14. Exporting¶
Intella Connect supports a number of exporting formats, each focusing on a different use case.
14.1. Downloading original item¶
If the item has been OCRed, decrypted or has a load file image associated with it, an additional dialog may be shown when downloading that item in Details panel, Previewer or Coding panel. It will allow to select which content needs to be downloaded.
14.2. Exporting a list of results¶
To export a collection of items that have been returned by a query, you can use the following procedure:
- In the Details panel, use Ctrl-click or Shift-click to select multiple items.
- Alternatively, use the checkbox in the first column of the Details table header to select all items in the table.
- Right-click and in the context menu choose “Create new export”.
- Alternatively, click on the “Create Export” button in the Details table header.
This opens the Export Wizard. This wizard lets you choose the export format and its settings and start the export process.
Important
Access to the original evidence files is only necessary when you want to export the original evidence files themselves and the “Cache original evidence files” option was disabled when the source was added. If access to the original evidence files is not available, then a warning message is shown in the Export Wizard when choosing export format. To change the evidence paths, see section Administrator’s manual > Sources > Editing Sources.
After pressing the Start Export button in the last step, a new export package will be created. You can manage export
packages through the Export view.
Administrator’s note
We strongly recommend that you do not use any MS Office applications on the server machine during exporting. Using these applications at the same time can result in these applications exiting suddenly and without warning, risking data loss on any opened documents.
Important
When exporting a single result or a list of results, the maximum length of the file name is 120 characters on any operating system different from Windows 10. There is no limitation on the file name length when using Windows 10.
Important
Every export in Intella Connect is done by exporting selected items to a temporary directory first and then compressing it into a ZIP archive. Please refrain from previewing temporary files on file system, as this can intervene with creation of the archive.
14.2.1. Export formats¶
The first wizard page lets you choose an export format:
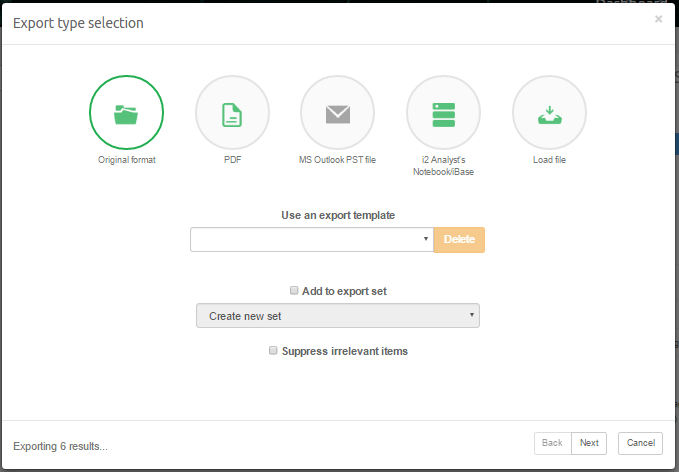
- Original format exports a file into its original format, i.e. a Word document attached to an email is saved as a Word file. All emails from mail sources (e.g. a PST or NSF file) are exported as EML files. Emails that are already in EML, EMLX or MSG format are exported as such. All contact items from PST/OST files are exported as vCard (.vcf) files. All calendar items from PST sources are exported as iCalendar (.ics or .ical) files. The exported files can be opened with the program that your system has associated with the file extension used.
- PDF converts every item into a PDF document, containing the content of the original item and a configurable set of properties.
- PST lets you export items to a MS Outlook PST file. The main purpose of this option is to use the PST file as a carrier for transport of emails, but other item types are supported as well. The receiver can open the PST file in Microsoft Outlook or process it in another forensic application. A server-side installation of MS Office 2016, MS Office 2013, MS Office 2010, or a MS Office 2007 is required in order to be able to export to PST.
- i2 Analyst’s Notebook/iBase exports the results in a format that can easily be digested with i2’s Analyst’s Notebook and iBase applications. All metadata of all items, all attachments and all email bodies can be imported into these tools, allowing rapid social network analysis and all other analytical abilities of these applications on email and cellphone evidence data.
- Load file will export the items in a format that can be imported into Summation, Concordance, Ringtail and Relativity.
Only one format can be chosen per export run.
14.2.2. Export templates¶
The current configuration can be stored as a user-named template in the last wizard sheet. In the first sheet all stored templates are listed in a drop-down list. Selecting one restores the state of the Export wizard to the one stored in the selected template.
Note
All templates, even those created by Intella 100, Intella 250, Intella Professional (Pro) or Intella TEAM Manager are automatically available across all cases on the same machine and user account.
Administrator’s note
Export templates are stored in the following folder:
Windows Vista, Windows 7 and Windows 8:
C:\Users\<USERNAME>\AppData\Roaming\Vound\Intella\exporttemplates
Windows 2000, XP:
C:\Documents and Settings\<USERNAME>\Application Data\Intella\export-templates
14.2.3. Suppressing irrelevant items¶
You can use the “Suppress irrelevant items” checkbox to automatically exclude all items from the export that have been classified as “Irrelevant” during indexing. See the Features facet section for a definition of irrelevant items. The number of irrelevant items in the current item set will be shown in parentheses.
14.2.4. Export sets¶
When a set of items is exported, they can optionally be added to an export set. This is a named set that captures information about the export. When a specific item is about to be exported, the file name and number is recorded in the export set. Furthermore the current export settings are stored as part of a set. When the export set is later selected again when exporting another set of items, this will affect that export run in the following ways:
- All export settings such as the chosen export format, file naming and numbering schemes, etc. will all be the same as in the first export run. On other words, the export set works similar to an export template.
- File numbering continues where it left off, rather than starting at 00000001 again.
- Items that have been exported before with this export set selected will get the same name and number as the previous time(s) they were exported.
When an export set is specified, the resulting export ID (typically based on subject, file name and/or consecutive number) can be made visible in the Details column by adding desired Export set column. The Export IDs can also be searched for using keyword search and keyword list search.
14.2.5. Preferred content type options¶
The options in this sheet allow to select the preferred content type for the original format items. Intella will export the first available content in the order specified in the table. The following content types are available:
- Original. Original content of the item.
- Decrypted. Decrypted content is available for the items that have been decrypted during the indexing.
- OCRed. OCRed version of the original document. Note that this content type is not available for items where the OCRed content was imported as plain text.
- Load file image. Image associated with the item imported from a load file. Note that the load file image is always exported in PDF format.
14.2.6. PDF file options¶
The first wizard sheet on PDF options lets you decide whether to export to individual PDF files, one for every selected item, or to export all items into one single concatenated PDF file. When exporting to a concatenated PDF, the resulting PDF can optionally be split in chunks of a given size. This is recommended for performance and stability reasons.
14.2.7. File naming and numbering (original format, PDF, load files)¶
This wizard sheet consists of three sections:
- File naming defines how to compose an exported file name (original format, PDF) or page (load file export).
- File numbering defines how exported files are numbered.
- File grouping defines how exported files are grouped into folders.
File naming
By default, exported files will be named using the original evidence file’s name or the subject of an email. Alternatively, you can choose to number the files using consecutive numbers. These options can also be combined: a number followed by the file name or subject.
Load file naming offers more elaborate numbering style, whose parts can be further configured in the File Numbering section.
When using a numbering style, you can also define a prefix. Anything you type here will be added to the beginning of the filename. E.g. the prefix “export-” will result in the first email being named export-00000001.eml, when you combine it with consecutive numbering.
Using “Advanced” mode you can define a file name template that will be a base for exported file name. The template may include the following fields:
- %num% – A counter value will be added. You can also define a number of leading zeroes in the counter using the following format: %000num%. The number of zeroes defines the number of digits used in the counter. The default number format for the counter is to use 8 digits.
- %group1%, %group2% – Group counters used with load file export only. See the “Export as a load file” section for details.
- Any Intella column identifier surrounded by the ‘%’ symbol, like %md5%.
- %Best_Title% – One of the following fields: File name, Subject, Title, Contact Name or “Untitled”
In order to insert any field in the template you can either type it manually or select the field from the drop-down list and press Add field.
File numbering
Using the “Start at” option you can define the number to start counting with. By default exporting will start counting at 1. A typical reason to use a different start number is when you want to combine the exported results with another set of already exported files.
Numbers are always 8 digits long.
“Folder”, “Page rollover” and “Box” are only relevant when using load file naming.
When exporting to PDF the “Number pages” option can be used to number individual pages instead of files. So the numbering would work the same way as when exporting to a load file.
File grouping
Select the option “All in one folder” to put all exported files in one folder.
Select the option “Keep location structure” to preserve the original folder structure that the items have in the evidence files. A folder will be created for every source, in which the original folder structure of that source (as shown in the Location facet) will be recreated.
File name examples
On the right side you can see a live preview of how the exported file names would look based on the current settings, using items from your current item set as examples.
14.2.8. PDF rendering options (PDF, load files)¶
Note
When exporting a load file, this sheet is called “PDF or image rendering options”.
The options in this sheet only apply to non-redacted items; the exporting of redacted items is governed by the “Redacted items” sheet.
For all types of items, you can indicate whether to include a basic item header, properties, raw data and comments in the PDF:
- The item header is shown at the top, above a black line, and shows the email subject or file name.
- The properties include typical metadata attributes such as titles, authors, all dates, hashes, sizes, etc. By default all properties are included, but you can remove some of them in the “Select properties…” dialog.
- The raw data varies between item types. For example, for PSTs the low-level information obtained from the PST is listed here and for vCards the actual content of the file is listed. This field may reveal properties that Intella Connect does not recognize and are therefore not to be found in the Properties section.
- The comments refer to the ones made by Intella Connect user(s) in the Comments tab in the Previewer. They are not to be confused with comments that can be made in, for example, a Word document. These are part of the Properties section. Note that the reviewer comments may include sensitive information such as evidence file names, investigator insights, etc.
Furthermore, the item’s content can be exported in its original format, as the extracted text, or both. The following file formats can be exported in their original view:
- Emails with a HTML body.
- MS Office (doc, docx, xls, xlsx, ppt, pptx)
- Open Office (Writer, Calc, Impress)
- WordPerfect
- RTF
- HTML
When you select “Original view”, you will also be able to define a list of item types that should be skipped for this. You can use this to e.g. prevent native view generation of spreadsheets, which often are hard to read in PDF form. An optional placeholder text can be added to make clear that original view generation has been skipped on purposes for this item.
Select the “Append file type to placeholder text” option to add the type of a skipped file to the end of the placeholder text, so it would look like: “Document rendering skipped (Microsoft Excel 97-2003 Workbook)”.
When you also select the “Export skipped item as native file” option during load file export, the resulting load file will not contain the corresponding native file. By selecting “Also skip extracting text” you can skip generating the extracted text as well. This includes extracted text added to the resulting PDF and extracted text exported as a separate file as part of a load file.
The Configure ‘Original view’ button allows to configure which content type needs to be included in the Original view of the item. See the section Preferred content type options for more details about which content types are available.
If you uncheck “Include item metadata”, the resulting PDF will not contain any additional information except for the actual item content (in its original format and/or as extracted text), the document title/subject and the headers and footers defined in the next sheet. Most of the options on this sheet will then be disabled.
For emails, the following information can optionally be included:
- The message body.
- A separate checkbox is provided that controls whether the HTML or plain text body is preferred. This option is only available when the “Content as” setting is set to a value that involves original view generation, i.e. anything other than “Extracted text”.
- The full email headers.
- A list of all attachments, as a separate page. The file name, type and size of each attachment will be listed.
- The actual contents of the attachments. The original view (described below) will always be selected by default, with the extracted text used as a fallback.
For loose files and attachments that are not emails, the following options are available:
- List all embedded items, e.g. images found in the document.
- The file body.
- The “OCRed text for images” checkbox controls whether to include the OCRed text when the file is an image.
- The “Imported text” checkbox controls whether to include text that was imported using importText option in Intella Command line interface.
It is possible not to include the lines that separate the headers and footers from the content by unchecking the “Draw header and footer line separators” checkbox. Section names such as “Image”, “Original view”, “Extracted text” etc. can also be excluded from the resulting PDF by unchecking “Include section names”.
14.2.9. PST options¶
Enter a file name to use for the generated PST.
Enter a display and folder name. After opening the exported PST file in MS Outlook you will see the names you entered. They help you to locate the PST file and its contents in MS Outlook. If the folder name is not specified the items will be exported directly to the PST root folder.
Select the option “Keep location structure” to preserve the original folder structure during the export.
The resulting file can optionally be split into chunks of a given size. This is highly recommended for larger result sets that would make the PST grow beyond the default suggested file size, as Outlook may become unstable with very large PST files. The produced files will have a file size that is close to the specified maximum file size (usually smaller). The export report will list for every item to which PST it was added.
Item types that can be exported directly to a PST file
Besides emails, the following item types can be exported directly to a PST file:
- Contacts
- Calendar items:
- Appointments
- Meetings
- Meeting requests
- Tasks
- Journal entries
- Notes
- Distribution lists
Limitations:
- iCal recurrence rules (RRULE property) are not exported.
- PST Distribution lists are exported, but their list members are not.
These limitations may be removed in a future Intella Connect release.
Please note that non-email items will be exported to a regular PST folder under the Mail section, so not in e.g. the Contact section.
How to export other item types to a PST file
Items such as Word and PDF documents cannot be exported directly to a PST file. As such items may be attached to an email, Intella can be configured to export the parent email instead.
You can choose to either include the top-level email parent or the direct email parent. An example would be an attachment contained within an email message within another email message. With the top-level parent selected all parent items of the attachment (both emails) would be included in the PST, one nested within the other. The second option exports the nested email to the PST. You can also choose to simply skip non-email attachments.
Although this option only mentions parent emails, it also applies to e.g. PDF files attached to a meeting request or any of the other exportable items. In this case, enabling this option will export the meeting request instead. This option may therefore be renamed in the future.
Note
Files in a folder source lack a parent email and therefore cannot be exported to a PST file, except for mail files like EML, EMLX and MSG files, or files of the types listed above.
How to export attached emails
The last setting controls what happens with emails that are selected for export and that also happen to be attachments. These are typically forwarded messages. Such emails can technically be exported to a PST without any restrictions, but the investigation policy may require that the parent email is exported instead, to completely preserve the context in which this email was found. That can be done by choosing the Replace with its top-level parent email option. Alternatively, use the Export attached email option to export the attached email directly to the PST.
14.2.10. iBase and Analyst’s Notebook options¶
At the moment the Analyst’s Notebook and iBase export does not provide any configuration options.
Templates, import specifications and instructions are provided for Analyst’s Notebook and iBase. Please contact support@vound-software.com for more information.
14.2.11. Load file options¶
You can select one of the following load file formats:
- Summation.
- Concordance.
- Relativity.
- Ringtail.
- Comma Separated Values file.
Each load file export consists of several parts:
- The main load file, containing the selected fields.
- Native files, representing the items in their original format.
- Image files, containing metadata and content as configured in the “PDF or image rendering options” sheet.
- Text files that contain the extracted text.
The first part is mandatory; the others can be turned off.
The main load file name can be changed using the “File name” text field. It is also possible to specify the main file encoding when the Summation format is selected.
By selecting “Use custom date/time formats” you can override the date and time format used in the load file. Please see this document for the date/time format syntax details: http://docs.oracle.com/javase/7/docs/api/java/text/SimpleDateFormat.html
The Size column can be optionally exported in kilobytes, megabytes or gigabytes instead of bytes by using the “Size unit” option.
In order to control the quality of the exported images, you can set the “Image DPI” parameter. It defines the number of dots (pixels) per inch. A higher DPI setting results in higher quality images, but these will take more time to produce and consume more disk space.
It is also possible to adjust the TIFF compression type. Note that the image will be converted into black-and-white variant if one of the “Group Fax Encoding” compression type is selected.
The option “Also include PDF version of images” can be used to additionally export PDF version of images if the image format is different from PDF. The PDFs will be exported to the folder specified in the Folder option.
The extracted text can be configured below “Include extracted text” checkbox by choosing which components to include and change their order.
When you need to embed the extracted text directly into the load file itself (the DII, DAT or CSV file) instead of exporting it into a separate file, you can use the checkbox “Embed extracted text into load file”. A custom field of type “EXTRACTED_TEXT” should be used to insert the text as a field in this case.
When exporting to Summation the checkbox “Include Summation control list file (.LST)” can be used to generate a plain text file that lists all document IDs along with the extracted text files. The “OCR Base” field controls the prefix used for the extracted text files.
The “Exclude content” option can be used to completely exclude the items tagged with a specified tag. For every excluded item, only the metadata will be added to the load file. The text and the images will contain the text specified in the “Placeholder text” field. Native files will also not be generated for such items.
Numbering with load files
The numbering used for load files differs from the other export formats. When exporting to a load file, every exported page has its own unique number. The number of the first page is usually used as a number of the document. Please note that pages are numbered only if image files are included in the export.
On the “Headers and footers” sheet you may choose a special field PAGE_NAME which is available only with load file export. This will put the current page name as it was configured on the “Naming and numbering” sheet.
Another difference is that by default all export files are grouped into folders and optionally boxes. The “Page rollover” option defines a maximum amount of pages that a folder can contain. The maximum number of folders in a box is fixed to 999. Additionally you can set a starting number for the page (“Start at”), folder and box.
By default, the page counter starts over when switching to the next folder, so the first page in the next folder will have the number “1”. This approach can be changed when using “Continue page numbers from previous folder” option. When it is selected, the page counter will continue page numbering from the last page of the previous folder. In other words, page numbers will be unique among the entire export set.
Additionally, the “Advanced” numbering mode can be selected when exporting to a load file. In this case you will be able to set a custom file name templ ate. Please see the file naming and numbering section for details. Note that %num% means a page number, not a document number in this case. Also there are two new fields that can be used:
- %group1% – folder counter
- %group2% – box counter
You can also use the %000group1% syntax to define the number of leading zeroes in the counter (similar to %000num% syntax). Thus, the default load file numbering schemes can be expressed using the following templates:
- PREFIX.%group2%.%group1%.%num% = Prefix, Box, Folder, Page
- PREFIX.%group1%.%num% = Prefix, Folder, Page
- %group2%.%group1%.%num% = Box, Folder, Page
When using the “Advanced” mode it is important to set a file grouping: “All in one folder” or “Load file mode”. When “Load file” grouping mode is selected then the exported files will be grouped by folders and, optionally, boxes in exactly the same way as it is described above.
Field chooser The “Field chooser” sheet contains a table of the fields that will be included in the load file. By default the starting set of fields depends on the selected load file format.
The “Name” and “Comment” columns in this table are used only for managing the fields within Intella Connect and are not included in the load file. The “Label” column value is used as a column label in the load file. The “Type” column can be one of the following:
- SUMMATION – It can be used only with Summation load file format and cannot be modified.
- RINGTAIL – It can be used only with Ringtail load file format and cannot be modified.
- CUSTOM – User-created field. It can be used with any load file format.
You can include an additional custom field by pressing the “Add custom field…” button. Next, enter the name, label and comment. Select one of the following types:
- FIXED_VALUE – Fixed value as specified in the “Value” field.
- INTELLA_COLUMN – One of the Intella columns.
- ITEM_BEST_TITLE – One of the following Intella columns: File name, Subject, Title, Contact name or “Untitled”.
- RECORD_ID_START – Name of the first page of the document.
- RECORD_ID_END – Name of the last page of the document.
- RECORD_ID_GROUP_BEGIN – Name of the first page of the first document in the current “parent-child” group.
- RECORD_ID_GROUP_END – Name of the last page of the last document in the current “parent-child” group.
- RECORD_ID_PARENT – Name of the first page of the parent document.
- NUMBER_OF_PAGES - number of pages of the document
- FILE_NATIVE - relative path of the original format of the document to the base folder.
- FILE_IMAGE - relative path of the first image of the document to the base folder.
- FILE_TEXT - relative path of the extracted text file of the document to the base folder.
- EXTRACTED_TEXT – extracted text directly embedded in the load file body. See the “Embed extracted text into load file” option described above.
- EMAIL_INTERNET_HEADERS - full Internet headers of the email.
- ATTACH_ID_LIST - The list of attachment IDs.
- IS_EMAIL - “True” if the document is email, “False” otherwise.
- FILE_EXTENSION - The file extension of the document.
- DIRECT_PARENT - ID of the document’s direct parent.
- DIRECT_CHILDREN_IDS - The list of IDs of the document’s direct children.
- BEG_ATTACH – Name of the first page of the first attachment document in the current “parent-child” group. Empty if there are no attachments in the current group. Used for emails only.
- END_ATTACH – Name of the last page of the last attachment document in the current “parent-child” group. Empty if there are no attachments in the current group. Used for emails only.
- HAS_EXTRACTED_OR_OCRED_TEXT - “True” if the item has any extracted or OCRed text, “False” otherwise.
- RAW_DATA_FIELD - one of the raw data fields. Use the “Value” option to specify the name of the raw data field.
- DUPLICATE_LOCATIONS – The locations of all duplicate items in the case, excluding the item itself.
- ALL_LOCATIONS – The locations of all duplicate items in the case, including the item itself.
- DUPLICATE_CUSTODIANS – The custodians of all duplicate items in the case, excluding the item itself.
- ALL_CUSTODIANS – The custodians of all duplicate items in the case, including the item itself.
When exporting to a load file, all documents are grouped by their parent-child relationship. For example, an email and its attachments form a single group. The columns “RECORD_ID_GROUP_BEGIN” and “RECORD_ID_GROUP_END” denote the start and end page numbers of such a group.
When adding a date column as a custom field, it is possible to choose the way how the date is formatted: show date only, show time only or show full date and time. Note that you can add the same date field more than once and use different formatting options. For example, you can add two custom fields: DATE_SENT (“Sent” column, show date only) and TIME_SENT (“Sent” column, show time only).
Click the “Select default fields” button to select only those fields that are part of the default field set for the selected load file format.
14.2.13. Redacted items¶
This wizard sheet controls how Redacted items are to be handled when they are part of the set of items to export. The options available depend on the chosen export format.
When exporting to Original format or PDF:
- When the option “Use redacted images when available” is selected, any redacted item will be exported in its redacted form.
Note that for Original format export a PDF will then be generated, rather than the item being exported in its original file format.
When exporting to Original format, PST or i2 iBase/ANB:
- When the option “Suppress redacted items” is selected, then any redacted item will be skipped.
When exporting to Load file or Relativity:
- When the option “Use redacted images when available” is selected, then the image will be exported in its redacted form.
- When the option “Suppress natives for redacted items” is selected, then exporting of the native file will be skipped when the item has been redacted.
- When the option “Suppress text for redacted items” is selected, then exporting of the extracted text will be skipped when the item has been redacted. The text can optionally be replaced with the specified placeholder text.
14.2.14. Creating a report¶
You can indicate whether you want to create an export report for this export. The report can be formatted as a PDF, RTF, CSV and/or HTML file.
For PDF, RTF and HTML reports you can also add a comment that will be displayed on the first page of the report.
Export reports link the original files to the exported files, by listing identifying information about the original item (e.g. source evidence file, MD5 hash) and linking to the exported file. Also the export report may contain information that is lost during export, such as the evidence file’s last modification date; like any copy, the export file has the date of export as its last modification date.
Note
You can find the error notifications at the end of the PDF and RTF report or in the last column of the CSV report.
14.2.15. Skipped items¶
Not all items are inherently exportable to the chosen export format(s). Examples are:
- A file inside an encrypted ZIP file may be known to Intella Connect but it cannot be exported to Original Format if Intella could not decrypt the ZIP file. Exporting to PDF is possible though, with the information that is known.
- When using the default PST export settings, Intella Connect will try to replace nonexportable items with their parent email. If there is no parent email, the item is skipped.
- Folder results are always skipped.
Note
All skipped items are listed in the export report.
14.3. Exporting to a CSV file¶
You can export results to a comma separated value (CSV) file. A CSV file contains all information listed in the table. CSV files can be opened in a spreadsheet application such as Microsoft Excel and can be processed through scripting, which opens up new analytical abilities. This functionality can also be used to generate MD5 lists.
To export results to a CSV file:
- Right click on the results view and click “Export table as CSV…”.
- Mark the names of all columns that you want to include in the CSV file.
- Use the “Include raw data fields” option to include arbitrary raw data fields. A comma separated list, such as PR_MESSAGE_CLASS, PR_MESSAGE_FLAGS, can be used to include more than one field.
- Press
Export.
The contents of the Senders and Receivers columns are configurable to show either the contact name(s), the email address(es), or both.
Columns with dates can be configured to contain time zone always, only when it is from different source or never.
The maximum text length of a value inside a cell can optionally be trimmed to 32,000 characters. This is often necessary when one wants to open the CSV file in MS Excel. When opening a CSV with longer texts in Excel, these long texts are typically broken up and roll over to the next row, breaking the table structure.
By default Intella uses the comma character to separate cells and uses a double quote character to escape values containing commas or other special characters. Those can be changed using the Column delimiter, Quote character and Escape character drop-down boxes.
Note
The CSV format is not a formal standard; different applications may have different conventions on how to separate cells and escape special characters. Intella Connect uses the comma character to separate cells and uses a double quote character to escape values containing commas or other special characters.
Note
To import such files in MS Excel 2010, select Data > From Text in the ribbon. Next, select the file with the file chooser. In the wizard that opens next, choose “Delimited”. Set the Delimiters option to “Comma” and set the Text Qualifier to the ” character. Click Finish.
14.4. Exporting queries¶
The number of hits per search query can be exported by right-clicking in the Searches list in the upper-right corner and selecting “Export queries as…” CSV/XLS. This produces a CSV/XLS file with the following columns:
- Facet – e.g. Type or Keyword Search.
- Result – The textual representation of the search, e.g. the entered search terms or selected facet values.
- Total Count – The total number of items that matched this query.