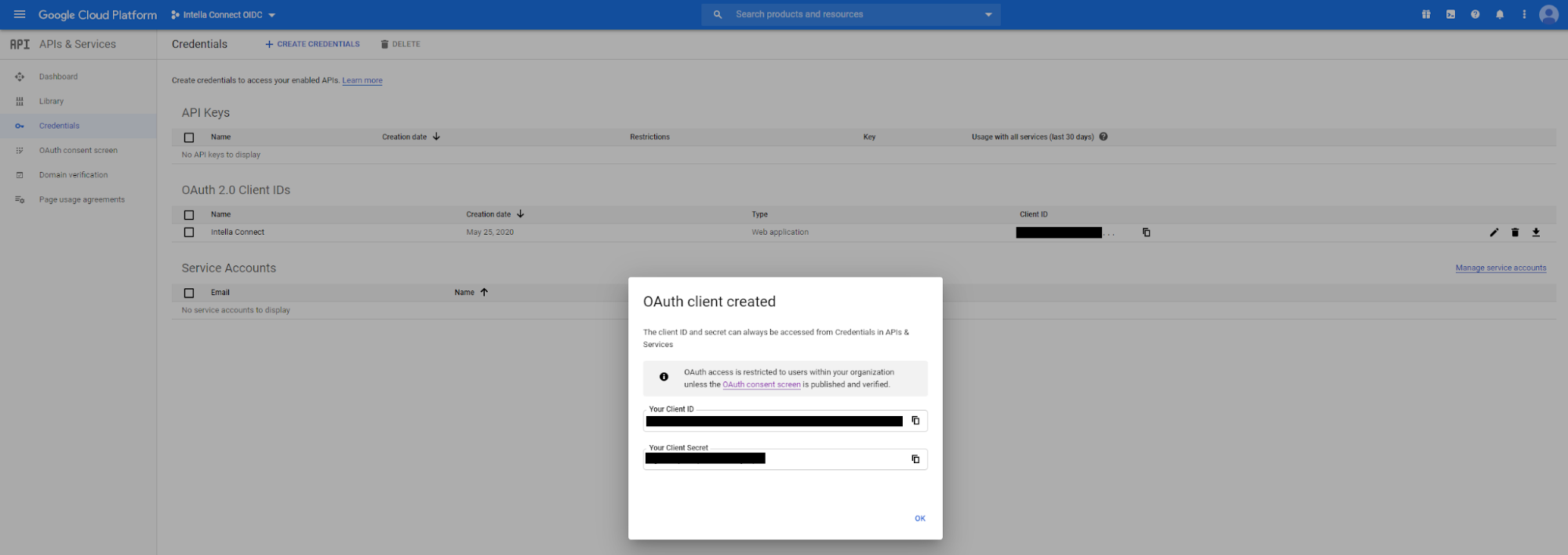
Switch to Intella Connect administration view, open SSO section in Settings panel and create new provider in SSO view of Intella Connect using provided information from OIDC provider:
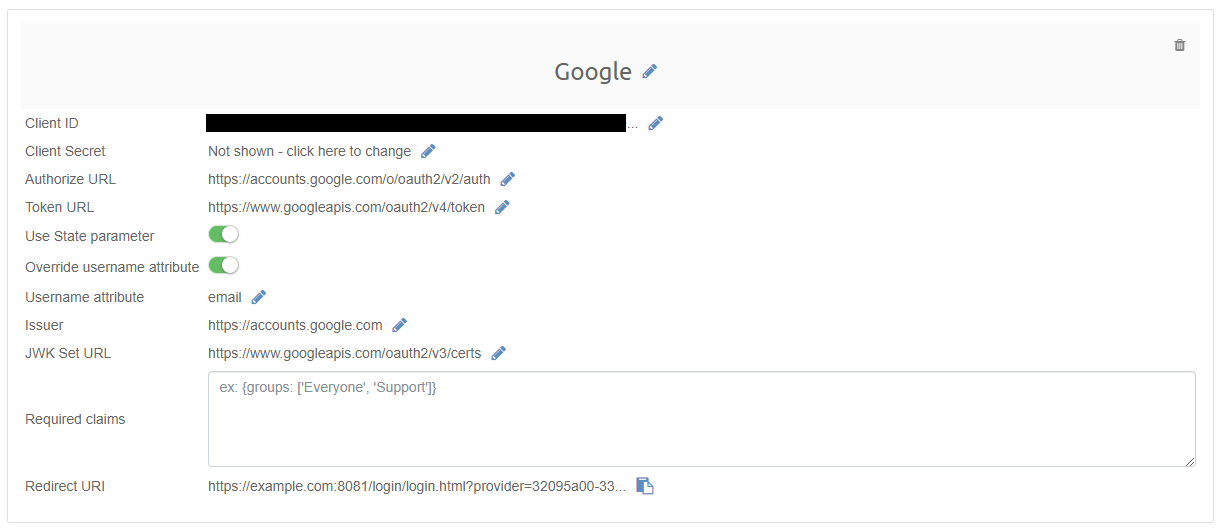
Click on Redirect URI to copy its content into clipboard. Go back to Google Cloud Platform and click on Intella Connect OAuth 2.0 Client ID:
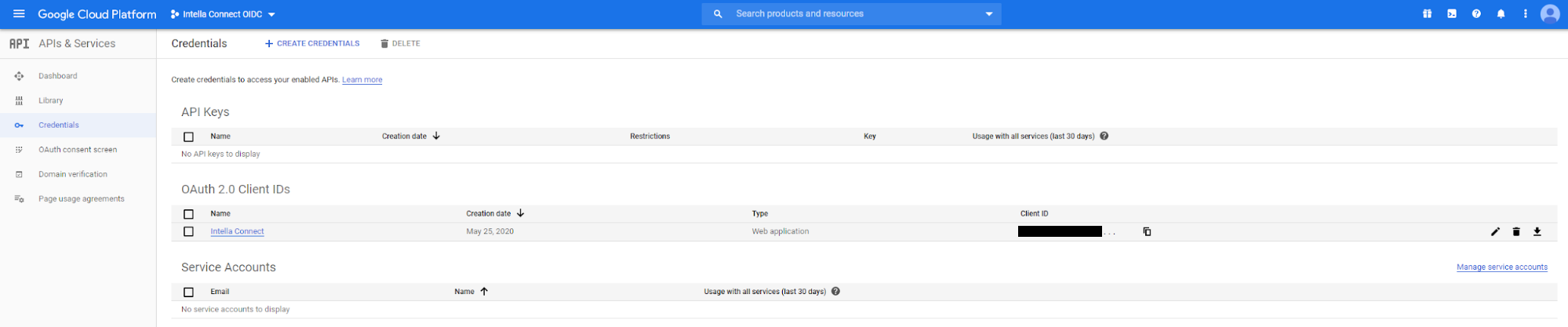
You will see the following view:
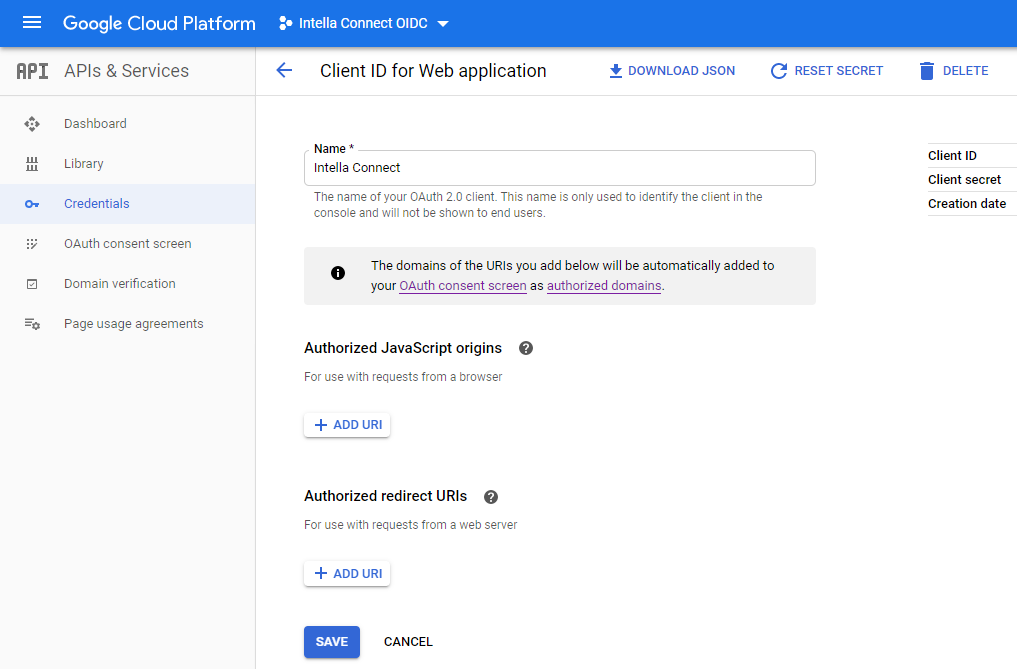
Click on the “Add URI” button in the Authorized redirect URIs section. Paste the URI from the clipboard and click the Save button.
You have finished the configuration and can now log in (as user defined in SSO provider’s list of valid users) to Intella Connect using the “Log in with Google” button.

11.2.2. SSO with Intella Connect and Okta
Prerequisite for this example is an Okta account. Create an account in Okta (https://www.okta.com/free-trial/) and log in.
In menu, go to Applications:
Click on “Add Application” button.

Click on “Create New App”
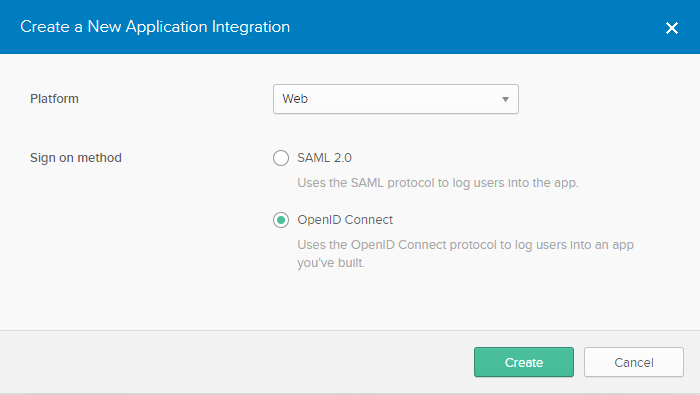
Choose Platform→Web, Sign on method→OpenID Connect. Click on the Create button.
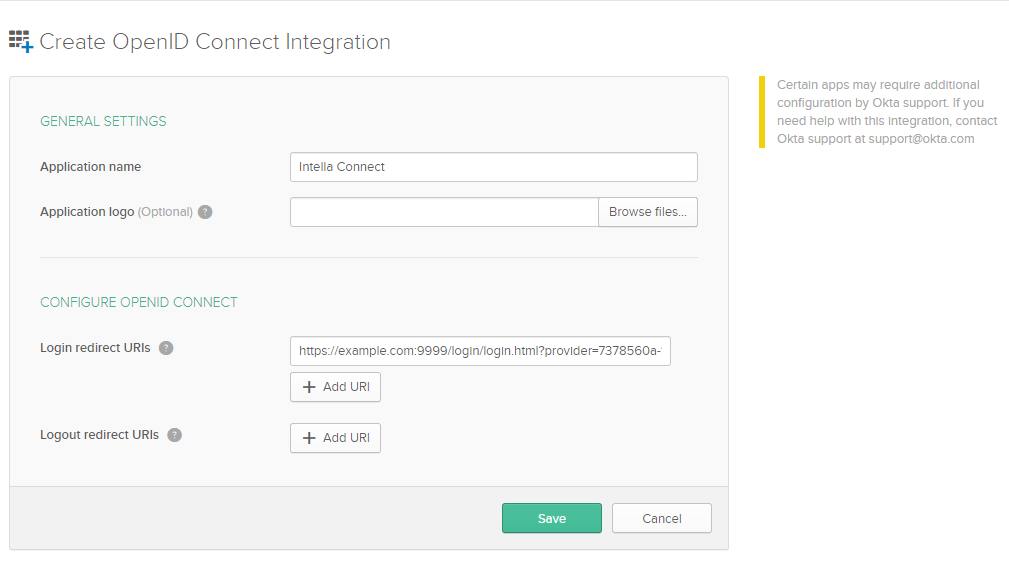
Fill in “Application name” and “Login redirect URIs” and click “Save”. If you don’t have correct “Login redirect URIs”, then it is fine to fill it with placeholder value and later edit it once obtaining the correct value.
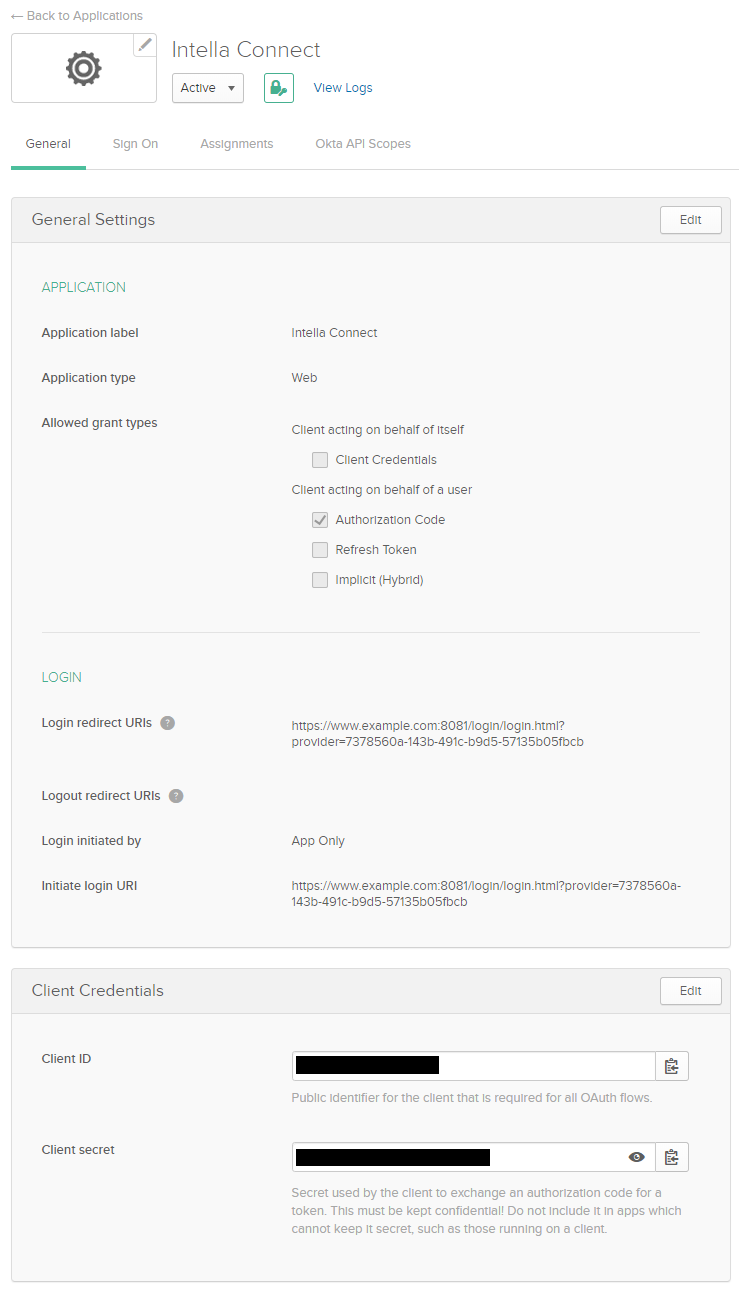
Create new provider in SSO view of Intella Connect using provided information from OIDC provider:
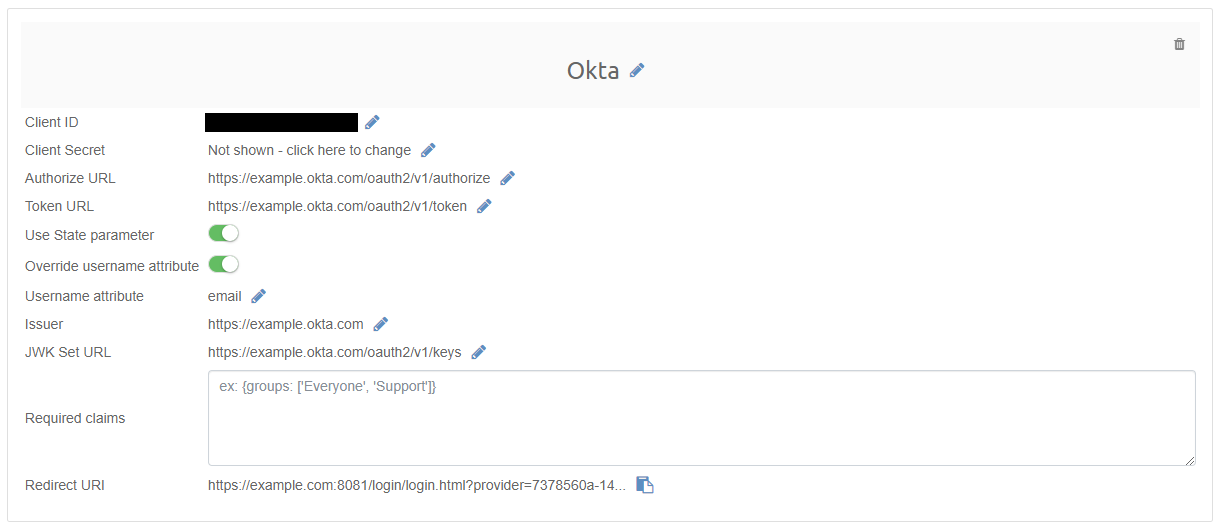
Click on Redirect URI to copy its value into clipboard. Go back to the configuration view in Okta and edit “Login redirect URIs”. Paste the URI from the clipboard and click the Save button.
Switch view from General to Assignments. Make sure that the people that should be able to login via this provider are in this list:
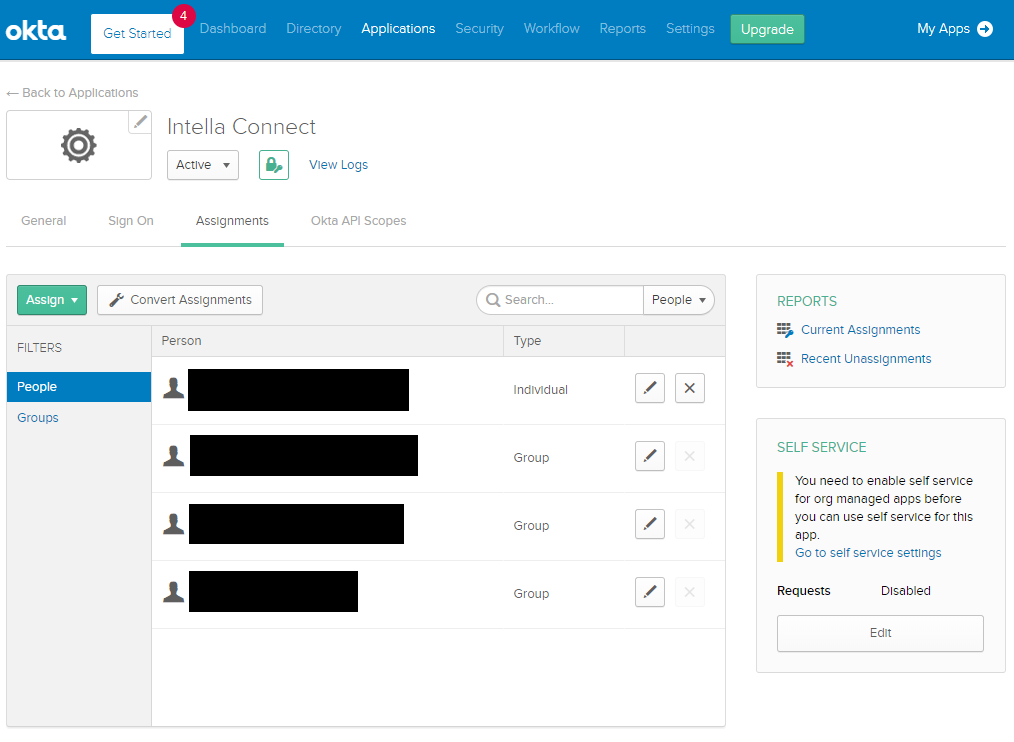
You have finished the configuration and can now log in to Intella Connect using the “Log in with Okta” button.
11.3. SSO with Intella Connect and third party provider
The above examples show how to configure SSO with Intella Connect and Google or Okta, but that doesn’t mean that any other provider cannot be used. Any SSO provider that is OIDC compliant and allows Authorization Code Flow can be used for SSO integration purpose. For more information on how to configure SSO on SSO provider side, consult with the SSO provider directly.
On Intella Connect side, the configuration consists of following fields:
Client ID, Client Secret, Authorize URL, Token URL and Issuer fields are provided by SSO provider and are compulsory. They allow Intella Connect to communicate with SSO provider in order to authenticate the user that is trying to log in.
Username attribute is by default set to "sub" as this is most common value. This field defines what the user’s identifier will be. It directly relates to username of user accounts that are shown in menu → Users → User Accounts.
This is important especially if user accounts already defined in Intella Connect are different people from those defined on SSO provider side. In that case a different Username attribute should be selected. On the other side, if it is expected that the users which have previously been logging in into Intella Connect using local account are the same people as those expected to log in via SSO, then the Username attribute needs to point to the same username values.
When user logs in via SSO account to Intella Connect, then the change password link is hidden for accounts logged in this way. Such accounts are now marked in C:\Users\user\AppData?\Roaming\Intella\auth\users.xml with oauth attribute. For example:
<profiles> <profile username='example-user1@vound-software.com' password='' avatar='' oauth='true'/> <profile username='example-user2@vound-software.com' password='' avatar='7b93a67a-d5d7-4065-8c76-a33b91c2f44f.png' oauth='false'/> </profiles>
This will also be shown in menu → Users → User Accounts view - account will have "SSO" label below username.
Note that when SSO user logs out of Intella Connect, then this logout only relates to Intella Connect session - login session in SSO provider is not ended. User needs to log out on SSO provider side in order to be logged out. This is expected behaviour.
11.4. Validation of SSO account login
ID tokens are used during SSO account login and they contain a number of attributes, or claims. These are protected with a digital signature, or message authentication code (MAC), to ensure the token’s integrity and authenticity.
The State parameter is recommended as stated in OIDC specification (https://openid.net/specs/openid-connect-core-1_0.html#AuthRequest), so by default it is turned on. It is advised to turn it off only if the SSO provider does not support it.
As mentioned above, the issuer field is mandatory and it will be used during validation of token.
For ID tokens secured with the RSA or EC signature (e.g. RS256), the field JWK set URL will be used during validation and therefore it should be filled. It needs to point to URL, which contains set of digital signatures of SSO provider.
For ID tokens secured with an HMAC (e.g. HS256), the client secret will be used to perform the validation. The field JWK set URL should remain empty and will be ignored by Intella Connect.
The Required Claims field allows declaring which claims of the ID token needs to be present in order to authorize a user - if this condition is not met, then user login is denied.
Since ID token is in JSON form, then the Required Claims field requires JSON object. That means that, for example, if claim "groups" is required to be an array type and contain "Support" and "Everyone" values,
then Required Claims field would be the following:
{
"groups": ["Support", "Everyone"]
}
Note that this validation is case sensitive, so if ID token contains field "groups" and Required Claims field will require field "Groups", then the result will be that every attempt to login via SSO will fail Required Claims validation.
Leaving this field empty means that a specific claims will not be required and any valid ID token will pass authorization.
11.5. Additional settings
Login via local accounts can be disabled by editing C:\Users\user\AppData\Roaming\Intella Connect\prefs\user.prefs and adding line:
AllowLocalAccountsLogin=false
When login via local accounts is disabled, then change password option is hidden - this is expected as such user should change their password on LDAP or SSO provider side as that is where their account resides.
Login via LDAP accounts can be disabled by editing C:\Users\user\AppData\Roaming\Intella Connect\prefs\user.prefs and adding line:
AllowLdapAccountsLogin=false
Note that even if login via LDAP is disabled, it will still be fetching the list of users from LDAP in order to display them in Connect admin→users view and also to allow assignment to cases/roles.
If login via both local and LDAP accounts is disabled, then the username and password fields are hidden. This is expected as the only user able to login using password is the admin account and other users need to login via SSO provider.
Administrator will then need to first click on Alternative login button, which will reveal username and password fields and allow login of admin account.
When validating ID token and using RS algorithm, then JWK set needs to be downloaded in order to compare keys. By default, the connect and read timeout are 500 ms. Due to network latency or error, this can result in user to be denied access during login even if valid credentials are provided. This can be seen in the logs containing following error message:
"Couldn't retrieve remote JWK set: Read timed out"
The timeout value can be changed by editing C:\Users\user\AppData\Roaming\Intella\auth\oauth-providers.json and modifying value of "jwkSetConnectTimeout":500 and "jwkSetReadTimeout":500.
If such field is missing, it should be added. Example configuration with all parameters except required claims (note that client ID and secret were replaced with dummy values):
{"uuid":"7378560a-143b-491c-b9d5-57135b05fbcb", "name":"example", "clientId":"example", "clientSecret":"example", "authorizeUrl":"https://example.com/oauth2/default/v1/authorize", "tokenUrl":"https://example.com/oauth2/default/v1/token",
"stateParam":true, "usernameAttributeSwitch":true, "usernameAttribute":"email", "requiredClaims":"", "validation":true, "issuer":"https://example.com/oauth2/default", "jwkSetUrl":"https://example.com/oauth2/default/v1/keys",
"jwkSetConnectTimeout":1000, "jwkSetReadTimeout":1000}
11.6. Troubleshooting
For troubleshooting purposes, ID Token validation can be disabled by editing C:\Users\user\AppData\Roaming\Intella\auth\oauth-providers.json and changing "validation":true to "validation":false.
Details about validation can be seen in the logs when changing logging level to DEBUG. Below is an example of such logging entry:
Validating using issuer (https://dev-620550.okta.com/oauth2/default), client ID (qwerty), algorithm (RS256), JWK set URL (https://dev-620550.okta.com/oauth2/default/v1/keys), JWK set connect timeout (1000 ms), JWK set read timeout (1000 ms) Required claims validation skipped due to required claims being empty.
12. LDAP setup guide
12.1. Preface
It is possible to integrate Intella Connect with an external Lightweight Directory Access Protocol (LDAP) providers. The entire configuration can be done in the User Interface, however this task is not trivial and it requires a good level of knowledge of LDAP schemes.
|
Configuring LDAP providers is considered an advanced task and should be undertaken only by a well qualified administrators. That is mainly because it impacts how passwords are sent between browsers and the server. |
In order to allow Intella Connect to communicate with an LDAP database one must add a so called "provider". Providers define the connection parameters to your LDAP database, as well as set of user defined queries which will control which LDAP entries can access Intella Connect. You can define as many Providers as you would like, however in most situations having just one would suffice. Any change in the providers list requires a full restart of Intella Connect server for the changes to take effect. It’s also up to the administrator to make sure that having multiple Providers will not result in having any name conflicts (where two accounts share the same username), as in such case results are unspecified.
|
In order for changes in LDAP providers to take effect you must restart Intella Connect server. |
12.2. LDAP connection parameters
First four provider settings that you will be asked for are listed below:
-
Name - is just a human friendly name that allows to manage providers better. It must be unique and it won’t be editable after you specify it.
-
Provider URL - it’s an URL pointing to your LDAP database, ex. ldap://192.168.1.1:10389
-
Authentication user DN - it’s a Distinguishable Name (DN) of the LDAP entry that will be used to make searches in your LDAP database. It must have enough privileged to perform LDAP lookups.
-
Authentication user password - simply a password for the user listed above
Those settings are essential for the Provider to communicate with an LDAP database.
12.3. Username Attribute (UA)
First thing to do next is to choose a so called username attribute (UA). All LDAP providers support "CN" attribute, but it’s not very user friendly to use this one as a username because it’s rather long and hard to remember. Users usually prefer signing in with either their email, or some simple username instead. Feel free to choose any attribute supported by your LDAP provider that uniquely identifies a user.
12.4. Customized LDAP queries
The rest of the wizard revolves around creating LDAP queries that specify how to determine which LDAP users should have access to Intella Connect. Those queries are explained below:
-
"Username to DN" query - Some LDAP providers will not return both DN and Username Attribute in the same record. That’s why Intella Connect allows to provide an auxiliary query which does the translation from UA to DN. This query is required even if UA is a part of your standard scheme that defines user record. In this case simply supply a query that returns user record for given username. It’s easy to understand on a working example: we would like users to log in to Connect using unique "email" attribute. We then fetch users from an Organizational Unit (OU) called "groupmembership" which only knows which user entries belong to it based on their DN. So we now must target additional OU called "users" to find what "email" does the given user have.
-
"DN to Username" query - This query is optional and usually won’t be needed with standard OpenLDAP and A.D. implementations. It does exactly the opposite for the previous query. Intella Connect will use it only in case when "All users accounts" query returns user accounts as a multi-value attribute.
-
"All users accounts" query - This is a query that should return all LDAP entries that you think should be entitled with an access to Intella Connect. Most probably those LDAP users are a part of some group defined in your schema. Therefore it’s usually enough to supply a query that would return all of users in this group. Depending on how your LDAP is organized, query might return multiple records (each representing single user) or just one record (where users are listed as a multi-value attribute). In the latter case you must provide an attribute name that will be used to pick up users' DNs.
-
"Authentication" query - First two queries allowed us to find which DNs can access Intella Connect and what human friendly username attribute should we use as their identifier. The third query is the most important one, because it will be used to authenticate user against an LDAP directory using credentials filled in on the login screen. You must make sure that this query returns exactly one entry for passed in username.
All of the queries listed above can use special, extended syntax.
|
Certain queries used in LDAP integration are being cached by Intella
Connect. Default cache size and eviction time (in minutes) can be
changed respectively by adding |
12.5. Extended syntax
When defining some of the queries you can use standard LDAP syntax with one small extension. When you use special keywords described below, those will be replaced (string replacement) each time with runtime values passed in by the user. In case the value is unknown at the time of query evaluation it will return "NULL" string instead.
-
&&USERNAME_ATTRIBUTE&&:this string will be replaced with the name of a username attribute that you defined in Step 3 of the wizard. -
&&USERNAME_VALUE&&:this string will be replaced with the value entered by the user on the Intella Connect login screen. -
&&USER_DN&&:this string will be replaced with the value of user’s DN.
12.6. Using LDAPS
To use secure LDAP connection, is it required to provide proper protocol name (ldaps://) in the Provider URL while configuring LDAP provider through the wizard. If different port than default port is used for LDAPS, then port must be also provided in Provider URL.
The certificate issued to your LDAP server must be recognized as trusted. If you are using self-signed certificate, then you should add the certificate of your CA to the trusted keystore used by Intella Connect runtime (Java). This keystore is located in Intella Connect installation directory. Steps to do that would be the following:
-
Download and install auxiliary KeyStore Explorer application (http://keystore-explorer.org/downloads.html)
-
Make a backup of 'cacerts' file from the 'jre/lib/security' subfolder of your current Intella Connect installation.
-
Using KeyStore Explorer, open the 'cacerts' keystore file.
-
Install certificate of your CA only (CTRL + T).
-
Restart Intella Connect and use your LDAPS provider.
|
Vound is not associated with developers of Keystore Explorer and we wish not to promote them. This guide serves explanatory purposes and should be treated as a learning material only. Vound cannot be held accountable for any misuse or damage that might be a result of using Keystore Explorer. If you feel uncertain if you should use it, please consult your IT specialists or keep on relying on keytool. |
12.7. Sample config for OpenLDAP with memberof overlay
Below you will find a sample configuration for a custom database running on OpenLDAP with memberof overlay. It assumes that the user entries are stored in "users" OU and that Intella Connect users belong to a group named "cn=Intella Connect Users Group,ou=groupmembership,dc=vound-software,dc=com".
Basic settings
-
Provider name:
OpenLDAP test -
Provider url:
ldap://192.168.1.107:10389 -
Auth user DN:
cn=admin,dc=vound-software,dc=com -
Auth user password:
SOME_PASSWORD
Query for getting single user details
-
Username attribute name:
mail -
Username to DN query Base:
ou=users,dc=vound-software,dc=com -
Username to DN query Filter:
(&&USERNAME_ATTRIBUTE&&=&&USERNAME_VALUE&&)
Query for getting all user accounts
-
Query base DN:
ou=users,dc=vound-software,dc=com -
Query filter:
(memberOf=cn=Intella Connect Users Group,ou=groupmembership,dc=vound-software,dc=com)
Query for authenticating single user
-
Query base DN:
ou=users,dc=vound-software,dc=com -
Query filter:
(&(&&USERNAME_ATTRIBUTE&&=&&USERNAME_VALUE&&)(memberOf=cn=Intella Connect Users Group,ou=groupmembership,dc=vound-software,dc=com))
12.8. Sample config for Active Directory
Basic settings
-
Provider name:
AD test -
Provider url:
ldap://192.168.56.2 -
Auth user DN:
CN=admin,OU=ConnectUsers,OU=Users,OU=MyBusiness,DC=site,DC=local -
Auth user password:
SOME_PASSWORD
Query for getting single user details
-
Username attribute name:
cn -
Username to DN query Base:
OU=ConnectUsers,OU=Users,OU=MyBusiness,DC=site,DC=local -
Username to DN query Filter:
(&&USERNAME_ATTRIBUTE&&=&&USERNAME_VALUE&&)
Query for getting all user accounts
-
Query base DN:
OU=ConnectUsers,OU=Users,OU=MyBusiness,DC=site,DC=local -
Query filter:
(objectClass=person)
Query for authenticating single user
-
Query base DN:
OU=ConnectUsers,OU=Users,OU=MyBusiness,DC=site,DC=local -
Query filter:
(&(&&USERNAME_ATTRIBUTE&&=&&USERNAME_VALUE&&)(memberOf=CN=Administrators,CN=Builtin,DC=site,DC=local))
13. Geolocation settings
The Geolocation section defines how the world map gets rendered in the Geolocation view and the Previewer’s Geolocation tab.

Intella Connect embeds a set of tiles for rendering this map. By default, this tile set is used. This embedded tile set enables use of the Geolocation views without requiring any configuration and/or network connection. The drawback of using this tile set is that the user can only zoom in six levels.
Another option is to integrate with a custom tile server. To enable use of such a server, select the Integrate with the tile server option. The Geolocation section will then expand to offer additional settings.
In the example above, OpenStreetMap’s tile server is used. You can use any tile server you wish by typing its address into the Tile server integration URL field. The format for the URL is dependent on the chosen tile server.
|
Note that to use a public tile servers, you need to ensure that you comply with the tile server’s usage policy. This is your responsibility, not Vound’s. |
The Min. zoom option defines the desired minimum zoom level in the user interface. This should be in the range of supported zoom levels of the chosen tile server.
The Max. zoom option defines the desired maximum zoom level in the user interface. This should be in the range of supported zoom levels of the chosen tile server.
The Tile Size (pixels) option defines the size of a single square tile. This value should match the size of the tiles which are returned by the tile server.
If the tile numbering order used by the tile server is reversed, then
this must be reflected in tile server URL with minus sign, for example
https://a.tile.openstreetmap.org/{z}/{x}/{-y}.png
{kind=link}
|
Important: Using a public tile server may reveal the locations that are being investigated to the tile server provider and anyone monitoring the traffic to that server, based on the tile requests embedded in the retrieved URLs. |
|
Tip: If the investigation system has no internet connection, a custom tile server can be set up on the local network. One way of how this can be achieved can be found at http://osm2vectortiles.org/docs/serve-raster-tiles-docker/. This is out of the scope of this manual and Vound’s technical support. |
13.1. Email geolocation
Email geolocation allows one to estimate the geographic location of an email’s sender using the sender IP address. This process takes place during indexing on Intella Node. The process and its caveats are described in Reviewer’s manual - Geolocation .
Determination of the geographic location of an IP address requires the presence of MaxMind’s GeoIP2 or GeoLite2 database on Intella Node. These databases associate IP addresses with geographic locations. The databases can be found here:
-
GeoIP2 database (commercial) – https://www.maxmind.com/en/geoip2-city
-
GeoLite2 database (free) – http://dev.maxmind.com/geoip/geoip2/geolite2/
See the MaxMind website for a description of their differences, beyond price. Please note that when using both of said databases, you will need to register and generate a license key, as described here - "https://blog.maxmind.com/2019/12/18/significant-changes-to-accessing-and-using-geolite2-databases/
The chosen database can be installed here by placing it in the following folder:
C:\Users\[USER]\AppData\Roaming\Intella\ip-2-geo-db
Alternatively, when you are on an Internet-connected machine, you can let Intella Node download and install the GeoLite2 database automatically by navigating to menu → Servers → Nodes → click Configure button on a node panel → Geolocation view, putting your license key in the "Your license key" field and clicking the Download button. After clicking this button, the download will start. The download progress will be shown in the Status field. Once the download has completed successfully, a green validation message will be shown here.
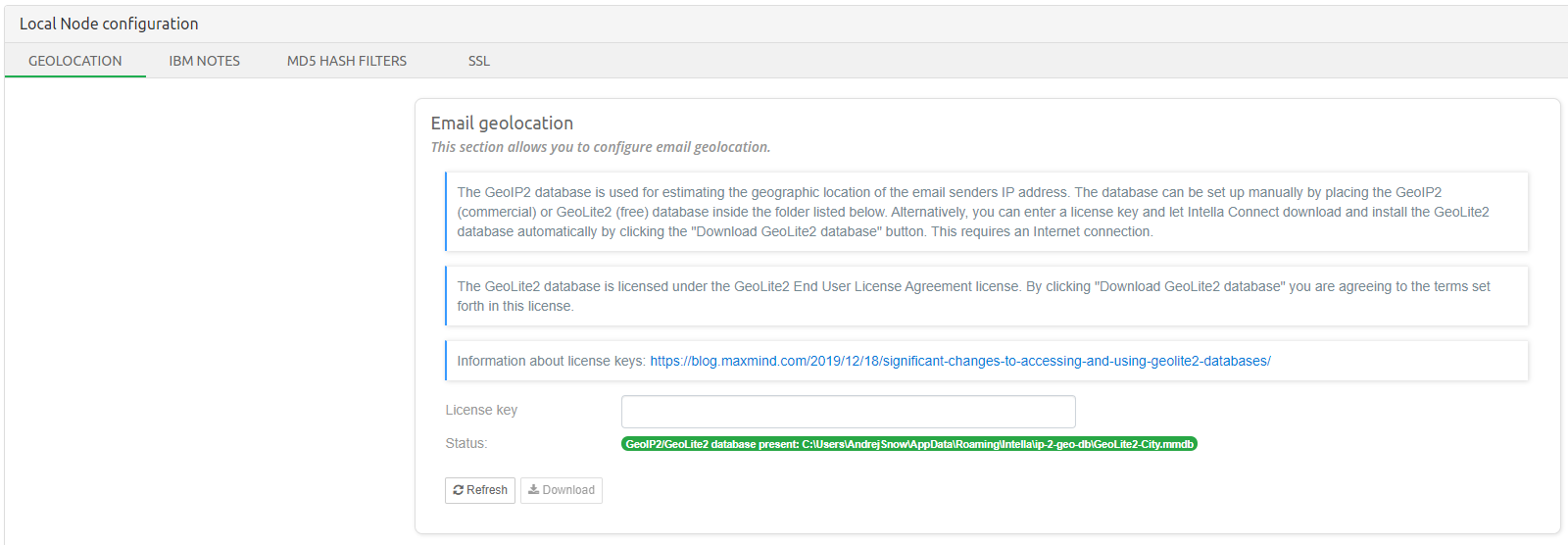
|
To use the Email geolocation feature, check the Determine the geographic location of an email sender’s IP address option when adding a new source. Presence of GeoIP2 or GeoLite2 database is required on Intella Node. |
14. IBM Notes
To index NSF files, IBM Notes 8.5 or higher is required. Only the application files are necessary, IBM Notes does not have to be fully set up and configured. In principle, all IBM Notes 8.5.x versions or later can be used, but the following versions will produce a warning:
-
8.5.3 FP 3
-
8.5.3 FP 4
-
8.5.3 FP 5
-
9.0
These versions contain a bug described here that cause emails with multiple “Received” headers to be altered: all Received headers will get the value of the first header. At the time of writing IBM Notes 9.0.1 was available, in which this bug has been fixed.
To index files made with IBM Notes 9.x, we recommend installing IBM Notes 9.x.
|
Intella Connect needs to know the location of IBM Notes to validate ID files in keystore. To set IBM Notes path in Intella Connect go to Settings > IBM Notes to check if the location is validated. |
|
Intella Node needs to know the location of IBM Notes to index NSF files. To set IBM Notes path in Intella Node go to Servers > Nodes > Node configuration > IBM Notes to check if the location is validated. |
Click Validate button to ensure that Intella Connect or Intella Node can locate the IBM Notes program files on the system. The status is shown above the Validate button.
If validation fails, adjust the path to the IBM Notes folder in the Path field and click Apply.
During Notes validation Intella Connect will check the Notes version. Versions listed above are not recommended, so to enable use of such non-recommended Notes versions, select the Enable using unsupported version of IBM Notes checkbox.
|
The default installation directories for IBM Notes is one of the following:
|
15. Branding
There are two branding products available for Intella Connect:
-
Intella Connect Co-branding
-
Intella Connect Branding
Based on the branding product available on your dongle, your company’s logo can be placed next to our proprietary logos (Intella Connect Co-branding) or it can replace all of them (Intella Connect Branding).
|
Branding will only be enabled when the Branding or Co-Branding product is present on your dongle. For inquiries please contact your sales rep or reseller. |
15.1. Setting up your company’s logo
When the Branding or Co-Branding product is present on your dongle, you will be presented with a Branding option on the Settings page.
15.1.1. Login page Logo
You can change the login page logo in this section.
|
The logo that is larger then 400px in height or width will be resized which might compromise its appearance. |
Just press Upload logo button and select the desired logo you want to be shown on the login page.
After selecting a logo a preview of the login screen should be updated accordingly.
15.1.2. Headers Logo
For changing header logos this section should be used.
To brand the Connect headers, you can upload your company’s logo image here.
|
The optimal size of the uploaded logo is up to 150 by 30 pixels. When you upload a larger logo, it will be resized, which might compromise its appearance. |
The absolute center of the logo image does not always represent the visual center of logo, but you will have the option to re-align it vertically.
16. Migrating Intella Connect
This section describes the steps required to migrate Intella Connect from one machine to another either for backup or hardware upgrade purposes.
|
Please leave Intella Connect and all cases intact on first machine until you are ensured that all cases on second machine are shared properly and that migration was successful. |
In order to move the cases to second machine please follow these steps:
-
Install Intella TEAM/PRO and Intella Connect on second machine.
-
Un-share cases you want to move on the first machine - this step is required as changes made to case files during the copying of the case could result in damaged copy.
-
Copy all cases and original evidence files to second machine.
-
Open Intella Case Manager on second machine and add each of the newly copied cases by pressing 'Add…' → 'Add an existing case'.
-
Open each of the cases with Intella TEAM/PRO and check out that Evidence paths are set-up properly. You can do this by going to 'Sources' → 'Edit evidence paths'.
-
(optional) If you want to move configuration settings, these folders also have to be moved (Important: please backup original files first):
-
Intella Connect Home Folder:
C:\Users\[User]\AppData\Roaming\Intella Connect -
Intella Home Folder:
C:\Users\[User]\AppData\Roaming\Intella
-
-
Make Intella Connect run on desired port by appending ServerPort property in file
C:\Users\[USER]\AppData\Roaming\Intella Connect\user.prefs:ServerPort=8081
-
Configure proper machine host name & SSL if needed. It is recommended to follow the steps described in SSL setup guide section.
-
Start Intella Connect.
17. Upgrading to the latest version of Connect
This section describes how to upgrade to the latest version of Connect and keep all of the settings, and what to look out for when upgrading Connect to the latest version.
Why upgrade to the latest version:
It is always best to install and use the latest version of Intella Connect and Intella Node. As is with any software development, it is near impossible to test every scenario in which the software will be used, and what type of data is indexed with the tool. Although there is vigorous testing regime for Intella Connect and Intella Node, some customers find issues which they report back to support. These issues are generally fixed, and added to the next release. Therefore, using the latest version will give you all of the fixes from all previous versions.
Another good reason to upgrade is because the latest version has a number of new features that are not in previous versions. These features can make processing faster, can make analysis of the data easier, and can add better functionality to the tool.
Upgrading Connect:
There is no problem with installing the latest version of Intella Connect on the same server. Note that this will need to be installed next to the current version. E.g. as long as the new version is installed in a different folder, the existing version should not interfere with new version. In addition, there is no need to uninstall the previous version.
When installing a new version of Connect, we make sure that any configurations from the previous version are also migrated over. We often keep old configuration as backup as well, so your previous configurations are not lost.
Installing the latest version of Connect is quite straight forward, but you should be aware of these aspects:
-
Make sure that you are always using the same Windows Account when installing different versions of Intella Connect. The configuration and settings for your current version are stored in user-sensitive location, and those locations will not be available to other user accounts. E.g., we have seen cases when users were installing version 2.0 with the "John" user account, then later installed version 2.1 with the "Administrator" user account. They were surprised to see that they ended up with a clean instance of Connect, with all default configurations and settings.
-
You need to be careful when installing Connect as a Windows Service. There is only ONE Intella Connect Windows Service allowed on the system. Installing a newer version of Connect as a service should overwrite the paths to executables in Windows Services. Once the install process is complete, and the service is restarted, there should be no issues. However, we have seen a number of cases when this did not work as it should have. The outcome is that the service was still pointing to the old version of Connect. In those situations, you should refer to subsection "Manual un-installation Intella Connect Windows service" of Connect as Windows service on how to manually update the service:
-
It is always best to run the latest version of all of our tools. This also applies to Intella Node. Having both Connect and Node on the same version will help when troubleshooting any issues. The risk of any incompatibility issues between Connect and Node are reduced when both products are on the same version.
|
From version 2.3.1 we will have an extra check during the installation process that will prevent the installation process from continuing if you have not shutdown the service manually. |
Before you start the upgrade:
You should consider the following before you start the Connect upgrade process:
-
With every release of Intella and Connect we provide Release Notes. The very last section of the release notes is the 'Upgrade Notes' section. In that section we list information regarding backwards compatibility with earlier case versions. This section also points out any features which may be limited due to the version upgrade etc.
-
We always suggest backing up your Connect/Node systems before undertaking any upgrades. This minimises the risk of downtime, as you have an avenue to go back should you have any issues with the upgrade process.
-
You should make a backup of these folders (which contain entire configurations) prior to proceeding with the upgrade.
C:/Users/CONNECT_USER/AppData/Roaming/IntellaandC:/Users/CONNECT_USER/AppData/Roaming/Intella Connect
After the upgrade is complete:
Once the upgrade process is complete, start Connect and check that Connect is reporting the correct version. You can do this by clicking on the Admin tab and selecting the 'About Intella Connect' option from the dropdown list.
If the latest version is not running, there may be old version of Connect still running.
Migrating keystores and self-signed SSL certificates:
Once the new version of Connect is running, you may need to reconfigure some advanced setting like SSL. This should be straight forward if you have purchased your SSL certificate from a well known provider like Go Daddy etc. That said, we do see a number of issues with SSL certificates coming through support. But, these issues are mostly related to when the user/company manages their own certificates. In these cases the users report that the upgrade went well, but they cant get SSL to work. In the SSL wizard they get errors like this:
"Unable to activate the keystore because it’s not valid. Details: Keystore contains multiple certificates, but they were not imported to the private key chain".
The issue is that unlike self managed certificates, certificates from a well known providers are generally added to Java’s trusted keystore. That means that certificates from a well known provider will work 'out of the box' when setting up SSL in Connect or Node.
When users/companies create their own self-signed certificates, they usually create two Certification Authorities (ROOT & Intermediate), and then let the Intermediate CA issue the certificates. But, Java doesn’t know anything about ROOT & Intermediate certificates for that company, and these certificates are not automatically trusted. Therefore, the self-signed certificates do not work when a new version of Connect or Node are installed.
Note: When you are upgrading Connect or Node, the existing (trusted) Java store is wiped out, and replaced with a clean one. For our products (Connect & Node) to trust the self-signed certificates, you have to add the certificates to the trusted CA store of the JAVA RUNTIME that we shipped with the installer used for the upgrade. This process is described subsection "advanced using self signed certificates" of SSL Guide .
So in short, if you are generating your own SSL self-signed certificates, then you will need to update Java’s trusted CA store (for both, the Connect and Node systems) after each upgrade.
Migrating fonts:
When upgrading Intella Connect, then the fonts copied to Intella Connect "Font" folder will need to be copied to the upgraded version.
For more information, see section How can I print and export PDF reports with characters of my language .
18. Remote indexing example using Intella Connect and Intella Node
This example of using Intella Connect and Intella Nodes to index evidence and share the resulting case assumes a setup of local network with two computers. Note that this example uses IP address to address a computer, however, domain or computer names can be used as long as it is a valid UNC (Universal Naming Convention) path.
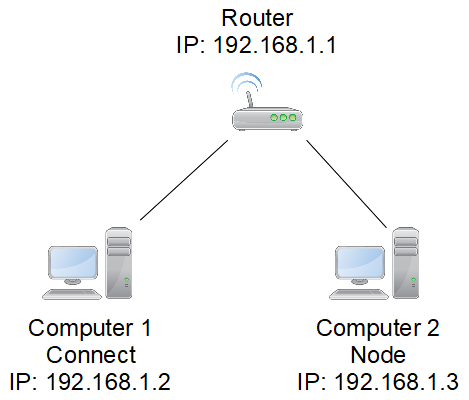
Install Intella Connect on computer 1 with IP address 192.168.1.2 on port 9999. Please refer to Getting started section for more information on how to install Intella Connect.
Install Intella Node on computer 2 with IP address 192.168.1.3 on port 9999. Please refer to Getting started section for more information on how to install Intella Node.
Add Intella Node to Intella Connect admin dashboard→Servers→Nodes by clicking on "Add Intella Node" button where Name will be "myFirstNode", Host will be "192.168.1.3" and Port will be "9999".
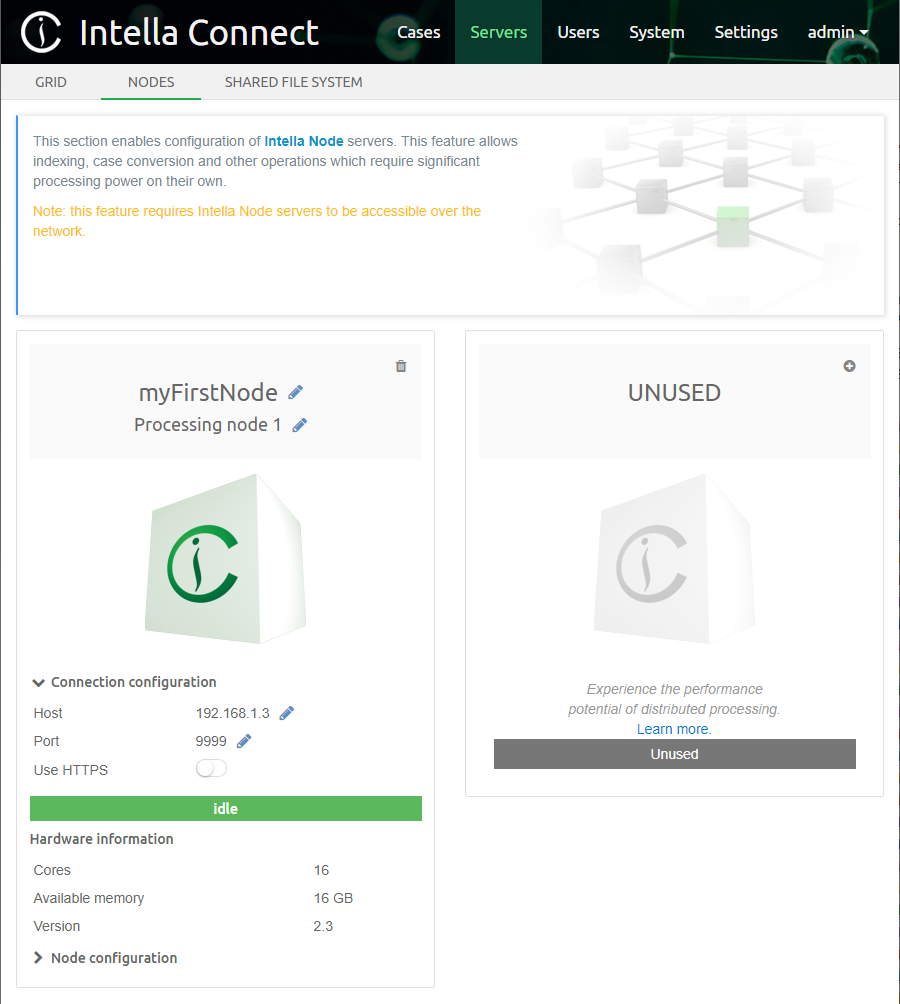
Share a folder called "cases" on computer 2 under UNC
\\192.168.1.3\cases. Use Windows folder sharing facilities to achieve
this.
Add shared folder to Connect admin dashboard→Servers→Shared file
system by clicking on "Add shared folder" button where UNC Path will be
\\192.168.1.3\cases
Having folder "Enron" inside folder "evidence", share the folder called
"evidence" on computer 2 under UNC \\192.168.1.3\evidence. Use Windows
folder sharing facilities to achieve this.
Add shared folder to Connect admin dashboard→Servers→Shared file
system by clicking on "Add shared folder" button where UNC Path will be
\\192.168.1.3\evidence
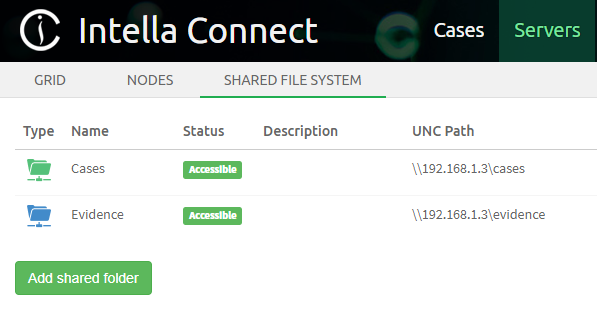
Create case by clicking on "Create case" button in Intella Connect
dashboard→Cases, fill out Case name as "Enron" and as Case folder
choose "Cases" folder shown within Shared folders in folders tree view.
This will automatically fill out Case folder with
\\192.168.1.3\cases\Enron.
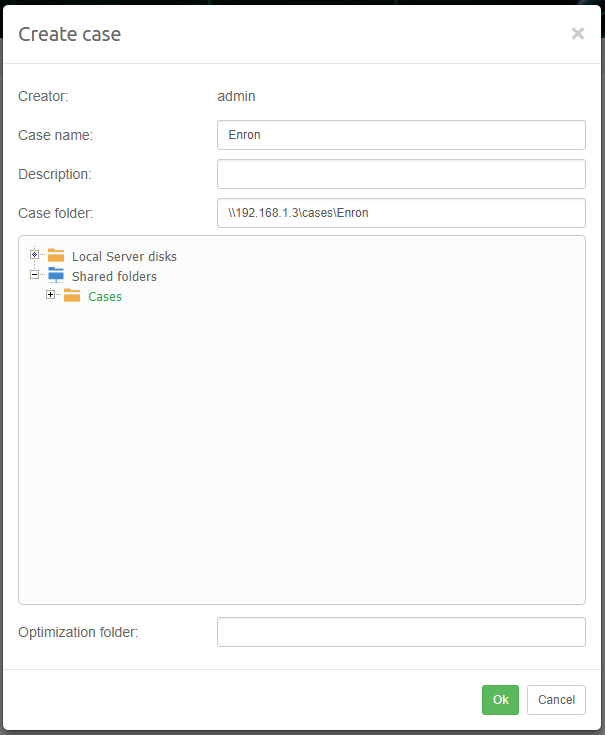
Add new source. Choose file or folder source type. Choose Shared folders→evidence→Enron from folders tree view as source folder.
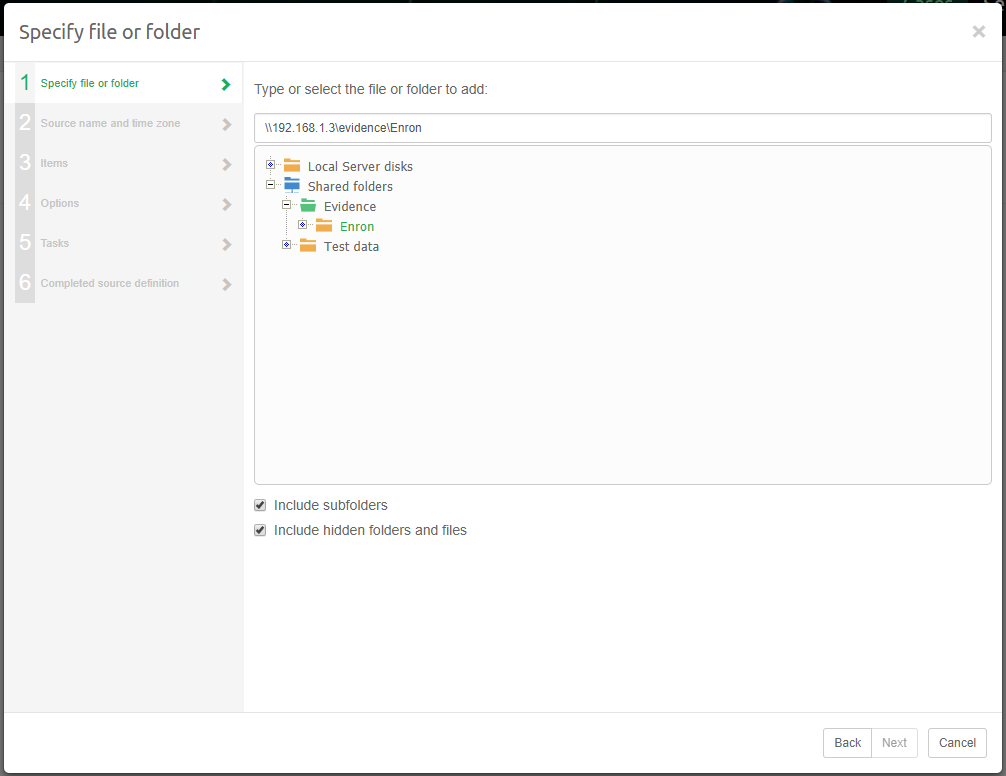
Continue source definition until last sheet. Select checkbox "Yes, I want to index this source now (recommended)" and choose "myFirstNode" as Intella Node to use.
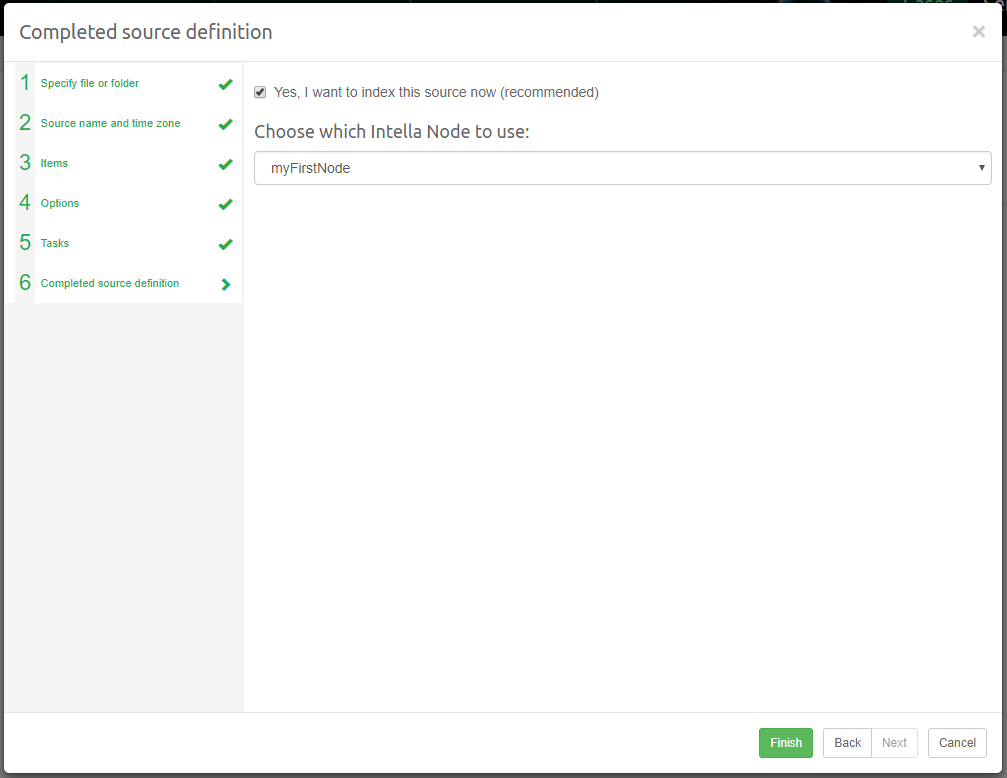
After indexing finishes, the case can be shared from it’s current location. Connection to computer 2 cannot be lost during sharing of that case as that’s where the case resides.
Sharing a case over the network could cause various issues resulting from network malfunction. Exporting will also take longer over network as compared to exporting from case on local disk. In order to share this case directly from local disks of Intella Connect, the case folder needs to be moved from it’s location on Intella Node’s local disk to Intella Connect’s local disk. The case then needs to be deleted from Intella Connect admin dashboard→cases list without checking "Also remove the related case folders from disk", so that the reference to this case is removed without deleting the actual case files. The case then needs to be added using "Add case" button and selecting the case folder from Intella Connect’s local disk within folders tree view.
19. Appendices
19.1. Appendix A - setting up SSL keystore using keytool
19.1.1. Preface
Intella Connect will accept any valid Java Keystore generated with either:
-
Intella Connect itself (like described in SSL Guide )
-
keytool command line utility bundled with any Java Runtime Environment
-
third party utilities (like Keytool Explorer)
This appendix describes how to create a new keystore using the keytool utility.
19.1.2. Prerequisites
Before you start generation of a keystore, there are few things you need to accomplish first:
-
Locate the keytool command line utility. This utility is bundled with each Java Runtime Environment installation. Since Intella Connect bundles its own version of JRE, you can use the keytool which is a part of it. This utility is located in Intella Connect installation directory, under
INTELLA_INSTALLATION_DIR/jre/bin/keytool.exe. -
If you are creating a keystore for a new certificate, decide which domain you wish to use. Once certificate is assigned to it, it cannot be changed.
-
If you are creating a keystore for an existing certificate, make sure that you are in possession of a Private Key which was used to generate it. This guide assumes that you have your Private Key along with matching X509 certificate in a "p12" extension (PKCS#12) keystore format.
19.1.3. Creating a keystore with Private and Public Key pair
These steps depend on whether you already have a working SSL certificate, so please follow the steps most suitable for your situation.
|
For purposes of this tutorial we will be using an artificial address/domain pair: 1.2.3.4, www.my-site.com |
I’m already in possession of a Private Key and X509 certificate issued for my company/domain
-
Make sure that you have a valid keystore with "p12" extension containing Private and Public Key pair. You should have no problem in obtaining it from the company which signed your certificate.
-
Import keystore (example:
my-keystore.p12) into a new Java keystore:keytool -alias my-site -importkeystore -srckeystore my-keystore.p12 -srcstoretype PKCS12 -destkeystore my-site.com.keystore -
At this point you will have a new Java keystore containing your Private and Public Key pair.
-
The next step depends on whether or not the Public Key in
my-keystore.p12was already signed (contained proper certification chain):-
If Public Key contained trusted certification chain, then you are all set and you have a valid Java keystore.
-
If Public Key did not contain trusted certification chain, then you still need to import your X509 certificate along with all intermediate certificates given to you by your CA. You can proceed to Adding certificates to the Keystore.
-
I do not have a SSL certificate or I want to buy a new one
-
Decide upon the Case URL scheme that you would like to use for case sharing in Intella Connect. Your options are:
-
A domain (recommended) – domain names are easier to remember and do not change that often. If your domain is already taken, you can easily choose something unique, yet easy to remember, like: www.my-connect-cases.com
-
A public IP address.
-
-
Using the keytool utility, create a new keystore in the location of your preference
keytool -genkey -alias my-site -keyalg RSA -keysize 2048 -keystore my-site.com.keystore -
You will be asked to enter some values. Please use your best judgment to fill in the necessary fields. Listed below are the ones that are important for Intella Connect:
-
Keystore password - use a strong password, we will be using it later in the Settings panel.
-
First and last name (also referred as CN – Common Name) - please provide the address to which the certificate was issued (remember: that was either a public IP or domain).
-
Key password - this password should be different from the keystore password. It offers additional protection over the Private Key. Use an equally strong password.
-
-
After this step you should have a new keystore ready with an unsigned certificate.
19.1.4. Requesting certificate signature
|
This and the following steps apply only if you created new Private and Public Key pair in the previous step. |
Since now you are in possession of an unsigned certificate, you need to ask a Certification Authority (CA) to sign it. CAs accept only requests for so called Certificate Signing Request, so you need to create one using the keytool.
On the command line, please enter the following command:
keytool -certreq -keyalg RSA -file my-site.com.csr -keystore my-site.com.keystore
You will be asked for the master password for the keystore, which you
have defined in the first step. This should produce a file called
my-site.com.csr
19.1.5. Signing your certificate with CA
You now have to supply this signature request to the Certification Authority. This process is specific to the authority signing the certificate. After the CA is done with processing your request, you usually receive a set of files:
-
your new SSL certificate (this is your own Public Key signed by some Certification Authority)
-
set of trusted certificates (usually two or more, those also play a role in the signing process and should be imported to your keystore)
19.1.6. Adding certificates to the Keystore
You now have to add each certificate that you have received from your CA
back to the keystore. Most likely you have received three files: the
CA’s certificate, an intermediate certificate and the one which applies
to your domain (IP). Please use keytool.exe again to add them using
the commands below. Please keep in mind, that for this tutorial our CA
has supplied us with three files (AddTrustExternalCARoot.crt,
PositiveSSLCA2.crt and www_my-site_com.crt) which are stored in the
signed subdirectory:
keytool -import -trustcacerts -alias AddTrustExternalCARoot -file signed\AddTrustExternalCARoot.crt -keystore my-site.com.keystore
keytool -import -trustcacerts -alias PositiveSSLCA2 -file signed\PositiveSSLCA2.crt -keystore my-site.com.keystore
keytool -import -trustcacerts -alias my-site -file signed\www_my-site_com.crt -keystore my-site.com.keystore
|
Note the usage of 'alias' parameter. Two first commands listed above created new entries in our keystore, while the last one has updated the my-site entry which contained our Private and Public Key pair. |
19.1.7. Conclusion
This simple guide shows steps necessary to create a valid Java Keystore using the keytool utility. For more information, please refer to: https://docs.oracle.com/javase/6/docs/technotes/tools/solaris/keytool.html
19.2. Appendix B - setting up SSL from an existing certificate
19.2.1. Preface
Very often you might wish to set up HTTPS protocol for an existing certificate that has already been issued to your company and is already used in production. In cases like these it’s handy to import it to a keystore (which is required by Intella Connect), rather than paying for and maintaining a second certificate.
This step-by-step example shows how to set up a fully functional keystore for an existing GoDaddy™ certificate. It uses a third party application Keystore Explorer which offers a simple an intuitive user interface to do most of the work.
|
Vound is not associated with neither GoDaddy™ nor developers of Keystore Explorer and we wish not to promote either of them. This guide serves explanatory purposes and should be treated as a learning material only. As for Keystore Explorer, Vound cannot be held accountable for any misuse or damage that might be a result of using it. If you feel uncertain if you should use it, please consult your IT specialists or keep on relying on keytool. |
19.2.2. Prerequisites
Before attempting to create a keystore to be used in Intella Connect one must realize that there are many industry standards governing the process of producing a valid SSL certificate. Therefore it’s common to encounter different types of keystores, keys and certificate formats. Not all of them work interchangeably and explaining all the differences between them is beyond the scope of this article.
It’s also vital to understand that certificates are created based on a pair of keys: public and private. It should be obvious for any engineer generating the SSL certificates what role those keys play in the encryption process and this will not be explained here. If you are reading this document but you don’t have any keys generated yet, it’s best if you follow this guide to quickly get on the right track. If you do, however, own a certificate already then those keys had to be generated beforehand and the remaining of this document will help you to use them properly to import your certificate into a new keystore.
There is only one prerequisite for you to follow at this point, and that is:
You must obtain a copy of your private & public keys pair in PKCS#12 format stored as a single *.p12 file.
If you own a certificate but don’t have keys (and .p12 file), you might still want to read the rest of this document for educational purposes, however, without them you will not successfully generate a keystore. Keep in mind thought that GoDaddy™ offers you to recreate keys if you lost them for the certificate that you bought. That being said, Vound will not assist you in this process as it’s beyond what we could support.
The rest of this document heavily relies on screenshots that ought to be self-explanatory. If they are not, some textual context is also provided.
For the entire process illustrated below we have been using a freeware application called Keystore Explorer, which is available for download here: http://www.keystore-explorer.org
19.2.3. Obtaining your *.p12 file
Create a new empty folder for you to work with. Then create a subfolder called "prerequisites" and place there the *.p12 file which contains your private and public keys which were used to generate the CSR (Certificate Signing Request) and as a result your SSL Certificate.
19.2.4. Downloading your certificate
Go to https://godaddy.com and log in to your account. Then navigate to the page with details of the certificate that you wish to install.
Then go to the download page and select Tomcat as the type of your server.

Press "Download Zip File" and save the file as "tomcat.zip" into "prerequisites" folder.
Next unzip the "tomcat.zip". There will be few files there, most of which you don’t need. In our case those were:
-
6f69fc017c23c853.crt // This is the certificate issued for our domain. You will need only this one to continue, however the name will probably be different in your case.
-
gd_bundle-g2-g1.crt
-
gdig2.crt
Remove unnecessary files (keeping only certificate issued for your domain) and proceed to next step.
19.2.5. Exporting intermediate and root certificates
Right now you should only have two files in your "prerequisites" folder. Double click on your certificate file and that should open standard Windows' tool for analyzing certificates (sometimes referred as Crypto Shell Extension). This is basically a viewer which you can use to examine certificates.
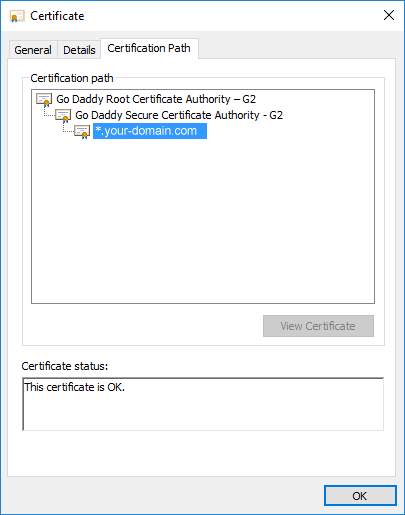
Select the top-most certificate (Root) and double click it. That should open another viewer.
Navigate to "Details" tab and press "Copy to file" to start exporting of the certificate. Next you will see a wizard which should guide you through the process of exporting the certificate. Just follow it all the way through using default settings. Save the output in the "prerequisites" folder as "root-cert.cer".
Repeat the same process for the certificate which was shown in the middle when you examined your own certificate. This one is sometimes called "intermediate certificate" so save it as "intermediate-cert.cer".
Files listed above are essential for the rest of the process so make sure you did all the steps right until this point.
19.2.6. Creating a new keystore
Launch Keystore Explorer and create a new keystore of JKS format.
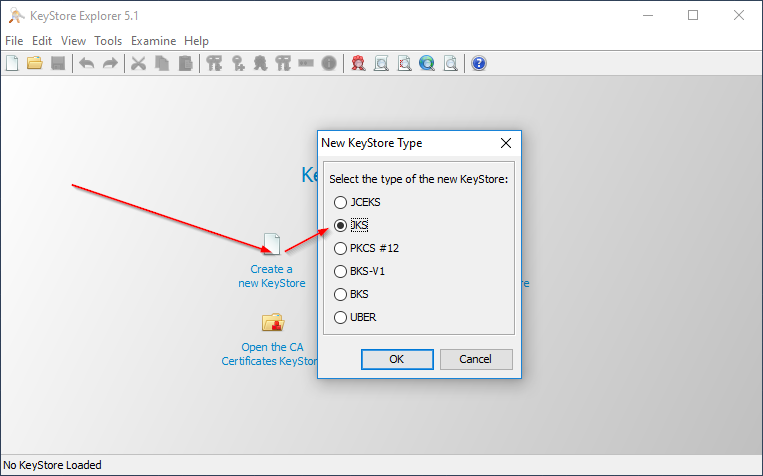
The next step is critical and it shows why having a pair of keys is essential for the whole process. You must import them first as they are the main entity used during the cryptology process.
To do that select "Tools" from main menu then "Import Key Pair". You should then select the proper format, in our case PKCS#12 as this corresponds to *.p12 file. Then provide the password which governs access to keys in *.p12 file and select the right path. This is illustrated below:
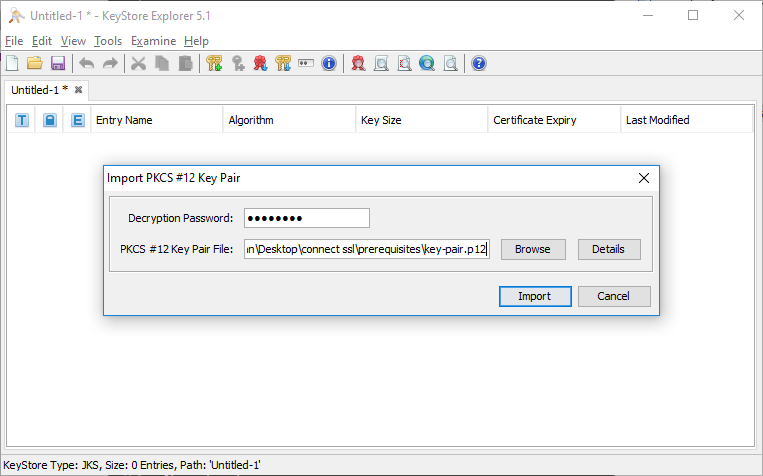
Afterwards the UI will ask you for an alias. This is just a simple name to be used inside the Keystore. You can use whatever you want, but for clarity use "connect" as we did in our example.
Next, you must specify passwords for these keys inside your keystore. Once again use whatever you want but keep track of this password.
You should see a final message saying that this process has been successfully completed.
Next step is to put the intermediate and root certificates into your keystore. Once again go to "Tools" and this time select "Import Trusted Certificate". Start with importing the "root-cert.cer" first. Keystore Explorer will ask you if you trust this certificate and you want to add it. Proceed with default options (keeping the alias the same as it was) until you reach to the end and see another successful message.
Next repeat the last process for "intermediate-cert.cer". Proceed as before until you see another successful message. At this point you should have those three entities in your keystore.
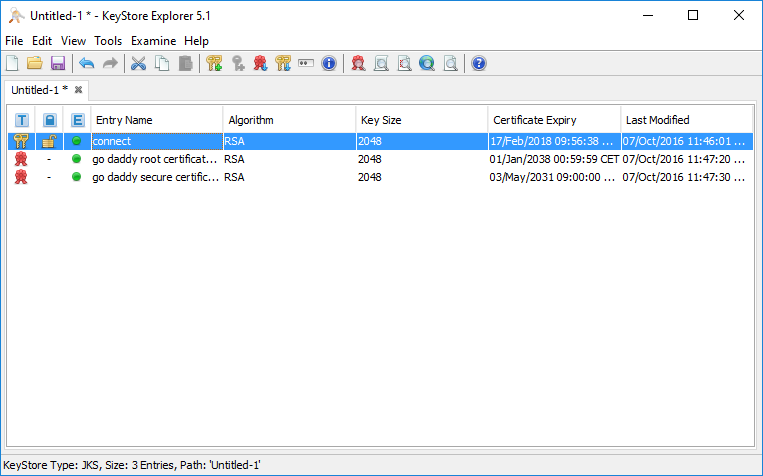
Now you can now double click on "connect" entity. This opens up a detailed view which will show you a proper certification path when we complete all steps. Right now it’s important to note that you can only see one entry in the "Certificate Hierarchy" panel, which is illustrated on the screenshot below.
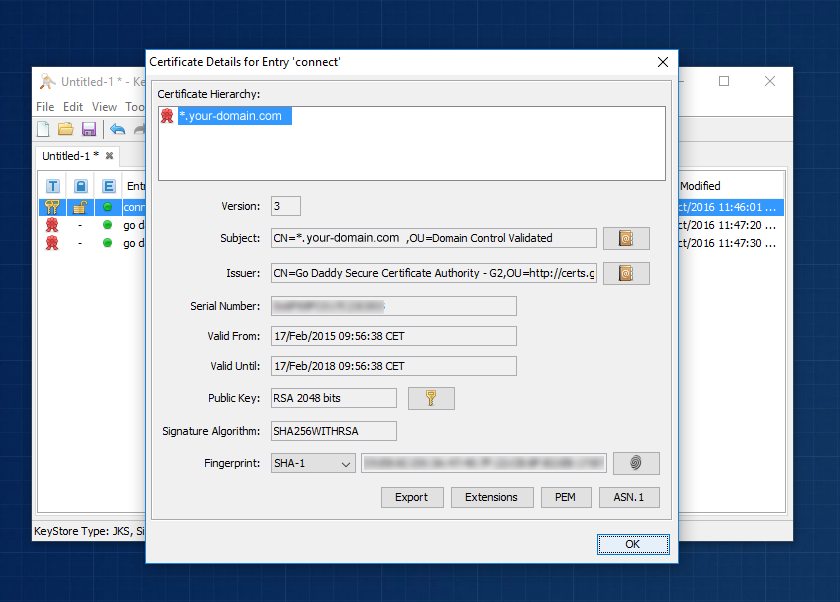
19.2.7. Import GoDaddy™ certificate to your keystore
At this point we are ready to import the signed certificate from your provider. Close the details view and right click on the "connect" entity with your mouse. That should open up a contextual menu which has few common options available. Please note the "Import CA reply" option. What this option does is it allows getting an existing certificate signed with GoDaddy™ and using this information to alter the certification chain for an entity selected in your keystore. Use this option and select the main certificate that you downloaded before (in our case that was 6f69fc017c23c853.crt). This should be a quick process finishing with another success message.

Now double click on "connect" entity again to see if certification hierarchy has changed. You should see all three certificates in chain (root → intermediate → your domain).

19.2.8. Save your work and configure Intella Connect
You should now save your work from the "File" menu in Keystore Explorer. Keystore Explorer will ask you to provide passwords governing the entire keystore. This creates single file (in our case "connect.keystore") which will then have to be provided in Intella Connect Admin Dashboard (along with passwords to the keystore and private keys too). This is explained in more details in SSL Guide .